 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDex4D: Task-Agnostic Point Track Policy for Sim-to-Real Dexterous Manipulation
Feb 17, 2026Learning generalist policies capable of accomplishing a plethora of everyday tasks remains an open challenge in dexterous manipulation. In particular, collecting large-scale manipulation data via real-world teleoperation is expensive and difficult to scale. While learning in simulation provides a feasible alternative, designing multiple task-specific environments and rewards for training is similarly challenging. We propose Dex4D, a framework that instead leverages simulation for learning task-agnostic dexterous skills that can be flexibly recomposed to perform diverse real-world manipulation tasks. Specifically, Dex4D learns a domain-agnostic 3D point track conditioned policy capable of manipulating any object to any desired pose. We train this 'Anypose-to-Anypose' policy in simulation across thousands of objects with diverse pose configurations, covering a broad space of robot-object interactions that can be composed at test time. At deployment, this policy can be zero-shot transferred to real-world tasks without finetuning, simply by prompting it with desired object-centric point tracks extracted from generated videos. During execution, Dex4D uses online point tracking for closed-loop perception and control. Extensive experiments in simulation and on real robots show that our method enables zero-shot deployment for diverse dexterous manipulation tasks and yields consistent improvements over prior baselines. Furthermore, we demonstrate strong generalization to novel objects, scene layouts, backgrounds, and trajectories, highlighting the robustness and scalability of the proposed framework.
SkillBlender: Towards Versatile Humanoid Whole-Body Loco-Manipulation via Skill Blending
Jun 11, 2025Humanoid robots hold significant potential in accomplishing daily tasks across diverse environments thanks to their flexibility and human-like morphology. Recent works have made significant progress in humanoid whole-body control and loco-manipulation leveraging optimal control or reinforcement learning. However, these methods require tedious task-specific tuning for each task to achieve satisfactory behaviors, limiting their versatility and scalability to diverse tasks in daily scenarios. To that end, we introduce SkillBlender, a novel hierarchical reinforcement learning framework for versatile humanoid loco-manipulation. SkillBlender first pretrains goal-conditioned task-agnostic primitive skills, and then dynamically blends these skills to accomplish complex loco-manipulation tasks with minimal task-specific reward engineering. We also introduce SkillBench, a parallel, cross-embodiment, and diverse simulated benchmark containing three embodiments, four primitive skills, and eight challenging loco-manipulation tasks, accompanied by a set of scientific evaluation metrics balancing accuracy and feasibility. Extensive simulated experiments show that our method significantly outperforms all baselines, while naturally regularizing behaviors to avoid reward hacking, resulting in more accurate and feasible movements for diverse loco-manipulation tasks in our daily scenarios. Our code and benchmark will be open-sourced to the community to facilitate future research. Project page: https://usc-gvl.github.io/SkillBlender-web/.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025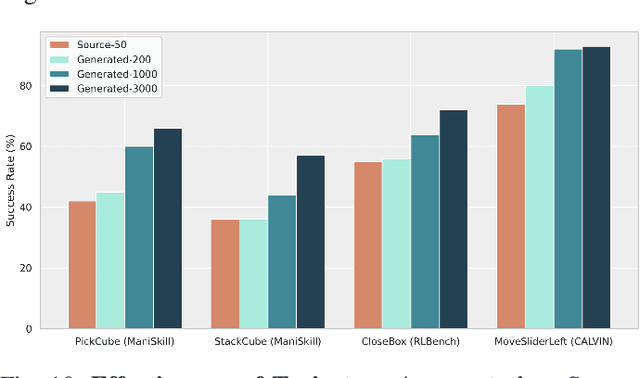



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
A0: An Affordance-Aware Hierarchical Model for General Robotic Manipulation
Apr 21, 2025



