 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA1: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
Apr 07, 2026Vision--Language--Action (VLA) models have emerged as a powerful paradigm for open-world robot manipulation, but their practical deployment is often constrained by \emph{cost}: billion-scale VLM backbones and iterative diffusion/flow-based action heads incur high latency and compute, making real-time control expensive on commodity hardware. We present A1, a fully open-source and transparent VLA framework designed for low-cost, high-throughput inference without sacrificing manipulation success; Our approach leverages pretrained VLMs that provide implicit affordance priors for action generation. We release the full training stack (training code, data/data-processing pipeline, intermediate checkpoints, and evaluation scripts) to enable end-to-end reproducibility. Beyond optimizing the VLM alone, A1 targets the full inference pipeline by introducing a budget-aware adaptive inference scheme that jointly accelerates the backbone and the \emph{action head}. Specifically, we monitor action consistency across intermediate VLM layers to trigger early termination, and propose Inter-Layer Truncated Flow Matching that warm-starts denoising across layers, enabling accurate actions with substantially fewer effective denoising iterations. Across simulation benchmarks (LIBERO, VLABench) and real robots (Franka, AgiBot), A1 achieves state-of-the-art success rates while significantly reducing inference cost (e.g., up to 72% lower per-episode latency for flow-matching inference and up to 76.6% backbone computation reduction with minor performance degradation). On RoboChallenge, A1 achieves an average success rate of 29.00%, outperforming baselines including pi0(28.33%), X-VLA (21.33%), and RDT-1B (15.00%).
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025
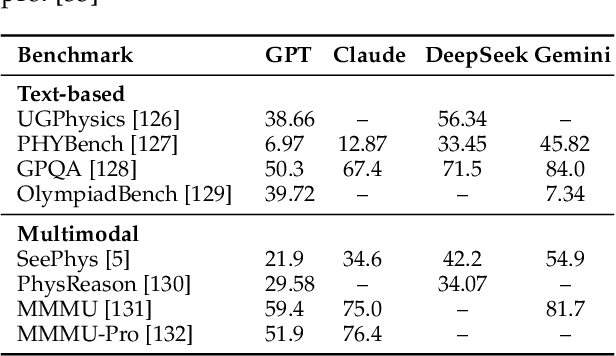

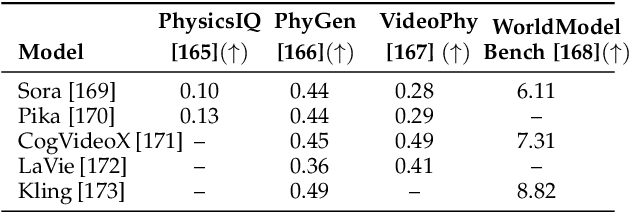
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
A0: An Affordance-Aware Hierarchical Model for General Robotic Manipulation
Apr 21, 2025



