 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOFlow: Injecting Object-Aware Temporal Flow Matching for Robust Robotic Manipulation
Apr 20, 2026Robust robotic manipulation requires not only predicting how the scene evolves over time, but also recognizing task-relevant objects in complex scenes. However, existing VLA models face two limitations. They typically act only on the current frame, while future prediction and object-aware reasoning are often learned in separate latent spaces. We propose OFlow (injecting Object-Aware Temporal Flow Matching into VLAs), a framework that addresses both limitations by unifying temporal foresight and object-aware reasoning in a shared semantic latent space. Our method forecasts future latents with temporal flow matching, factorizes them into object-aware representations that emphasize physically relevant cues while filtering task-irrelevant variation, and conditions continuous action generation on these predictions. By integrating OFlow into VLA pipelines, our method enables more reliable control under distribution shifts. Extensive experiments across LIBERO, LIBERO-Plus, MetaWorld, and SimplerEnv benchmarks and real-world tasks demonstrate that object-aware foresight consistently enhances robustness and success.
ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
May 14, 2025Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding. See our website at: https://manipbench.github.io.
Sequential Multi-Object Grasping with One Dexterous Hand
Mar 12, 2025
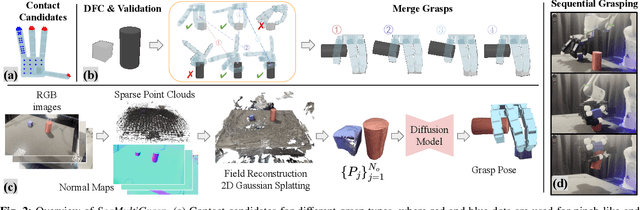

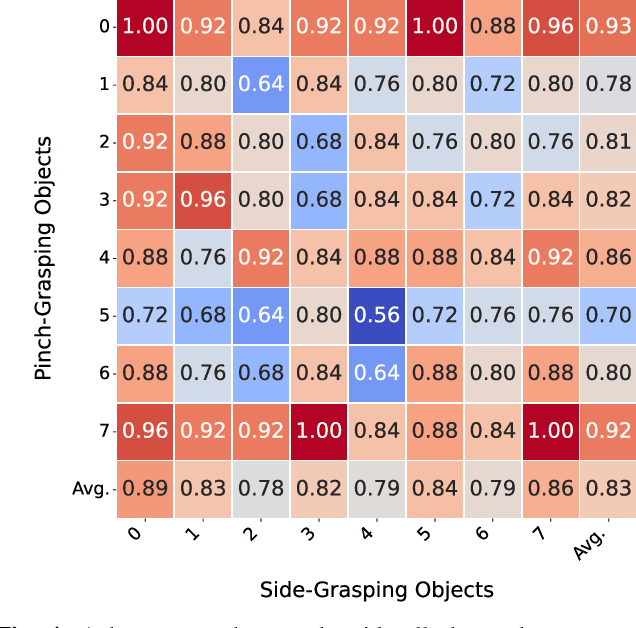
Sequentially grasping multiple objects with multi-fingered hands is common in daily life, where humans can fully leverage the dexterity of their hands to enclose multiple objects. However, the diversity of object geometries and the complex contact interactions required for high-DOF hands to grasp one object while enclosing another make sequential multi-object grasping challenging for robots. In this paper, we propose SeqMultiGrasp, a system for sequentially grasping objects with a four-fingered Allegro Hand. We focus on sequentially grasping two objects, ensuring that the hand fully encloses one object before lifting it and then grasps the second object without dropping the first. Our system first synthesizes single-object grasp candidates, where each grasp is constrained to use only a subset of the hand's links. These grasps are then validated in a physics simulator to ensure stability and feasibility. Next, we merge the validated single-object grasp poses to construct multi-object grasp configurations. For real-world deployment, we train a diffusion model conditioned on point clouds to propose grasp poses, followed by a heuristic-based execution strategy. We test our system using $8 \times 8$ object combinations in simulation and $6 \times 3$ object combinations in real. Our diffusion-based grasp model obtains an average success rate of 65.8% over 1600 simulation trials and 56.7% over 90 real-world trials, suggesting that it is a promising approach for sequential multi-object grasping with multi-fingered hands. Supplementary material is available on our project website: https://hesic73.github.io/SeqMultiGrasp.
