 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots
Mar 08, 2026Recent advances in Visual-Language-Action (VLA) models have shown promising potential for robotic manipulation tasks. However, real-world robotic tasks often involve long-horizon, multi-step problem-solving and require generalization for continual skill acquisition, extending beyond single actions or skills. These challenges present significant barriers for existing VLA models, which use monolithic action decoders trained on aggregated data, resulting in poor scalability. To address these challenges, we propose AtomicVLA, a unified planning-and-execution framework that jointly generates task-level plans, atomic skill abstractions, and fine-grained actions. AtomicVLA constructs a scalable atomic skill library through a Skill-Guided Mixture-of-Experts (SG-MoE), where each expert specializes in mastering generic yet precise atomic skills. Furthermore, we introduce a flexible routing encoder that automatically assigns dedicated atomic experts to new skills, enabling continual learning. We validate our approach through extensive experiments. In simulation, AtomicVLA outperforms $π_{0}$ by 2.4\% on LIBERO, 10\% on LIBERO-LONG, and outperforms $π_{0}$ and $π_{0.5}$ by 0.22 and 0.25 in average task length on CALVIN. Additionally, our AtomicVLA consistently surpasses baselines by 18.3\% and 21\% in real-world long-horizon tasks and continual learning. These results highlight the effectiveness of atomic skill abstraction and dynamic expert composition for long-horizon and lifelong robotic tasks. The project page is \href{https://zhanglk9.github.io/atomicvla-web/}{here}.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025
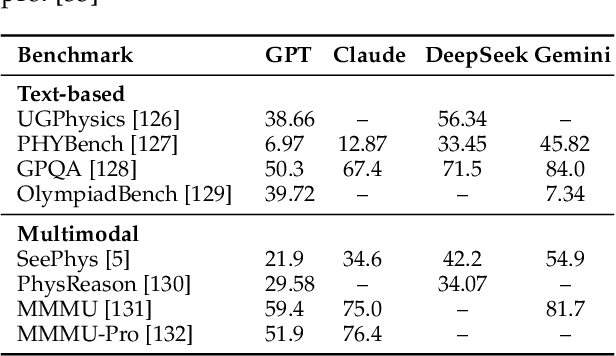

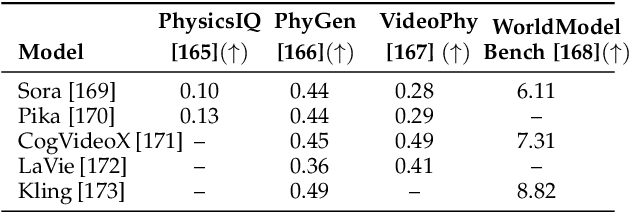
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.
