 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Weight Consolidation Done Right for Continual Learning
Mar 19, 2026Weight regularization methods in continual learning (CL) alleviate catastrophic forgetting by assessing and penalizing changes to important model weights. Elastic Weight Consolidation (EWC) is a foundational and widely used approach within this framework that estimates weight importance based on gradients. However, it has consistently shown suboptimal performance. In this paper, we conduct a systematic analysis of importance estimation in EWC from a gradient-based perspective. For the first time, we find that EWC's reliance on the Fisher Information Matrix (FIM) results in gradient vanishing and inaccurate importance estimation in certain scenarios. Our analysis also reveals that Memory Aware Synapses (MAS), a variant of EWC, imposes unnecessary constraints on parameters irrelevant to prior tasks, termed the redundant protection. Consequently, both EWC and its variants exhibit fundamental misalignments in estimating weight importance, leading to inferior performance. To tackle these issues, we propose the Logits Reversal (LR) operation, a simple yet effective modification that rectifies EWC's importance estimation. Specifically, reversing the logit values during the calculation of FIM can effectively prevent both gradient vanishing and redundant protection. Extensive experiments across various CL tasks and datasets show that the proposed method significantly outperforms existing EWC and its variants. Therefore, we refer to it as EWC Done Right (EWC-DR).
* Accepted to CVPR 2026
Consistent Prompting for Rehearsal-Free Continual Learning
Mar 14, 2024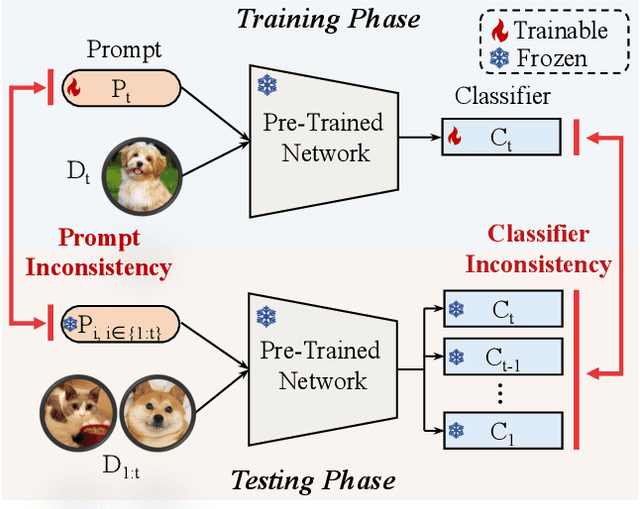
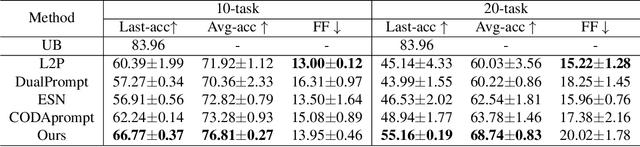
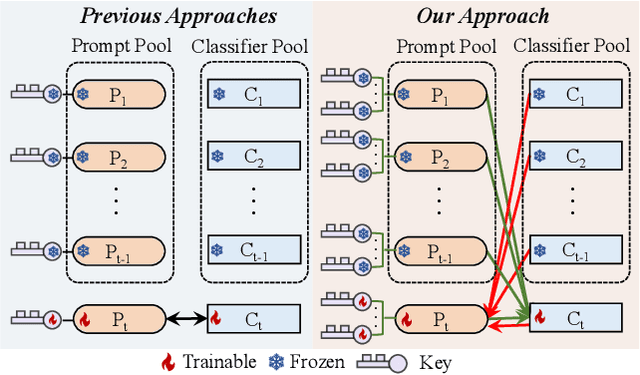
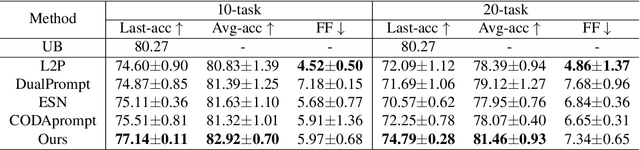
Continual learning empowers models to adapt autonomously to the ever-changing environment or data streams without forgetting old knowledge. Prompt-based approaches are built on frozen pre-trained models to learn the task-specific prompts and classifiers efficiently. Existing prompt-based methods are inconsistent between training and testing, limiting their effectiveness. Two types of inconsistency are revealed. Test predictions are made from all classifiers while training only focuses on the current task classifier without holistic alignment, leading to Classifier inconsistency. Prompt inconsistency indicates that the prompt selected during testing may not correspond to the one associated with this task during training. In this paper, we propose a novel prompt-based method, Consistent Prompting (CPrompt), for more aligned training and testing. Specifically, all existing classifiers are exposed to prompt training, resulting in classifier consistency learning. In addition, prompt consistency learning is proposed to enhance prediction robustness and boost prompt selection accuracy. Our Consistent Prompting surpasses its prompt-based counterparts and achieves state-of-the-art performance on multiple continual learning benchmarks. Detailed analysis shows that improvements come from more consistent training and testing.