Cross-domain Few-shot Object Detection with Multi-modal Textual Enrichment
Feb 23, 2025
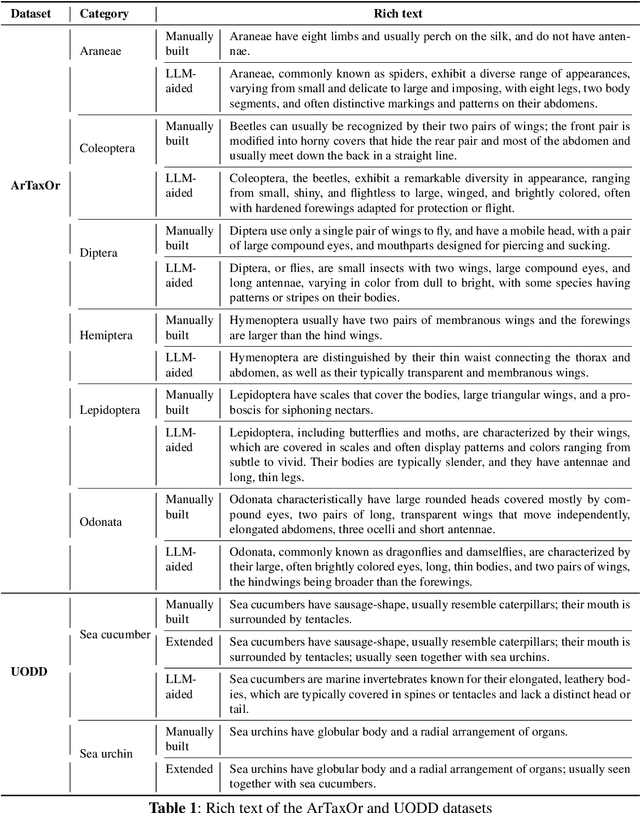
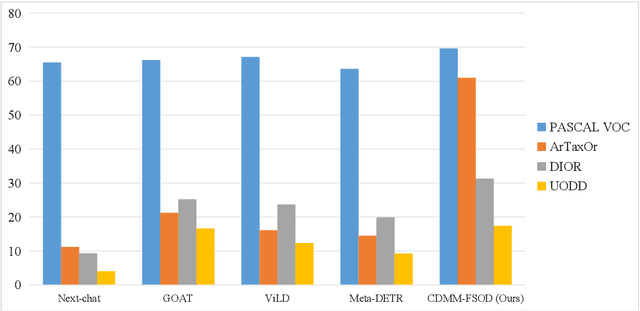
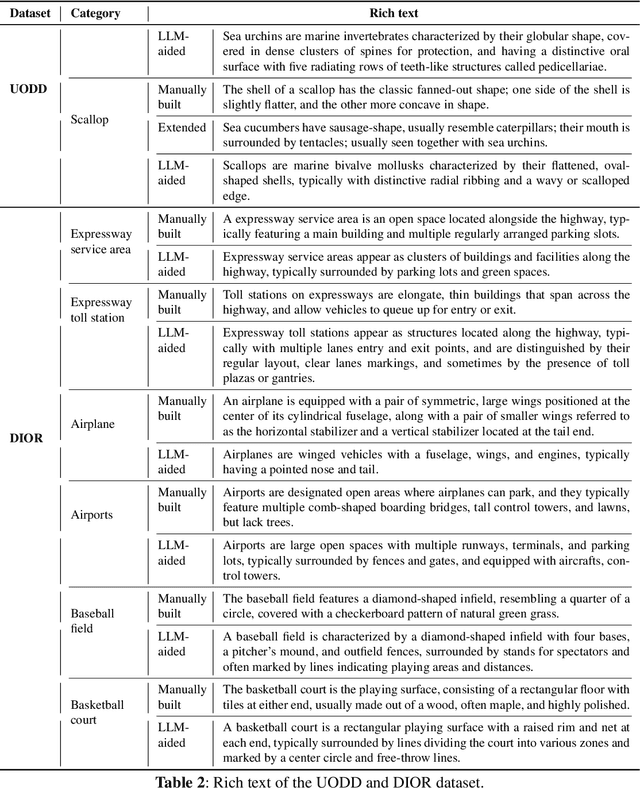
Advancements in cross-modal feature extraction and integration have significantly enhanced performance in few-shot learning tasks. However, current multi-modal object detection (MM-OD) methods often experience notable performance degradation when encountering substantial domain shifts. We propose that incorporating rich textual information can enable the model to establish a more robust knowledge relationship between visual instances and their corresponding language descriptions, thereby mitigating the challenges of domain shift. Specifically, we focus on the problem of Cross-Domain Multi-Modal Few-Shot Object Detection (CDMM-FSOD) and introduce a meta-learning-based framework designed to leverage rich textual semantics as an auxiliary modality to achieve effective domain adaptation. Our new architecture incorporates two key components: (i) A multi-modal feature aggregation module, which aligns visual and linguistic feature embeddings to ensure cohesive integration across modalities. (ii) A rich text semantic rectification module, which employs bidirectional text feature generation to refine multi-modal feature alignment, thereby enhancing understanding of language and its application in object detection. We evaluate the proposed method on common cross-domain object detection benchmarks and demonstrate that it significantly surpasses existing few-shot object detection approaches.
Online Pseudo-Label Unified Object Detection for Multiple Datasets Training
Oct 21, 2024



The Unified Object Detection (UOD) task aims to achieve object detection of all merged categories through training on multiple datasets, and is of great significance in comprehensive object detection scenarios. In this paper, we conduct a thorough analysis of the cross datasets missing annotations issue, and propose an Online Pseudo-Label Unified Object Detection scheme. Our