C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025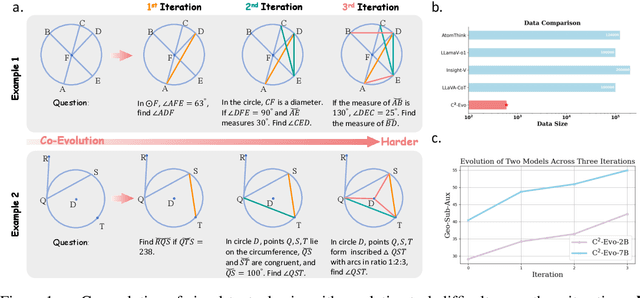

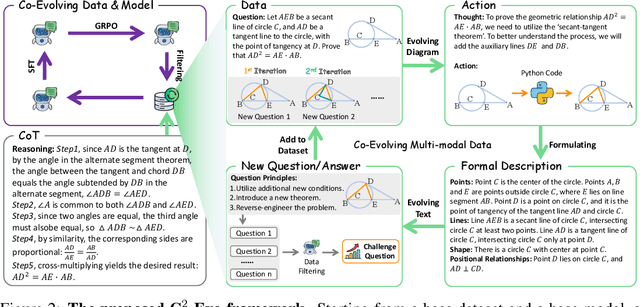
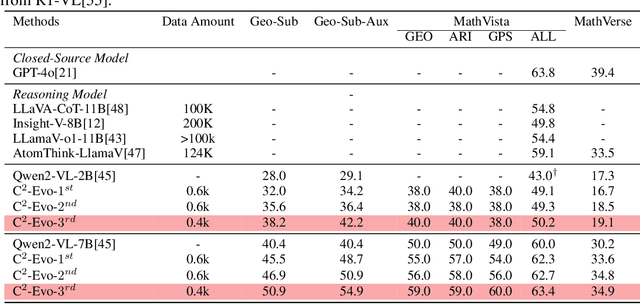
Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
SemHiTok: A Unified Image Tokenizer via Semantic-Guided Hierarchical Codebook for Multimodal Understanding and Generation
Mar 09, 2025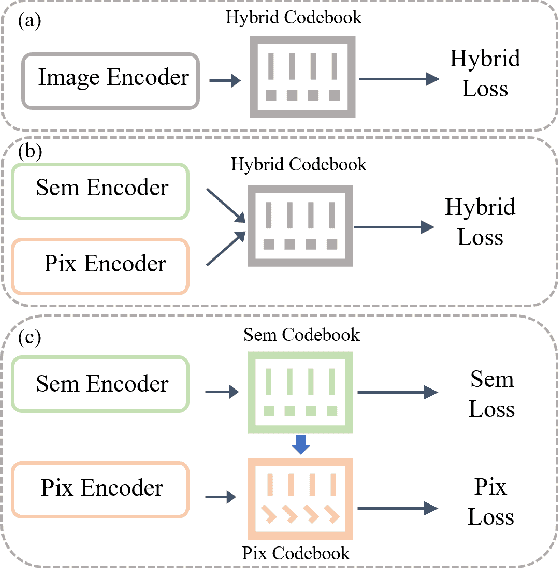
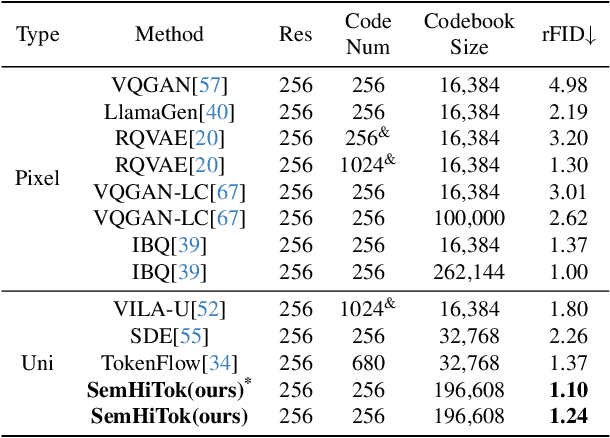
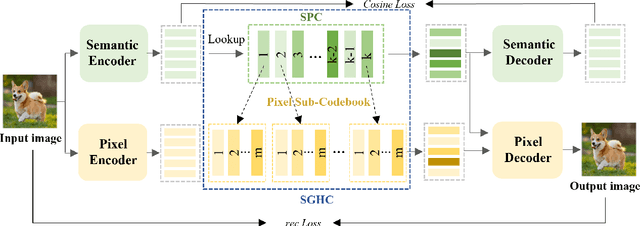
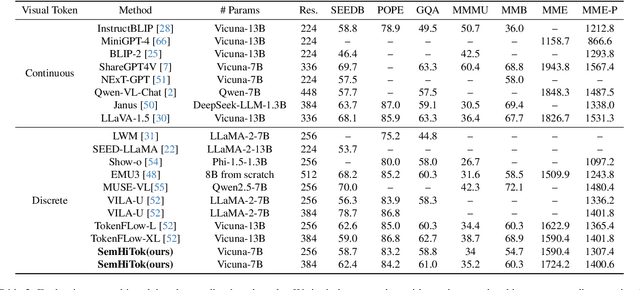
We present SemHiTok, a unified image Tokenizer via Semantic-Guided Hierarchical codebook that provides consistent discrete feature representations for multimodal understanding and generation tasks. Recently, unified multimodal large models (MLLMs) for understanding and generation have sparked exploration within research community. Previous works attempt to train a unified image tokenizer by combining loss functions for semantic feature reconstruction and pixel reconstruction. However, due to the differing levels of features prioritized by multimodal understanding and generation tasks, joint training methods face significant challenges in achieving a good trade-off. SemHiTok addresses this challenge through Semantic-Guided Hierarchical codebook which builds texture sub-codebooks on pre-trained semantic codebook. This design decouples the training of semantic reconstruction and pixel reconstruction and equips the tokenizer with low-level texture feature extraction capability without degradation of high-level semantic feature extraction ability. Our experiments demonstrate that SemHiTok achieves state-of-the-art rFID score at 256X256resolution compared to other unified tokenizers, and exhibits competitive performance on multimodal understanding and generation tasks.
