 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeFA-Policy: Fast and Accurate Visuomotor Policy Learning with Selective Flow Alignment
Nov 11, 2025Developing efficient and accurate visuomotor policies poses a central challenge in robotic imitation learning. While recent rectified flow approaches have advanced visuomotor policy learning, they suffer from a key limitation: After iterative distillation, generated actions may deviate from the ground-truth actions corresponding to the current visual observation, leading to accumulated error as the reflow process repeats and unstable task execution. We present Selective Flow Alignment (SeFA), an efficient and accurate visuomotor policy learning framework. SeFA resolves this challenge by a selective flow alignment strategy, which leverages expert demonstrations to selectively correct generated actions and restore consistency with observations, while preserving multimodality. This design introduces a consistency correction mechanism that ensures generated actions remain observation-aligned without sacrificing the efficiency of one-step flow inference. Extensive experiments across both simulated and real-world manipulation tasks show that SeFA Policy surpasses state-of-the-art diffusion-based and flow-based policies, achieving superior accuracy and robustness while reducing inference latency by over 98%. By unifying rectified flow efficiency with observation-consistent action generation, SeFA provides a scalable and dependable solution for real-time visuomotor policy learning. Code is available on https://github.com/RongXueZoe/SeFA.
Robot Learning from a Physical World Model
Nov 10, 2025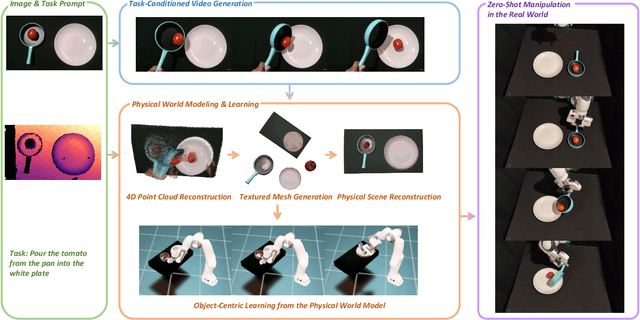

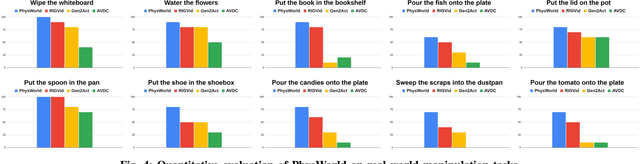

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
Learning an Implicit Physics Model for Image-based Fluid Simulation
Aug 11, 2025Humans possess an exceptional ability to imagine 4D scenes, encompassing both motion and 3D geometry, from a single still image. This ability is rooted in our accumulated observations of similar scenes and an intuitive understanding of physics. In this paper, we aim to replicate this capacity in neural networks, specifically focusing on natural fluid imagery. Existing methods for this task typically employ simplistic 2D motion estimators to animate the image, leading to motion predictions that often defy physical principles, resulting in unrealistic animations. Our approach introduces a novel method for generating 4D scenes with physics-consistent animation from a single image. We propose the use of a physics-informed neural network that predicts motion for each surface point, guided by a loss term derived from fundamental physical principles, including the Navier-Stokes equations. To capture appearance, we predict feature-based 3D Gaussians from the input image and its estimated depth, which are then animated using the predicted motions and rendered from any desired camera perspective. Experimental results highlight the effectiveness of our method in producing physically plausible animations, showcasing significant performance improvements over existing methods. Our project page is https://physfluid.github.io/ .
ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
May 14, 2025Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding. See our website at: https://manipbench.github.io.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025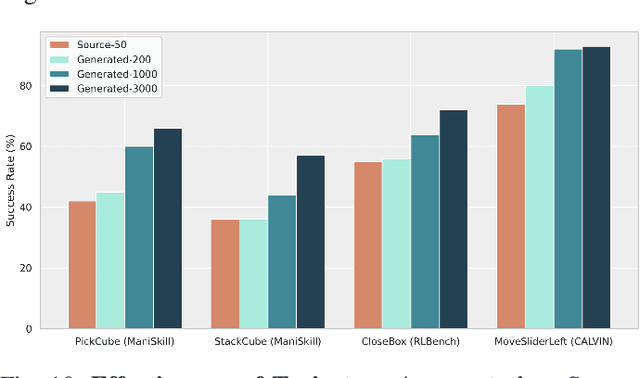



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding
Jan 29, 2025Understanding the physical world is a fundamental challenge in embodied AI, critical for enabling agents to perform complex tasks and operate safely in real-world environments. While Vision-Language Models (VLMs) have shown great promise in reasoning and task planning for embodied agents, their ability to comprehend physical phenomena remains extremely limited. To close this gap, we introduce PhysBench, a comprehensive benchmark designed to evaluate VLMs' physical world understanding capability across a diverse set of tasks. PhysBench contains 10,002 entries of interleaved video-image-text data, categorized into four major domains: physical object properties, physical object relationships, physical scene understanding, and physics-based dynamics, further divided into 19 subclasses and 8 distinct capability dimensions. Our extensive experiments, conducted on 75 representative VLMs, reveal that while these models excel in common-sense reasoning, they struggle with understanding the physical world -- likely due to the absence of physical knowledge in their training data and the lack of embedded physical priors. To tackle the shortfall, we introduce PhysAgent, a novel framework that combines the generalization strengths of VLMs with the specialized expertise of vision models, significantly enhancing VLMs' physical understanding across a variety of tasks, including an 18.4\% improvement on GPT-4o. Furthermore, our results demonstrate that enhancing VLMs' physical world understanding capabilities can help embodied agents such as MOKA. We believe that PhysBench and PhysAgent offer valuable insights and contribute to bridging the gap between VLMs and physical world understanding.
DreamDrive: Generative 4D Scene Modeling from Street View Images
Jan 03, 2025