method uses a periodically updated teacher model to generate pseudo-labels for the unlabelled objects in each sub-dataset. This periodical update strategy could better ensure that the accuracy of the teacher model reaches the local maxima and maximized the quality of pseudo-labels. In addition, we survey the influence of overlapped region proposals on the accuracy of box regression. We propose a category specific box regression and a pseudo-label RPN head to improve the recall rate of the Region Proposal Network (PRN). Our experimental results on common used benchmarks (\eg COCO, Object365 and OpenImages) indicates that our online pseudo-label UOD method achieves higher accuracy than existing SOTA methods.
Cross-domain Multi-modal Few-shot Object Detection via Rich Text
Mar 24, 2024



Cross-modal feature extraction and integration have led to steady performance improvements in few-shot learning tasks due to generating richer features. However, existing multi-modal object detection (MM-OD) methods degrade when facing significant domain-shift and are sample insufficient. We hypothesize that rich text information could more effectively help the model to build a knowledge relationship between the vision instance and its language description and can help mitigate domain shift. Specifically, we study the Cross-Domain few-shot generalization of MM-OD (CDMM-FSOD) and propose a meta-learning based multi-modal few-shot object detection method that utilizes rich text semantic information as an auxiliary modality to achieve domain adaptation in the context of FSOD. Our proposed network contains (i) a multi-modal feature aggregation module that aligns the vision and language support feature embeddings and (ii) a rich text semantic rectify module that utilizes bidirectional text feature generation to reinforce multi-modal feature alignment and thus to enhance the model's language understanding capability. We evaluate our model on common standard cross-domain object detection datasets and demonstrate that our approach considerably outperforms existing FSOD methods.
Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
Feb 05, 2024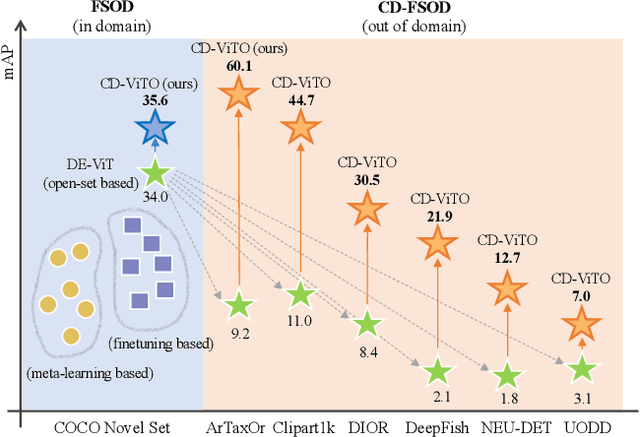

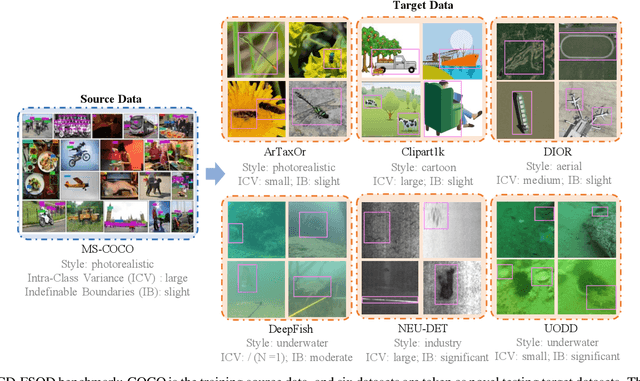

This paper addresses the challenge of cross-domain few-shot object detection (CD-FSOD), aiming to develop an accurate object detector for novel domains with minimal labeled examples. While transformer-based open-set detectors e.g., DE-ViT~\cite{zhang2023detect} have excelled in both open-vocabulary object detection and traditional few-shot object detection, detecting categories beyond those seen during training, we thus naturally raise two key questions: 1) can such open-set detection methods easily generalize to CD-FSOD? 2) If no, how to enhance the results of open-set methods when faced with significant domain gaps? To address the first question, we introduce several metrics to quantify domain variances and establish a new CD-FSOD benchmark with diverse domain metric values. Some State-Of-The-Art (SOTA) open-set object detection methods are evaluated on this benchmark, with evident performance degradation observed across out-of-domain datasets. This indicates the failure of adopting open-set detectors directly for CD-FSOD. Sequentially, to overcome the performance degradation issue and also to answer the second proposed question, we endeavor to enhance the vanilla DE-ViT. With several novel components including finetuning, a learnable prototype module, and a lightweight attention module, we present an improved Cross-Domain Vision Transformer for CD-FSOD (CD-ViTO). Experiments show that our CD-ViTO achieves impressive results on both out-of-domain and in-domain target datasets, establishing new SOTAs for both CD-FSOD and FSOD. All the datasets, codes, and models will be released to the community.
Decoupled DETR For Few-shot Object Detection
Nov 20, 2023Few-shot object detection (FSOD), an efficient method for addressing the severe data-hungry problem, has been extensively discussed. Current works have significantly advanced the problem in terms of model and data. However, the overall performance of most FSOD methods still does not fulfill the desired accuracy. In this paper we improve the FSOD model to address the severe issue of sample imbalance and weak feature propagation. To alleviate modeling bias from data-sufficient base classes, we examine the effect of decoupling the parameters for classes with sufficient data and classes with few samples in various ways. We design a base-novel categories decoupled DETR (DeDETR) for FSOD. We also explore various types of skip connection between the encoder and decoder for DETR. Besides, we notice that the best outputs could come from the intermediate layer of the decoder instead of the last layer; therefore, we build a unified decoder module that could dynamically fuse the decoder layers as the output feature. We evaluate our model on commonly used datasets such as PASCAL VOC and MSCOCO. Our results indicate that our proposed module could achieve stable improvements of 5% to 10% in both fine-tuning and meta-learning paradigms and has outperformed the highest score in recent works.