Generalizable Two-Branch Framework for Image Class-Incremental Learning
Mar 13, 2024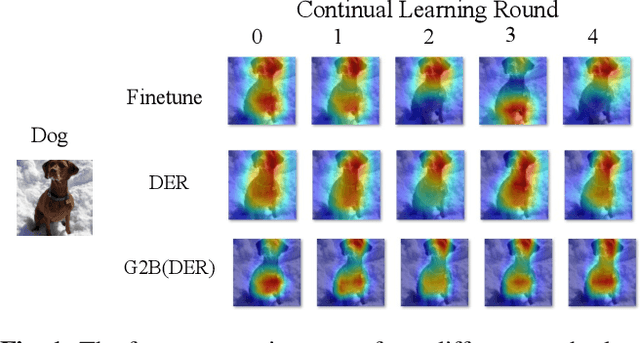
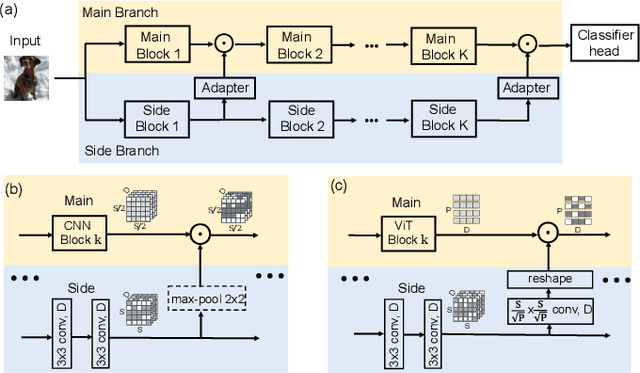
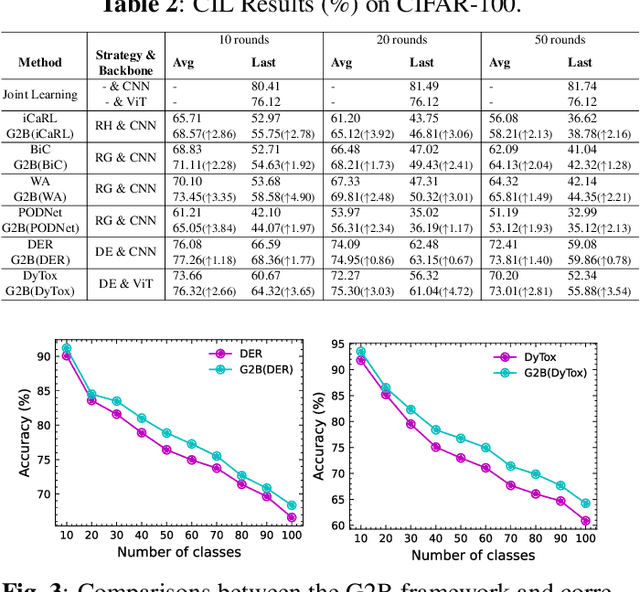
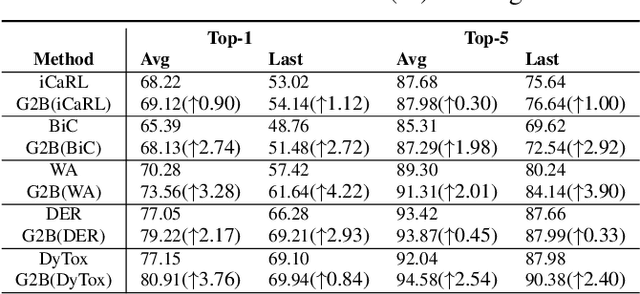
Deep neural networks often severely forget previously learned knowledge when learning new knowledge. Various continual learning (CL) methods have been proposed to handle such a catastrophic forgetting issue from different perspectives and achieved substantial improvements. In this paper, a novel two-branch continual learning framework is proposed to further enhance most existing CL methods. Specifically, the main branch can be any existing CL model and the newly introduced side branch is a lightweight convolutional network. The output of each main branch block is modulated by the output of the corresponding side branch block. Such a simple two-branch model can then be easily implemented and learned with the vanilla optimization setting without whistles and bells. Extensive experiments with various settings on multiple image datasets show that the proposed framework yields consistent improvements over state-of-the-art methods.
Rotation Augmented Distillation for Exemplar-Free Class Incremental Learning with Detailed Analysis
