 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRed-Teaming Vision-Language-Action Models via Quality Diversity Prompt Generation for Robust Robot Policies
Mar 12, 2026Vision-Language-Action (VLA) models have significant potential to enable general-purpose robotic systems for a range of vision-language tasks. However, the performance of VLA-based robots is highly sensitive to the precise wording of language instructions, and it remains difficult to predict when such robots will fail. To improve the robustness of VLAs to different wordings, we present Q-DIG (Quality Diversity for Diverse Instruction Generation), which performs red-teaming by scalably identifying diverse natural language task descriptions that induce failures while remaining task-relevant. Q-DIG integrates Quality Diversity (QD) techniques with Vision-Language Models (VLMs) to generate a broad spectrum of adversarial instructions that expose meaningful vulnerabilities in VLA behavior. Our results across multiple simulation benchmarks show that Q-DIG finds more diverse and meaningful failure modes compared to baseline methods, and that fine-tuning VLAs on the generated instructions improves task success rates. Furthermore, results from a user study highlight that Q-DIG generates prompts judged to be more natural and human-like than those from baselines. Finally, real-world evaluations of Q-DIG prompts show results consistent with simulation, and fine-tuning VLAs on the generated prompts further success rates on unseen instructions. Together, these findings suggest that Q-DIG is a promising approach for identifying vulnerabilities and improving the robustness of VLA-based robots. Our anonymous project website is at qdigvla.github.io.
Improving through Interaction: Searching Behavioral Representation Spaces with CMA-ES-IG
Mar 09, 2026Robots that interact with humans must adapt to individual users' preferences to operate effectively in human-centered environments. An intuitive and effective technique to learn non-expert users' preferences is through rankings of robot behaviors, e.g., trajectories, gestures, or voices. Existing techniques primarily focus on generating queries that optimize preference learning outcomes, such as sample efficiency or final preference estimation accuracy. However, the focus on outcome overlooks key user expectations in the process of providing these rankings, which can negatively impact users' adoption of robotic systems. This work proposes the Covariance Matrix Adaptation Evolution Strategies with Information Gain (CMA-ES-IG) algorithm. CMA-ES-IG explicitly incorporates user experience considerations into the preference learning process by suggesting perceptually distinct and informative trajectories for users to rank. We demonstrate these benefits through both simulated studies and real-robot experiments. CMA-ES-IG, compared to state-of-the-art alternatives, (1) scales more effectively to higher-dimensional preference spaces, (2) maintains computational tractability for high-dimensional problems, (3) is robust to noisy or inconsistent user feedback, and (4) is preferred by non-expert users in identifying their preferred robot behaviors. This project's code is available at github.com/interaction-lab/CMA-ES-IG
Discount Model Search for Quality Diversity Optimization in High-Dimensional Measure Spaces
Jan 03, 2026Quality diversity (QD) optimization searches for a collection of solutions that optimize an objective while attaining diverse outputs of a user-specified, vector-valued measure function. Contemporary QD algorithms focus on low-dimensional measures because high-dimensional measures are prone to distortion, where many solutions found by the QD algorithm map to similar measures. For example, the CMA-MAE algorithm guides measure space exploration with a histogram in measure space that records so-called discount values. However, CMA-MAE stagnates in domains with high-dimensional measure spaces because solutions with similar measures fall into the same histogram cell and thus receive identical discount values. To address these limitations, we propose Discount Model Search (DMS), which guides exploration with a model that provides a smooth, continuous representation of discount values. In high-dimensional measure spaces, this model enables DMS to distinguish between solutions with similar measures and thus continue exploration. We show that DMS facilitates new QD applications by introducing two domains where the measure space is the high-dimensional space of images, which enables users to specify their desired measures by providing a dataset of images rather than hand-designing the measure function. Results in these domains and on high-dimensional benchmarks show that DMS outperforms CMA-MAE and other black-box QD algorithms.