Robotic manipulation faces critical challenges in understanding spatial affordances--the "where" and "how" of object interactions--essential for complex manipulation tasks like wiping a board or stacking objects. Existing methods, including modular-based and end-to-end approaches, often lack robust spatial reasoning capabilities. Unlike recent point-based and flow-based affordance methods that focus on dense spatial representations or trajectory modeling, we propose A0, a hierarchical affordance-aware diffusion model that decomposes manipulation tasks into high-level spatial affordance understanding and low-level action execution. A0 leverages the Embodiment-Agnostic Affordance Representation, which captures object-centric spatial affordances by predicting contact points and post-contact trajectories. A0 is pre-trained on 1 million contact points data and fine-tuned on annotated trajectories, enabling generalization across platforms. Key components include Position Offset Attention for motion-aware feature extraction and a Spatial Information Aggregation Layer for precise coordinate mapping. The model's output is executed by the action execution module. Experiments on multiple robotic systems (Franka, Kinova, Realman, and Dobot) demonstrate A0's superior performance in complex tasks, showcasing its efficiency, flexibility, and real-world applicability.
VidMan: Exploiting Implicit Dynamics from Video Diffusion Model for Effective Robot Manipulation
Nov 14, 2024Recent advancements utilizing large-scale video data for learning video generation models demonstrate significant potential in understanding complex physical dynamics. It suggests the feasibility of leveraging diverse robot trajectory data to develop a unified, dynamics-aware model to enhance robot manipulation. However, given the relatively small amount of available robot data, directly fitting data without considering the relationship between visual observations and actions could lead to suboptimal data utilization. To this end, we propose VidMan (Video Diffusion for Robot Manipulation), a novel framework that employs a two-stage training mechanism inspired by dual-process theory from neuroscience to enhance stability and improve data utilization efficiency. Specifically, in the first stage, VidMan is pre-trained on the Open X-Embodiment dataset (OXE) for predicting future visual trajectories in a video denoising diffusion manner, enabling the model to develop a long horizontal awareness of the environment's dynamics. In the second stage, a flexible yet effective layer-wise self-attention adapter is introduced to transform VidMan into an efficient inverse dynamics model that predicts action modulated by the implicit dynamics knowledge via parameter sharing. Our VidMan framework outperforms state-of-the-art baseline model GR-1 on the CALVIN benchmark, achieving a 11.7% relative improvement, and demonstrates over 9% precision gains on the OXE small-scale dataset. These results provide compelling evidence that world models can significantly enhance the precision of robot action prediction. Codes and models will be public.
CapDet: Unifying Dense Captioning and Open-World Detection Pretraining
Mar 15, 2023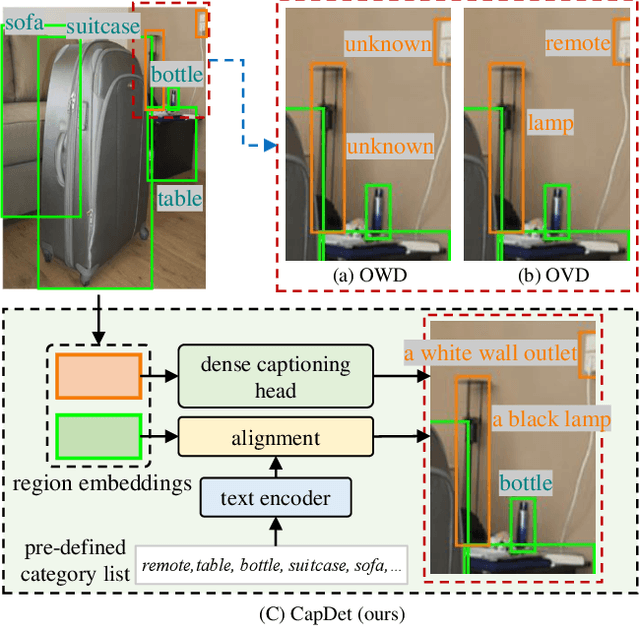

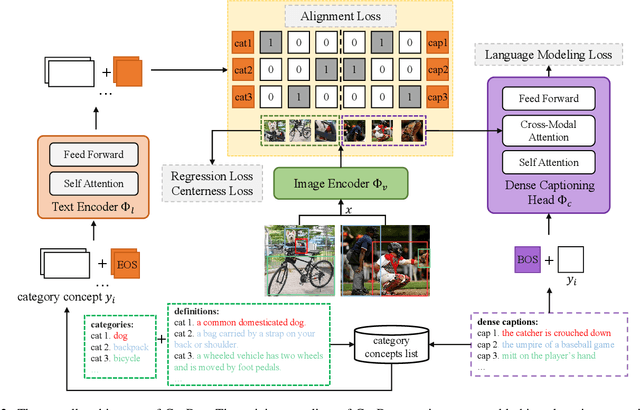

Benefiting from large-scale vision-language pre-training on image-text pairs, open-world detection methods have shown superior generalization ability under the zero-shot or few-shot detection settings. However, a pre-defined category space is still required during the inference stage of existing methods and only the objects belonging to that space will be predicted. To introduce a "real" open-world detector, in this paper, we propose a novel method named CapDet to either predict under a given category list or directly generate the category of predicted bounding boxes. Specifically, we unify the open-world detection and dense caption tasks into a single yet effective framework by introducing an additional dense captioning head to generate the region-grounded captions. Besides, adding the captioning task will in turn benefit the generalization of detection performance since the captioning dataset covers more concepts. Experiment results show that by unifying the dense caption task, our CapDet has obtained significant performance improvements (e.g., +2.1% mAP on LVIS rare classes) over the baseline method on LVIS (1203 classes). Besides, our CapDet also achieves state-of-the-art performance on dense captioning tasks, e.g., 15.44% mAP on VG V1.2 and 13.98% on the VG-COCO dataset.
DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection
Sep 20, 2022
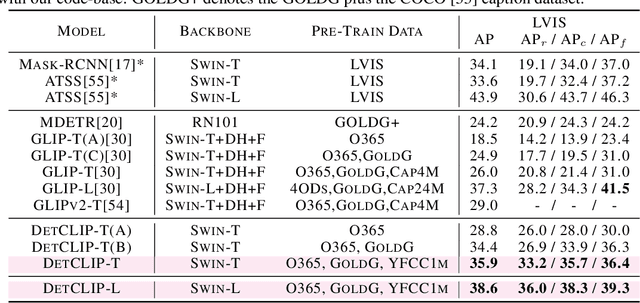