Aug 29, 2023Class incremental learning (CIL) aims to recognize both the old and new classes along the increment tasks. Deep neural networks in CIL suffer from catastrophic forgetting and some approaches rely on saving exemplars from previous tasks, known as the exemplar-based setting, to alleviate this problem. On the contrary, this paper focuses on the Exemplar-Free setting with no old class sample preserved. Balancing the plasticity and stability in deep feature learning with only supervision from new classes is more challenging. Most existing Exemplar-Free CIL methods report the overall performance only and lack further analysis. In this work, different methods are examined with complementary metrics in greater detail. Moreover, we propose a simple CIL method, Rotation Augmented Distillation (RAD), which achieves one of the top-tier performances under the Exemplar-Free setting. Detailed analysis shows our RAD benefits from the superior balance between plasticity and stability. Finally, more challenging exemplar-free settings with fewer initial classes are undertaken for further demonstrations and comparisons among the state-of-the-art methods.
Dynamic Residual Classifier for Class Incremental Learning
Aug 25, 2023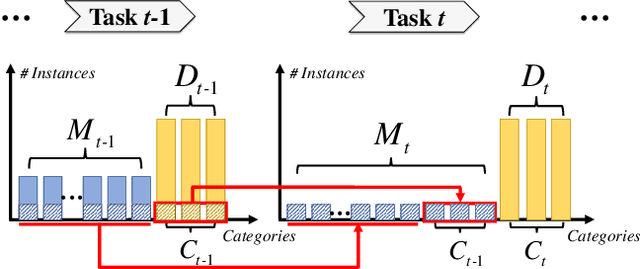
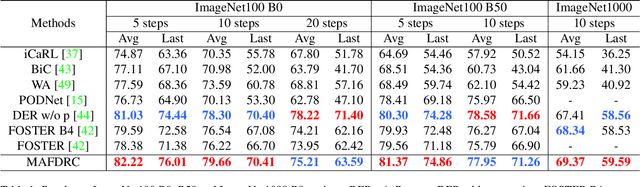
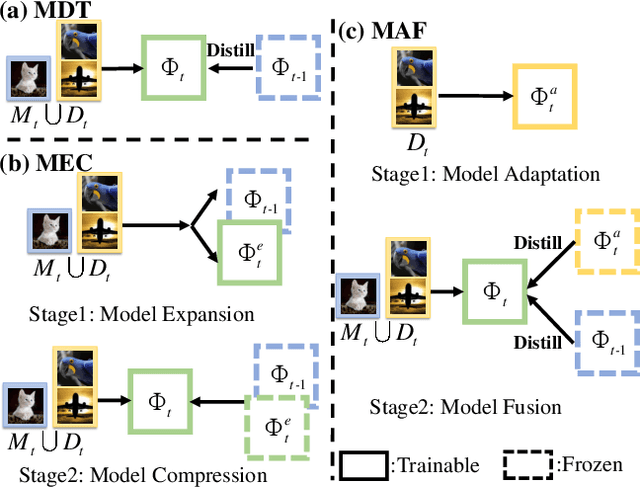
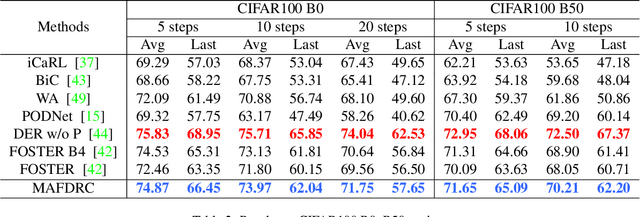
The rehearsal strategy is widely used to alleviate the catastrophic forgetting problem in class incremental learning (CIL) by preserving limited exemplars from previous tasks. With imbalanced sample numbers between old and new classes, the classifier learning can be biased. Existing CIL methods exploit the