Robotic manipulation faces critical challenges in understanding spatial affordances--the "where" and "how" of object interactions--essential for complex manipulation tasks like wiping a board or stacking objects. Existing methods, including modular-based and end-to-end approaches, often lack robust spatial reasoning capabilities. Unlike recent point-based and flow-based affordance methods that focus on dense spatial representations or trajectory modeling, we propose A0, a hierarchical affordance-aware diffusion model that decomposes manipulation tasks into high-level spatial affordance understanding and low-level action execution. A0 leverages the Embodiment-Agnostic Affordance Representation, which captures object-centric spatial affordances by predicting contact points and post-contact trajectories. A0 is pre-trained on 1 million contact points data and fine-tuned on annotated trajectories, enabling generalization across platforms. Key components include Position Offset Attention for motion-aware feature extraction and a Spatial Information Aggregation Layer for precise coordinate mapping. The model's output is executed by the action execution module. Experiments on multiple robotic systems (Franka, Kinova, Realman, and Dobot) demonstrate A0's superior performance in complex tasks, showcasing its efficiency, flexibility, and real-world applicability.
FetchBot: Object Fetching in Cluttered Shelves via Zero-Shot Sim2Real
Feb 25, 2025

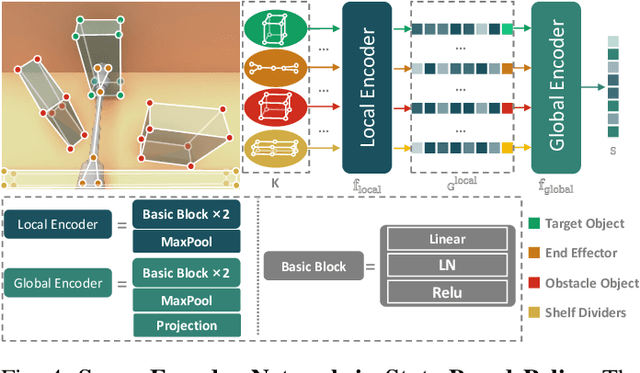
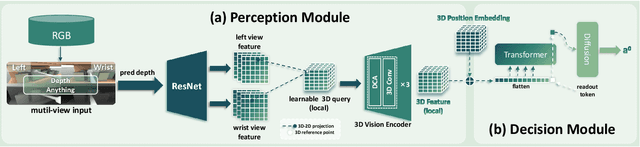
Object fetching from cluttered shelves is an important capability for robots to assist humans in real-world scenarios. Achieving this task demands robotic behaviors that prioritize safety by minimizing disturbances to surrounding objects, an essential but highly challenging requirement due to restricted motion space, limited fields of view, and complex object dynamics. In this paper, we introduce FetchBot, a sim-to-real framework designed to enable zero-shot generalizable and safety-aware object fetching from cluttered shelves in real-world settings. To address data scarcity, we propose an efficient voxel-based method for generating diverse simulated cluttered shelf scenes at scale and train a dynamics-aware reinforcement learning (RL) policy to generate object fetching trajectories within these scenes. This RL policy, which leverages oracle information, is subsequently distilled into a vision-based policy for real-world deployment. Considering that sim-to-real discrepancies stem from texture variations mostly while from geometric dimensions rarely, we propose to adopt depth information estimated by full-fledged depth foundation models as the input for the vision-based policy to mitigate sim-to-real gap. To tackle the challenge of limited views, we design a novel architecture for learning multi-view representations, allowing for comprehensive encoding of cluttered shelf scenes. This enables FetchBot to effectively minimize collisions while fetching objects from varying positions and depths, ensuring robust and safety-aware operation. Both simulation and real-robot experiments demonstrate FetchBot's superior generalization ability, particularly in handling a broad range of real-world scenarios, includ
RAM: Retrieval-Based Affordance Transfer for Generalizable Zero-Shot Robotic Manipulation
Jul 05, 2024