Adaptively Coordinating with Novel Partners via Learned Latent Strategies
Nov 16, 2025Adaptation is the cornerstone of effective collaboration among heterogeneous team members. In human-agent teams, artificial agents need to adapt to their human partners in real time, as individuals often have unique preferences and policies that may change dynamically throughout interactions. This becomes particularly challenging in tasks with time pressure and complex strategic spaces, where identifying partner behaviors and selecting suitable responses is difficult. In this work, we introduce a strategy-conditioned cooperator framework that learns to represent, categorize, and adapt to a broad range of potential partner strategies in real-time. Our approach encodes strategies with a variational autoencoder to learn a latent strategy space from agent trajectory data, identifies distinct strategy types through clustering, and trains a cooperator agent conditioned on these clusters by generating partners of each strategy type. For online adaptation to novel partners, we leverage a fixed-share regret minimization algorithm that dynamically infers and adjusts the partner's strategy estimation during interaction. We evaluate our method in a modified version of the Overcooked domain, a complex collaborative cooking environment that requires effective coordination among two players with a diverse potential strategy space. Through these experiments and an online user study, we demonstrate that our proposed agent achieves state of the art performance compared to existing baselines when paired with novel human, and agent teammates.
AutoQD: Automatic Discovery of Diverse Behaviors with Quality-Diversity Optimization
Jun 05, 2025Quality-Diversity (QD) algorithms have shown remarkable success in discovering diverse, high-performing solutions, but rely heavily on hand-crafted behavioral descriptors that constrain exploration to predefined notions of diversity. Leveraging the equivalence between policies and occupancy measures, we present a theoretically grounded approach to automatically generate behavioral descriptors by embedding the occupancy measures of policies in Markov Decision Processes. Our method, AutoQD, leverages random Fourier features to approximate the Maximum Mean Discrepancy (MMD) between policy occupancy measures, creating embeddings whose distances reflect meaningful behavioral differences. A low-dimensional projection of these embeddings that captures the most behaviorally significant dimensions is then used as behavioral descriptors for off-the-shelf QD methods. We prove that our embeddings converge to true MMD distances between occupancy measures as the number of sampled trajectories and embedding dimensions increase. Through experiments in multiple continuous control tasks we demonstrate AutoQD's ability in discovering diverse policies without predefined behavioral descriptors, presenting a well-motivated alternative to prior methods in unsupervised Reinforcement Learning and QD optimization. Our approach opens new possibilities for open-ended learning and automated behavior discovery in sequential decision making settings without requiring domain-specific knowledge.
Multi-Objective Covariance Matrix Adaptation MAP-Annealing
May 27, 2025Quality-Diversity (QD) optimization is an emerging field that focuses on finding a set of behaviorally diverse and high-quality solutions. While the quality is typically defined w.r.t. a single objective function, recent work on Multi-Objective Quality-Diversity (MOQD) extends QD optimization to simultaneously optimize multiple objective functions. This opens up multi-objective applications for QD, such as generating a diverse set of game maps that maximize difficulty, realism, or other properties. Existing MOQD algorithms use non-adaptive methods such as mutation and crossover to search for non-dominated solutions and construct an archive of Pareto Sets (PS). However, recent work in QD has demonstrated enhanced performance through the use of covariance-based evolution strategies for adaptive solution search. We propose bringing this insight into the MOQD problem, and introduce MO-CMA-MAE, a new MOQD algorithm that leverages Covariance Matrix Adaptation-Evolution Strategies (CMA-ES) to optimize the hypervolume associated with every PS within the archive. We test MO-CMA-MAE on three MOQD domains, and for generating maps of a co-operative video game, showing significant improvements in performance.
Integrating Field of View in Human-Aware Collaborative Planning
May 20, 2025In human-robot collaboration (HRC), it is crucial for robot agents to consider humans' knowledge of their surroundings. In reality, humans possess a narrow field of view (FOV), limiting their perception. However, research on HRC often overlooks this aspect and presumes an omniscient human collaborator. Our study addresses the challenge of adapting to the evolving subtask intent of humans while accounting for their limited FOV. We integrate FOV within the human-aware probabilistic planning framework. To account for large state spaces due to considering FOV, we propose a hierarchical online planner that efficiently finds approximate solutions while enabling the robot to explore low-level action trajectories that enter the human FOV, influencing their intended subtask. Through user study with our adapted cooking domain, we demonstrate our FOV-aware planner reduces human's interruptions and redundant actions during collaboration by adapting to human perception limitations. We extend these findings to a virtual reality kitchen environment, where we observe similar collaborative behaviors.
ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
May 14, 2025Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding. See our website at: https://manipbench.github.io.