long-tailed (LT) recognition techniques, e.g., the adjusted losses and the data re-sampling methods, to handle the data imbalance issue within each increment task. In this work, the dynamic nature of data imbalance in CIL is shown and a novel Dynamic Residual Classifier (DRC) is proposed to handle this challenging scenario. Specifically, DRC is built upon a recent advance residual classifier with the branch layer merging to handle the model-growing problem. Moreover, DRC is compatible with different CIL pipelines and substantially improves them. Combining DRC with the model adaptation and fusion (MAF) pipeline, this method achieves state-of-the-art results on both the conventional CIL and the LT-CIL benchmarks. Extensive experiments are also conducted for a detailed analysis. The code is publicly available.
Camera-Conditioned Stable Feature Generation for Isolated Camera Supervised Person Re-IDentification
Apr 04, 2022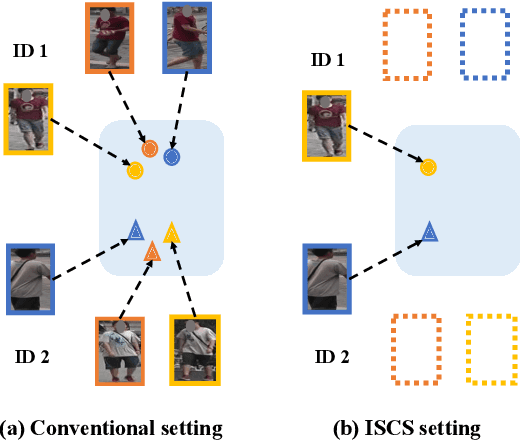
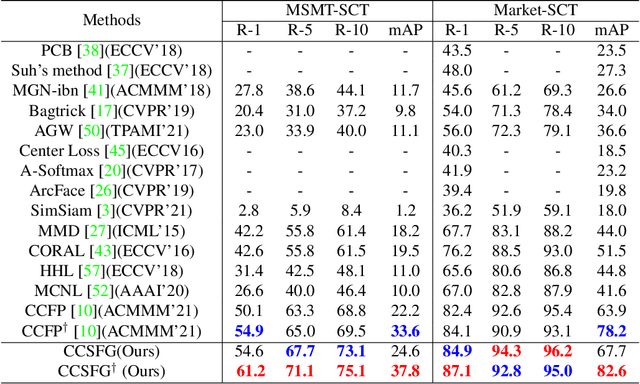
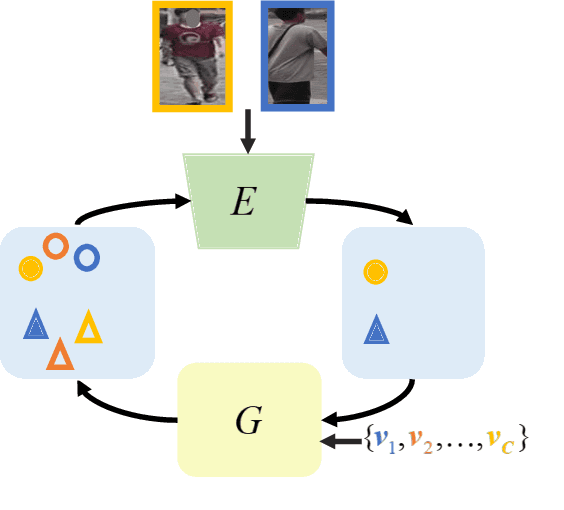
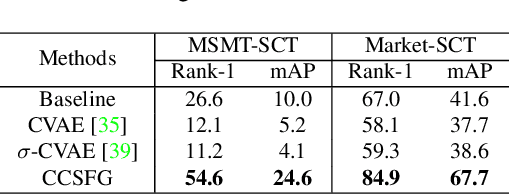
To learn camera-view invariant features for person Re-IDentification (Re-ID), the cross-camera image pairs of each person play an important role. However, such cross-view training samples could be unavailable under the ISolated Camera Supervised (ISCS) setting, e.g., a surveillance system deployed across distant scenes. To handle this challenging problem, a new pipeline is introduced by synthesizing