 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Middle: Exploiting Mid-level Representations for Cross-Domain Instance Matching
Paper and Code
Apr 04, 2018
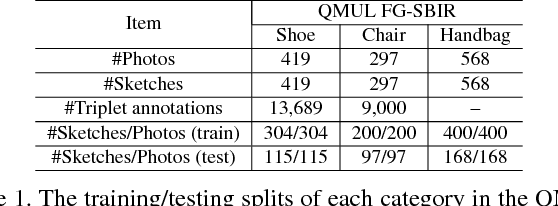
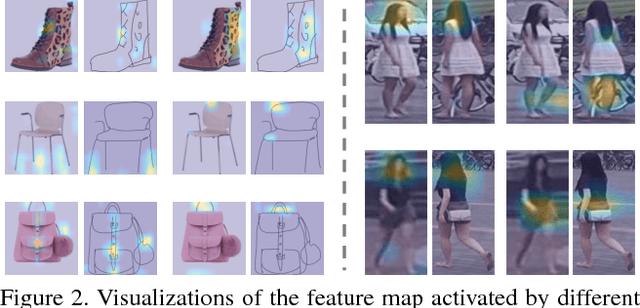
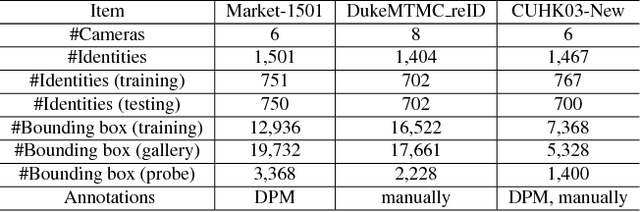
Many vision problems require matching images of object instances across different domains. These include fine-grained sketch-based image retrieval (FG-SBIR) and Person Re-identification (person ReID). Existing approaches attempt to learn a joint embedding space where images from different domains can be directly compared. In most cases, this space is defined by the output of the final layer of a deep neural network (DNN), which primarily contains features of a high semantic level. In this paper, we argue that both high and mid-level features are relevant for cross-domain instance matching (CDIM). Importantly, mid-level features already exist in earlier layers of the DNN. They just need to be extracted, represented, and fused properly with the final layer. Based on this simple but powerful idea, we propose a unified framework for CDIM. Instantiating our framework for FG-SBIR and ReID, we show that our simple models can easily beat the state-of-the-art models, which are often equipped with much more elaborate architectures.