Synthesizing photo-realistic visual observations from an ego vehicle's driving trajectory is a critical step towards scalable training of self-driving models. Reconstruction-based methods create 3D scenes from driving logs and synthesize geometry-consistent driving videos through neural rendering, but their dependence on costly object annotations limits their ability to generalize to in-the-wild driving scenarios. On the other hand, generative models can synthesize action-conditioned driving videos in a more generalizable way but often struggle with maintaining 3D visual consistency. In this paper, we present DreamDrive, a 4D spatial-temporal scene generation approach that combines the merits of generation and reconstruction, to synthesize generalizable 4D driving scenes and dynamic driving videos with 3D consistency. Specifically, we leverage the generative power of video diffusion models to synthesize a sequence of visual references and further elevate them to 4D with a novel hybrid Gaussian representation. Given a driving trajectory, we then render 3D-consistent driving videos via Gaussian splatting. The use of generative priors allows our method to produce high-quality 4D scenes from in-the-wild driving data, while neural rendering ensures 3D-consistent video generation from the 4D scenes. Extensive experiments on nuScenes and street view images demonstrate that DreamDrive can generate controllable and generalizable 4D driving scenes, synthesize novel views of driving videos with high fidelity and 3D consistency, decompose static and dynamic elements in a self-supervised manner, and enhance perception and planning tasks for autonomous driving.
Learning from Massive Human Videos for Universal Humanoid Pose Control
Dec 18, 2024



Scalable learning of humanoid robots is crucial for their deployment in real-world applications. While traditional approaches primarily rely on reinforcement learning or teleoperation to achieve whole-body control, they are often limited by the diversity of simulated environments and the high costs of demonstration collection. In contrast, human videos are ubiquitous and present an untapped source of semantic and motion information that could significantly enhance the generalization capabilities of humanoid robots. This paper introduces Humanoid-X, a large-scale dataset of over 20 million humanoid robot poses with corresponding text-based motion descriptions, designed to leverage this abundant data. Humanoid-X is curated through a comprehensive pipeline: data mining from the Internet, video caption generation, motion retargeting of humans to humanoid robots, and policy learning for real-world deployment. With Humanoid-X, we further train a large humanoid model, UH-1, which takes text instructions as input and outputs corresponding actions to control a humanoid robot. Extensive simulated and real-world experiments validate that our scalable training approach leads to superior generalization in text-based humanoid control, marking a significant step toward adaptable, real-world-ready humanoid robots.
RAM: Retrieval-Based Affordance Transfer for Generalizable Zero-Shot Robotic Manipulation
Jul 05, 2024



This work proposes a retrieve-and-transfer framework for zero-shot robotic manipulation, dubbed RAM, featuring generalizability across various objects, environments, and embodiments. Unlike existing approaches that learn manipulation from expensive in-domain demonstrations, RAM capitalizes on a retrieval-based affordance transfer paradigm to acquire versatile manipulation capabilities from abundant out-of-domain data. First, RAM extracts unified affordance at scale from diverse sources of demonstrations including robotic data, human-object interaction (HOI) data, and custom data to construct a comprehensive affordance memory. Then given a language instruction, RAM hierarchically retrieves the most similar demonstration from the affordance memory and transfers such out-of-domain 2D affordance to in-domain 3D executable affordance in a zero-shot and embodiment-agnostic manner. Extensive simulation and real-world evaluations demonstrate that our RAM consistently outperforms existing works in diverse daily tasks. Additionally, RAM shows significant potential for downstream applications such as automatic and efficient data collection, one-shot visual imitation, and LLM/VLM-integrated long-horizon manipulation. For more details, please check our website at https://yxkryptonite.github.io/RAM/.
DeTra: A Unified Model for Object Detection and Trajectory Forecasting
Jun 06, 2024The tasks of object detection and trajectory forecasting play a crucial role in understanding the scene for autonomous driving. These tasks are typically executed in a cascading manner, making them prone to compounding errors. Furthermore, there is usually a very thin interface between the two tasks, creating a lossy information bottleneck. To address these challenges, our approach formulates the union of the two tasks as a trajectory refinement problem, where the first pose is the detection (current time), and the subsequent poses are the waypoints of the multiple forecasts (future time). To tackle this unified task, we design a refinement transformer that infers the presence, pose, and multi-modal future behaviors of objects directly from LiDAR point clouds and high-definition maps. We call this model DeTra, short for object Detection and Trajectory forecasting. In our experiments, we observe that \ourmodel{} outperforms the state-of-the-art on Argoverse 2 Sensor and Waymo Open Dataset by a large margin, across a broad range of metrics. Last but not least, we perform extensive ablation studies that show the value of refinement for this task, that every proposed component contributes positively to its performance, and that key design choices were made.