the cross-camera samples in the feature space for model training. Specifically, the feature encoder and generator are end-to-end optimized under a novel method, Camera-Conditioned Stable Feature Generation (CCSFG). Its joint learning procedure raises concern on the stability of generative model training. Therefore, a new feature generator, $\sigma$-Regularized Conditional Variational Autoencoder ($\sigma$-Reg.~CVAE), is proposed with theoretical and experimental analysis on its robustness. Extensive experiments on two ISCS person Re-ID datasets demonstrate the superiority of our CCSFG to the competitors.
SATS: Self-Attention Transfer for Continual Semantic Segmentation
Mar 15, 2022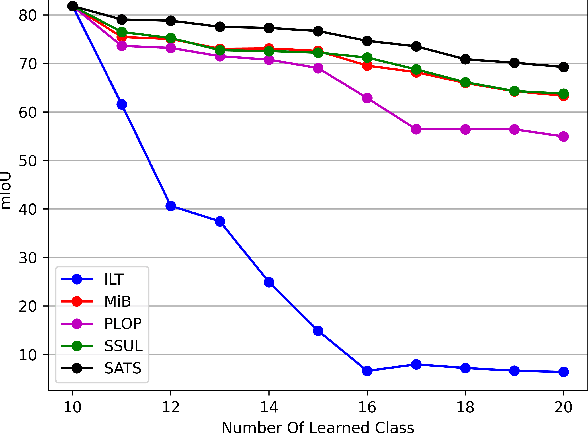
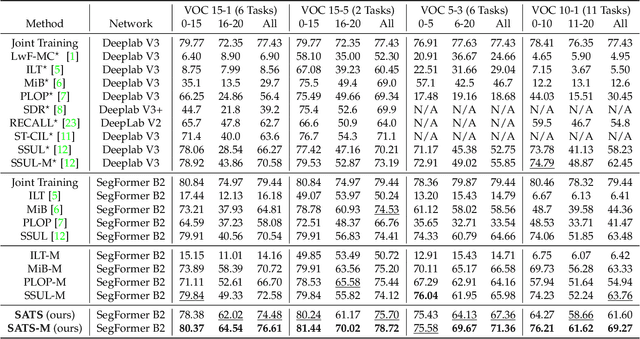
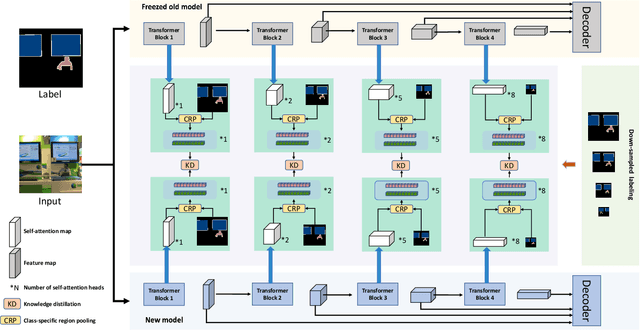
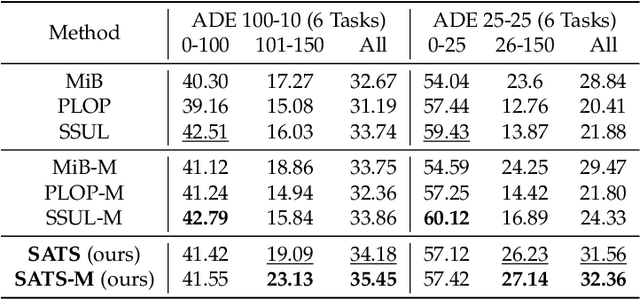
Continually learning to segment more and more types of image regions is a desired capability for many intelligent systems. However, such continual semantic segmentation suffers from the same catastrophic forgetting issue as in continual classification learning. While multiple knowledge distillation strategies originally for continual classification have been well adapted to continual semantic segmentation, they only consider transferring old knowledge based on the outputs from one or more layers of deep fully convolutional networks. Different from existing solutions, this study proposes to transfer a new type of information relevant