Improved Region Proposal Network for Enhanced Few-Shot Object Detection
Aug 15, 2023



Despite significant success of deep learning in object detection tasks, the standard training of deep neural networks requires access to a substantial quantity of annotated images across all classes. Data annotation is an arduous and time-consuming endeavor, particularly when dealing with infrequent objects. Few-shot object detection (FSOD) methods have emerged as a solution to the limitations of classic object detection approaches based on deep learning. FSOD methods demonstrate remarkable performance by achieving robust object detection using a significantly smaller amount of training data. A challenge for FSOD is that instances from novel classes that do not belong to the fixed set of training classes appear in the background and the base model may pick them up as potential objects. These objects behave similarly to label noise because they are classified as one of the training dataset classes, leading to FSOD performance degradation. We develop a semi-supervised algorithm to detect and then utilize these unlabeled novel objects as positive samples during the FSOD training stage to improve FSOD performance. Specifically, we develop a hierarchical ternary classification region proposal network (HTRPN) to localize the potential unlabeled novel objects and assign them new objectness labels to distinguish these objects from the base training dataset classes. Our improved hierarchical sampling strategy for the region proposal network (RPN) also boosts the perception ability of the object detection model for large objects. We test our approach and COCO and PASCAL VOC baselines that are commonly used in FSOD literature. Our experimental results indicate that our method is effective and outperforms the existing state-of-the-art (SOTA) FSOD methods. Our implementation is provided as a supplement to support reproducibility of the results.
Identification of Novel Classes for Improving Few-Shot Object Detection
Mar 18, 2023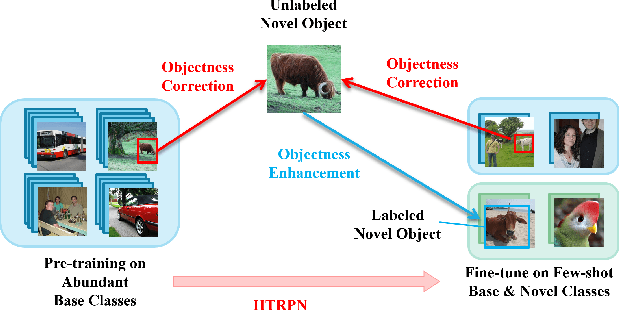
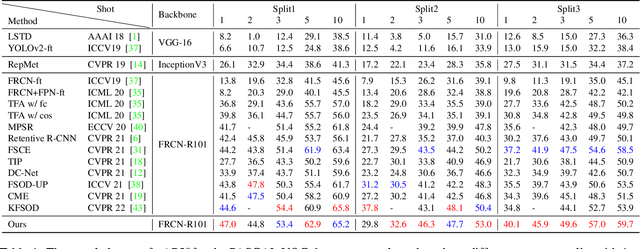

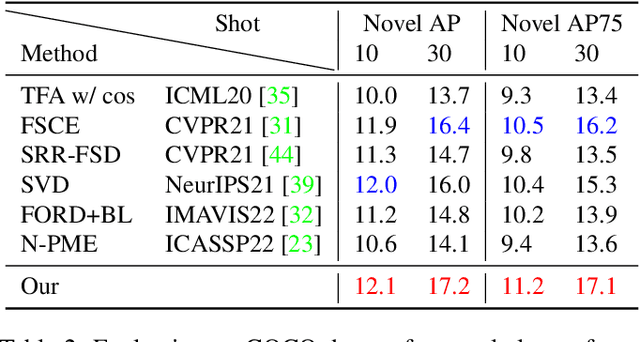
Conventional training of deep neural networks requires a large number of the annotated image which is a laborious and time-consuming task, particularly for rare objects. Few-shot object detection (FSOD) methods offer a remedy by realizing robust object detection using only a few training samples per class. An unexplored challenge for FSOD is that instances from unlabeled novel classes that do not belong to the fixed set of training classes appear in the background. These objects behave similarly to label noise, leading to FSOD performance degradation. We develop a semi-supervised algorithm to detect and then utilize these unlabeled novel objects as positive samples during training to improve FSOD performance. Specifically, we propose a hierarchical ternary classification region proposal network (HTRPN) to localize the potential unlabeled novel objects and assign them new objectness labels. Our improved hierarchical sampling strategy for the region proposal network (RPN) also boosts the perception ability of the object detection model for large objects. Our experimental results indicate that our method is effective and outperforms the existing state-of-the-art (SOTA) FSOD methods.