TransMamba: Fast Universal Architecture Adaption from Transformers to Mamba
Feb 21, 2025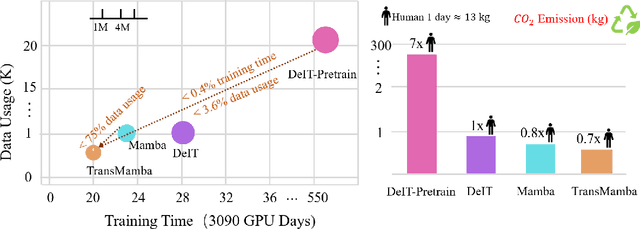
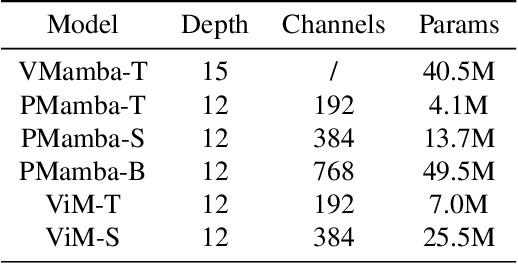
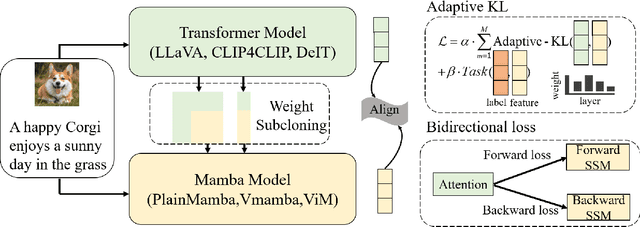
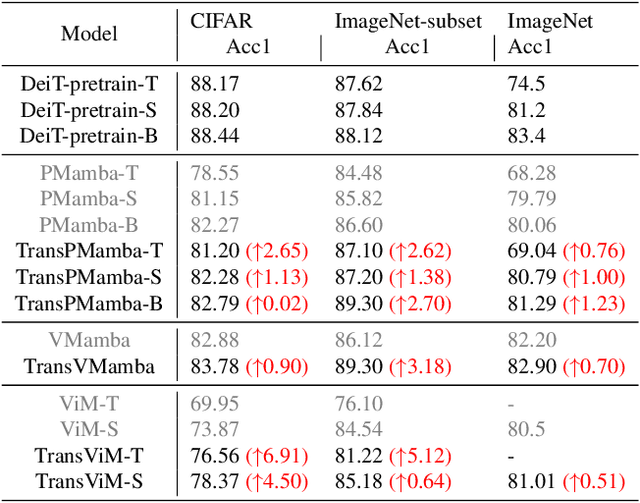
Transformers have been favored in both uni-modal and multi-modal foundation models for their flexible scalability in attention modules. Consequently, a number of pre-trained Transformer models, e.g., LLaVA, CLIP, and DEIT, are publicly available. Recent research has introduced subquadratic architectures like Mamba, which enables global awareness with linear complexity. Nevertheless, training specialized subquadratic architectures from scratch for certain tasks is both resource-intensive and time-consuming. As a motivator, we explore cross-architecture training to transfer the ready knowledge in existing Transformer models to alternative architecture Mamba, termed TransMamba. Our approach employs a two-stage strategy to expedite training new Mamba models, ensuring effectiveness in across uni-modal and cross-modal tasks. Concerning architecture disparities, we project the intermediate features into an aligned latent space before transferring knowledge. On top of that, a Weight Subcloning and Adaptive Bidirectional distillation method (WSAB) is introduced for knowledge transfer without limitations on varying layer counts. For cross-modal learning, we propose a cross-Mamba module that integrates language awareness into Mamba's visual features, enhancing the cross-modal interaction capabilities of Mamba architecture. Despite using less than 75% of the training data typically required for training from scratch, TransMamba boasts substantially stronger performance across various network architectures and downstream tasks, including image classification, visual question answering, and text-video retrieval. The code will be publicly available.