to knowledge, i.e. the relationships between elements (Eg. pixels or small local regions) within each image which can capture both within-class and between-class knowledge. The relationship information can be effectively obtained from the self-attention maps in a Transformer-style segmentation model. Considering that pixels belonging to the same class in each image often share similar visual properties, a class-specific region pooling is applied to provide more efficient relationship information for knowledge transfer. Extensive evaluations on multiple public benchmarks support that the proposed self-attention transfer method can further effectively alleviate the catastrophic forgetting issue, and its flexible combination with one or more widely adopted strategies significantly outperforms state-of-the-art solu
Learning Discriminative Prototypes with Dynamic Time Warping
Mar 17, 2021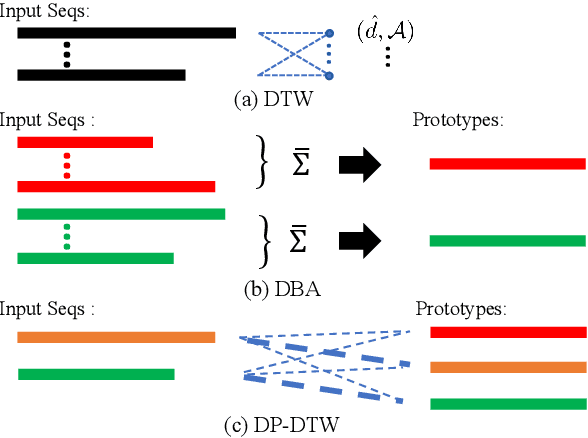

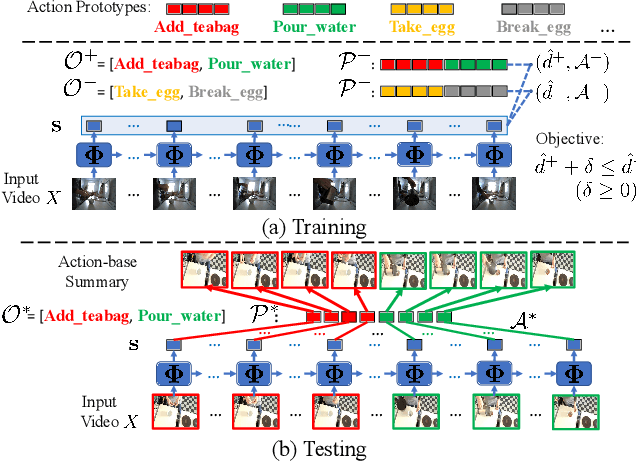
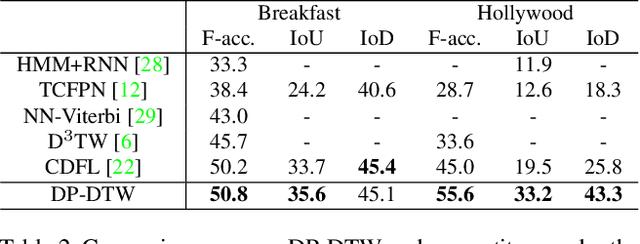
Dynamic Time Warping (DTW) is widely used for temporal data processing. However, existing methods can neither learn the discriminative prototypes of different classes nor exploit such prototypes for further analysis. We propose Discriminative Prototype DTW (DP-DTW), a novel method to learn class-specific discriminative prototypes for temporal recognition tasks. DP-DTW shows superior performance compared to conventional DTWs on time series classification benchmarks. Combined