Open-world object detection, as a more general and challenging goal, aims to recognize and localize objects described by arbitrary category names. The recent work GLIP formulates this problem as a grounding problem by concatenating all category names of detection datasets into sentences, which leads to inefficient interaction between category names. This paper presents DetCLIP, a paralleled visual-concept pre-training method for open-world detection by resorting to knowledge enrichment from a designed concept dictionary. To achieve better learning efficiency, we propose a novel paralleled concept formulation that extracts concepts separately to better utilize heterogeneous datasets (i.e., detection, grounding, and image-text pairs) for training. We further design a concept dictionary~(with descriptions) from various online sources and detection datasets to provide prior knowledge for each concept. By enriching the concepts with their descriptions, we explicitly build the relationships among various concepts to facilitate the open-domain learning. The proposed concept dictionary is further used to provide sufficient negative concepts for the construction of the word-region alignment loss\, and to complete labels for objects with missing descriptions in captions of image-text pair data. The proposed framework demonstrates strong zero-shot detection performances, e.g., on the LVIS dataset, our DetCLIP-T outperforms GLIP-T by 9.9% mAP and obtains a 13.5% improvement on rare categories compared to the fully-supervised model with the same backbone as ours.
Open-world Semantic Segmentation via Contrasting and Clustering Vision-Language Embedding
Jul 19, 2022
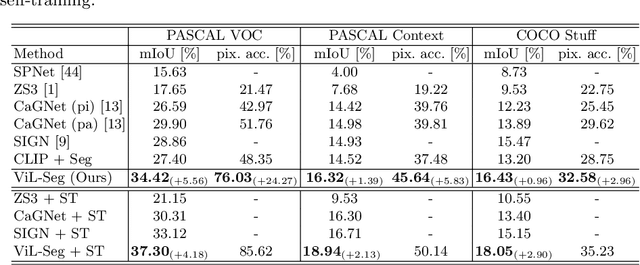
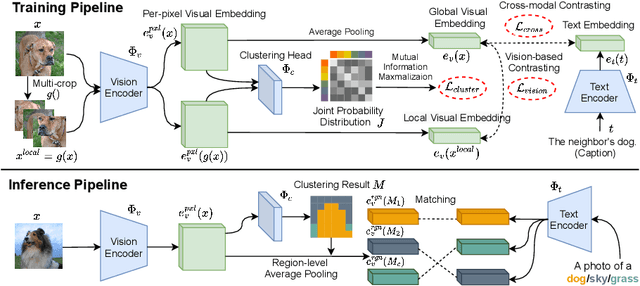
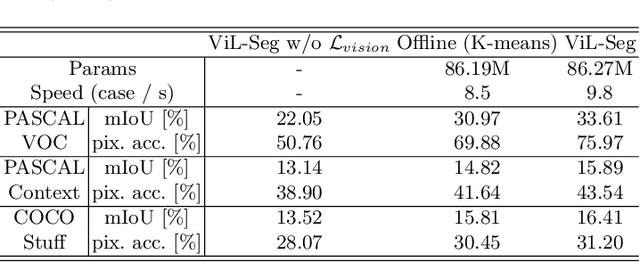
To bridge the gap between supervised semantic segmentation and real-world applications that acquires one model to recognize arbitrary new concepts, recent zero-shot segmentation attracts a lot of attention by exploring the relationships between unseen and seen object categories, yet requiring large amounts of densely-annotated data with diverse base classes. In this paper, we propose a new open-world semantic segmentation pipeline that makes the first attempt to learn to segment semantic objects of various open-world categories without any efforts on dense annotations, by purely exploiting the image-caption data that naturally exist on the Internet. Our method, Vision-language-driven Semantic Segmentation (ViL-Seg), employs an image and a text encoder to generate visual and text embeddings for the image-caption data, with two core components that endow its segmentation ability: First, the image encoder is jointly trained with a vision-based contrasting and a cross-modal contrasting, which encourage the visual embeddings to preserve both fine-grained semantics and high-level category information that are crucial for the segmentation task. Furthermore, an online clustering head is devised over the image encoder, which allows to dynamically segment the visual embeddings into distinct semantic groups such that they can be classified by comparing with various text embeddings to complete our segmentation pipeline. Experiments show that without using any data with dense annotations, our method can directly segment objects of arbitrary categories, outperforming zero-shot segmentation methods that require data labeling on three benchmark datasets.