This work proposes a retrieve-and-transfer framework for zero-shot robotic manipulation, dubbed RAM, featuring generalizability across various objects, environments, and embodiments. Unlike existing approaches that learn manipulation from expensive in-domain demonstrations, RAM capitalizes on a retrieval-based affordance transfer paradigm to acquire versatile manipulation capabilities from abundant out-of-domain data. First, RAM extracts unified affordance at scale from diverse sources of demonstrations including robotic data, human-object interaction (HOI) data, and custom data to construct a comprehensive affordance memory. Then given a language instruction, RAM hierarchically retrieves the most similar demonstration from the affordance memory and transfers such out-of-domain 2D affordance to in-domain 3D executable affordance in a zero-shot and embodiment-agnostic manner. Extensive simulation and real-world evaluations demonstrate that our RAM consistently outperforms existing works in diverse daily tasks. Additionally, RAM shows significant potential for downstream applications such as automatic and efficient data collection, one-shot visual imitation, and LLM/VLM-integrated long-horizon manipulation. For more details, please check our website at https://yxkryptonite.github.io/RAM/.
OpenFMNav: Towards Open-Set Zero-Shot Object Navigation via Vision-Language Foundation Models
Feb 16, 2024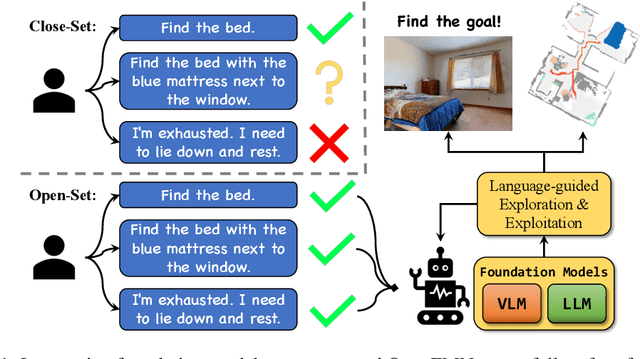

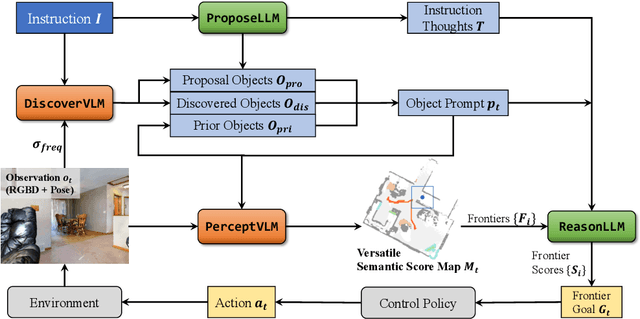

Object navigation (ObjectNav) requires an agent to navigate through unseen environments to find queried objects. Many previous methods attempted to solve this task by relying on supervised or reinforcement learning, where they are trained on limited household datasets with close-set objects. However, two key challenges are unsolved: understanding free-form natural language instructions that demand open-set objects, and generalizing to new environments in a zero-shot manner. Aiming to solve the two challenges, in this paper, we propose OpenFMNav, an Open-set Foundation Model based framework for zero-shot object Navigation. We first unleash the reasoning abilities of large language models (LLMs) to extract proposed objects from natural language instructions that meet the user's demand. We then leverage the generalizability of large vision language models (VLMs) to actively discover and detect candidate objects from the scene, building a Versatile Semantic Score Map (VSSM). Then, by conducting common sense reasoning on VSSM, our method can perform effective language-guided exploration and exploitation of the scene and finally reach the goal. By leveraging the reasoning and generalizing abilities of foundation models, our method can understand free-form human instructions and perform effective open-set zero-shot navigation in diverse environments. Extensive experiments on the HM3D ObjectNav benchmark show that our method surpasses all the strong baselines on all metrics, proving our method's effectiveness. Furthermore, we perform real robot demonstrations to validate our method's open-set-ness and generalizability to real-world environments.
STOPNet: Multiview-based 6-DoF Suction Detection for Transparent Objects on Production Lines
Oct 09, 2023



In this work, we present STOPNet, a framework for 6-DoF object suction detection on production lines, with a focus on but not limited to transparent objects, which is an important and challenging problem in robotic systems and modern industry. Current methods requiring depth input fail on transparent objects due to depth cameras' deficiency in sensing their geometry, while we proposed a novel framework to reconstruct the scene on the production line depending only on RGB input, based on multiview stereo. Compared to existing works, our method not only reconstructs the whole 3D scene in order to obtain high-quality 6-DoF suction poses in real time but also generalizes to novel environments, novel arrangements and novel objects, including challenging transparent objects, both in simulation and the real world. Extensive experiments in simulation and the real world show that our method significantly surpasses the baselines and has better generalizability, which caters to practical industrial needs.