with end-to-end deep learning, DP-DTW can handle challenging weakly supervised action segmentation problems and achieves state of the art results on standard benchmarks. Moreover, detailed reasoning on the input video is enabled by the learned action prototypes. Specifically, an action-based video summarization can be obtained by aligning the input sequence with action prototypes.
Disjoint Label Space Transfer Learning with Common Factorised Space
Dec 06, 2018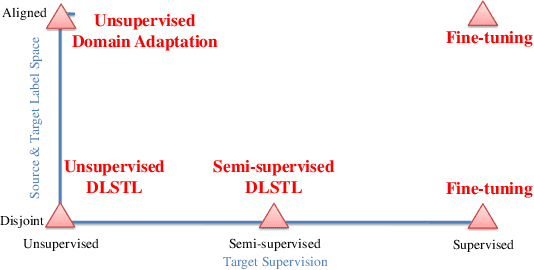
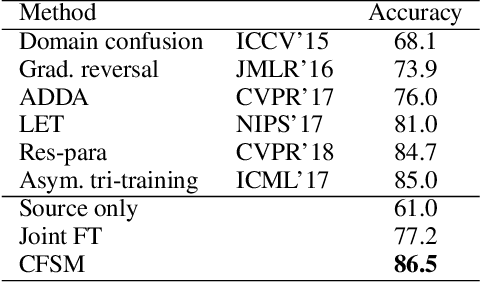
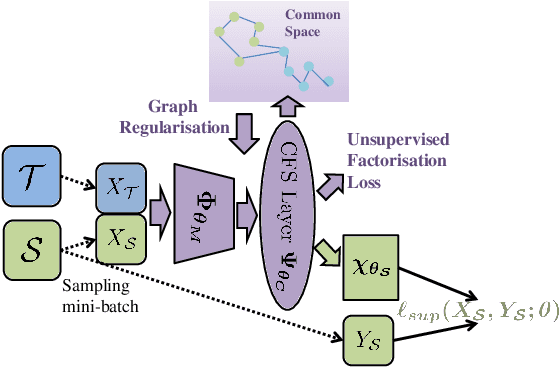
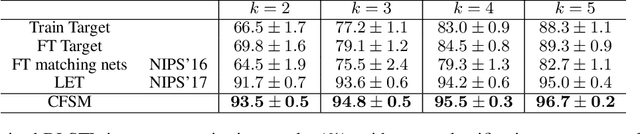
In this paper, a unified approach is presented to transfer learning that addresses several source and target domain label-space and annotation assumptions with a single model. It is particularly effective in handling a challenging case, where source and target label-spaces are disjoint, and outperforms alternatives in both unsupervised and semi-supervised settings. The key ingredient is a common representation termed Common Factorised Space. It is shared between source and target domains, and trained with an unsupervised factorisation loss and a graph-based loss. With a wide range of experiments, we demonstrate the flexibility, relevance and efficacy of our method, both in the challenging cases with disjoint label spaces, and in the more conventional cases such as unsupervised domain adaptation, where the source and target domains share the same label-sets.