Rotation Augmented Distillation for Exemplar-Free Class Incremental Learning with Detailed Analysis
Aug 29, 2023Class incremental learning (CIL) aims to recognize both the old and new classes along the increment tasks. Deep neural networks in CIL suffer from catastrophic forgetting and some approaches rely on saving exemplars from previous tasks, known as the exemplar-based setting, to alleviate this problem. On the contrary, this paper focuses on the Exemplar-Free setting with no old class sample preserved. Balancing the plasticity and stability in deep feature learning with only supervision from new classes is more challenging. Most existing Exemplar-Free CIL methods report the overall performance only and lack further analysis. In this work, different methods are examined with complementary metrics in greater detail. Moreover, we propose a simple CIL method, Rotation Augmented Distillation (RAD), which achieves one of the top-tier performances under the Exemplar-Free setting. Detailed analysis shows our RAD benefits from the superior balance between plasticity and stability. Finally, more challenging exemplar-free settings with fewer initial classes are undertaken for further demonstrations and comparisons among the state-of-the-art methods.
Dynamic Residual Classifier for Class Incremental Learning
Aug 25, 2023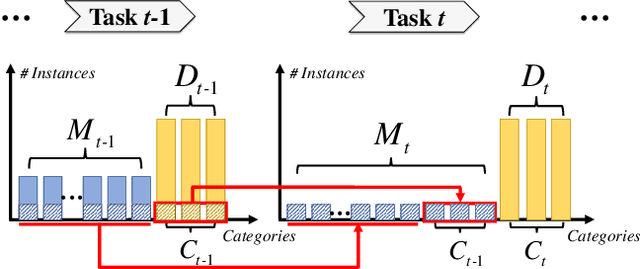
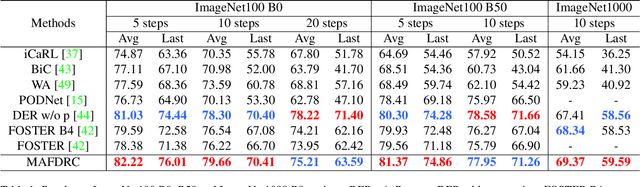
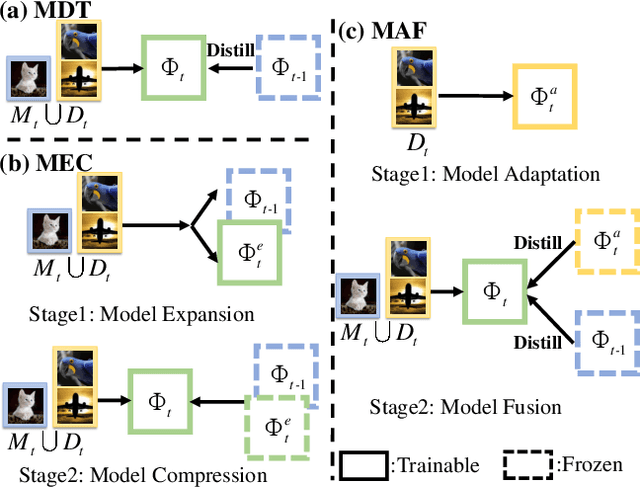
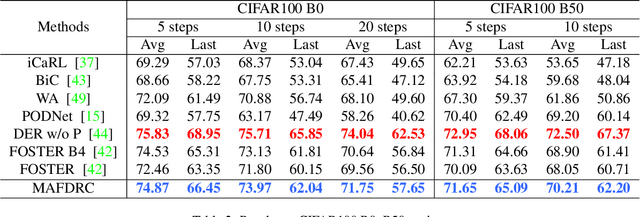
The rehearsal strategy is widely used to alleviate the catastrophic forgetting problem in class incremental learning (CIL) by preserving limited exemplars from previous tasks. With imbalanced sample numbers between old and new classes, the classifier learning can be biased. Existing CIL methods exploit the long-tailed (LT) recognition techniques, e.g., the adjusted losses and the data re-sampling methods, to handle the data imbalance issue within each increment task. In this work, the dynamic nature of data imbalance in CIL is shown and a novel Dynamic Residual Classifier (DRC) is proposed to handle this challenging scenario. Specifically, DRC is built upon a recent advance residual classifier with the branch layer merging to handle the model-growing problem. Moreover, DRC is compatible with different CIL pipelines and substantially improves them. Combining DRC with the model adaptation and fusion (MAF) pipeline, this method achieves state-of-the-art results on both the conventional CIL and the LT-CIL benchmarks. Extensive experiments are also conducted for a detailed analysis. The code is publicly available.