Modeling Personalized Difficulty of Rehabilitation Exercises Using Causal Trees
May 07, 2025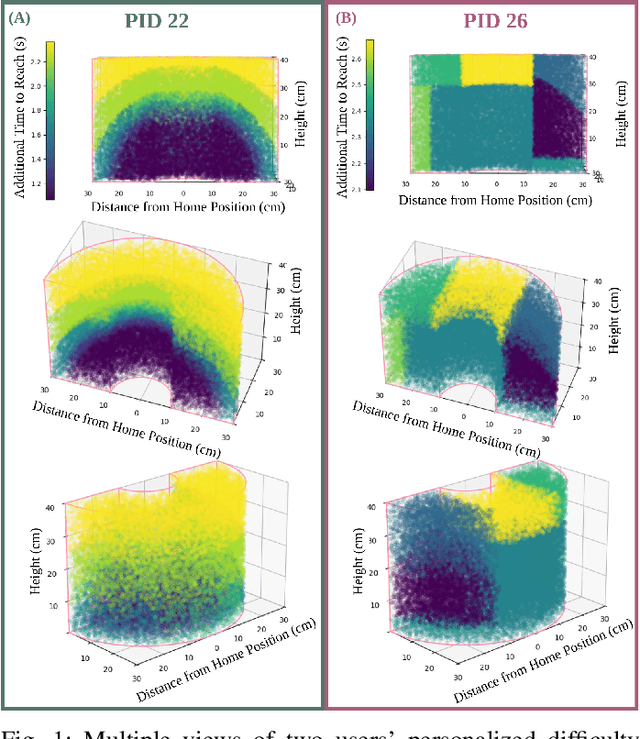

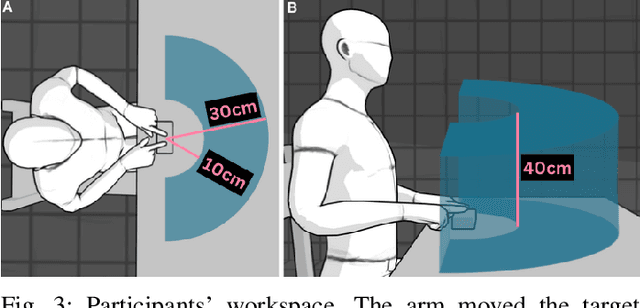
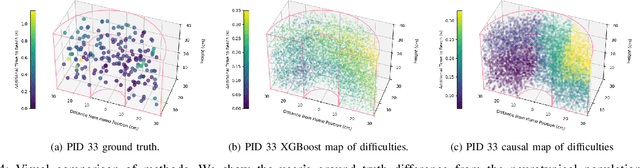
Rehabilitation robots are often used in game-like interactions for rehabilitation to increase a person's motivation to complete rehabilitation exercises. By adjusting exercise difficulty for a specific user throughout the exercise interaction, robots can maximize both the user's rehabilitation outcomes and the their motivation throughout the exercise. Previous approaches have assumed exercises have generic difficulty values that apply to all users equally, however, we identified that stroke survivors have varied and unique perceptions of exercise difficulty. For example, some stroke survivors found reaching vertically more difficult than reaching farther but lower while others found reaching farther more challenging than reaching vertically. In this paper, we formulate a causal tree-based method to calculate exercise difficulty based on the user's performance. We find that this approach accurately models exercise difficulty and provides a readily interpretable model of why that exercise is difficult for both users and caretakers.
Algorithmic Prompt Generation for Diverse Human-like Teaming and Communication with Large Language Models
Apr 04, 2025



Understanding how humans collaborate and communicate in teams is essential for improving human-agent teaming and AI-assisted decision-making. However, relying solely on data from large-scale user studies is impractical due to logistical, ethical, and practical constraints, necessitating synthetic models of multiple diverse human behaviors. Recently, agents powered by Large Language Models (LLMs) have been shown to emulate human-like behavior in social settings. But, obtaining a large set of diverse behaviors requires manual effort in the form of designing prompts. On the other hand, Quality Diversity (QD) optimization has been shown to be capable of generating diverse Reinforcement Learning (RL) agent behavior. In this work, we combine QD optimization with LLM-powered agents to iteratively search for prompts that generate diverse team behavior in a long-horizon, multi-step collaborative environment. We first show, through a human-subjects experiment (n=54 participants), that humans exhibit diverse coordination and communication behavior in this domain. We then show that our approach can effectively replicate trends from human teaming data and also capture behaviors that are not easily observed without collecting large amounts of data. Our findings highlight the combination of QD and LLM-powered agents as an effective tool for studying teaming and communication strategies in multi-agent collaboration.