Multi-Level Factorisation Net for Person Re-Identification
Apr 17, 2018
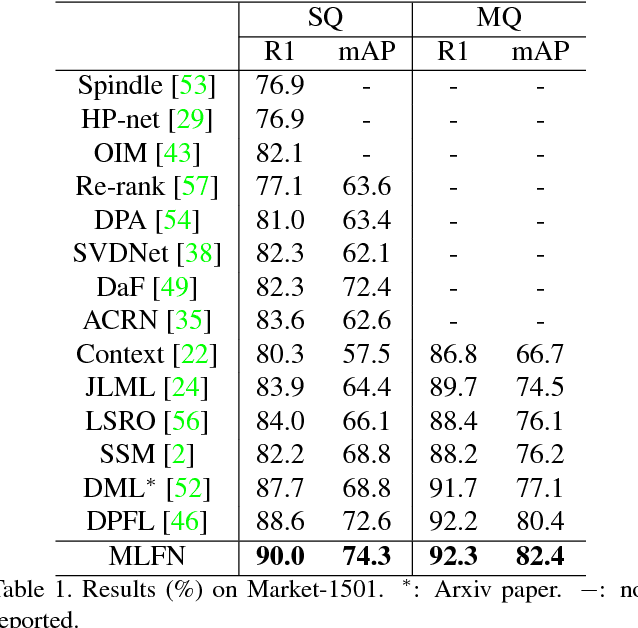
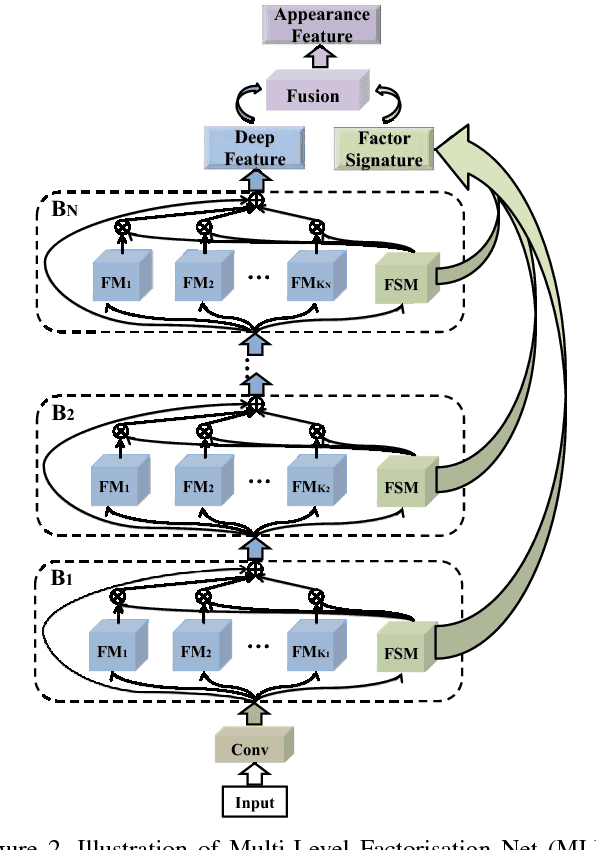

Key to effective person re-identification (Re-ID) is modelling discriminative and view-invariant factors of person appearance at both high and low semantic levels. Recently developed deep Re-ID models either learn a holistic single semantic level feature representation and/or require laborious human annotation of these factors as attributes. We propose Multi-Level Factorisation Net (MLFN), a novel network architecture that factorises the visual appearance of a person into latent discriminative factors at multiple semantic levels without manual annotation. MLFN is composed of multiple stacked blocks. Each block contains multiple factor modules to model latent factors at a specific level, and factor selection modules that dynamically select the factor modules to interpret the content of each input image. The outputs of the factor selection modules also provide a compact latent factor descriptor that is complementary to the conventional deeply learned features. MLFN achieves state-of-the-art results on three Re-ID datasets, as well as compelling results on the general object categorisation CIFAR-100 dataset.