 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stochastic Approach to Bi-Level Optimization for Hyperparameter Optimization and Meta Learning
Oct 14, 2024We tackle the general differentiable meta learning problem that is ubiquitous in modern deep learning, including hyperparameter optimization, loss function learning, few-shot learning, invariance learning and more. These problems are often formalized as Bi-Level optimizations (BLO). We introduce a novel perspective by turning a given BLO problem into a stochastic optimization, where the inner loss function becomes a smooth probability distribution, and the outer loss becomes an expected loss over the inner distribution. To solve this stochastic optimization, we adopt Stochastic Gradient Langevin Dynamics (SGLD) MCMC to sample inner distribution, and propose a recurrent algorithm to compute the MC-estimated hypergradient. Our derivation is similar to forward-mode differentiation, but we introduce a new first-order approximation that makes it feasible for large models without needing to store huge Jacobian matrices. The main benefits are two-fold: i) Our stochastic formulation takes into account uncertainty, which makes the method robust to suboptimal inner optimization or non-unique multiple inner minima due to overparametrization; ii) Compared to existing methods that often exhibit unstable behavior and hyperparameter sensitivity in practice, our method leads to considerably more reliable solutions. We demonstrate that the new approach achieves promising results on diverse meta learning problems and easily scales to learning 87M hyperparameters in the case of Vision Transformers.
Better Practices for Domain Adaptation
Sep 07, 2023Distribution shifts are all too common in real-world applications of machine learning. Domain adaptation (DA) aims to address this by providing various frameworks for adapting models to the deployment data without using labels. However, the domain shift scenario raises a second more subtle challenge: the difficulty of performing hyperparameter optimisation (HPO) for these adaptation algorithms without access to a labelled validation set. The unclear validation protocol for DA has led to bad practices in the literature, such as performing HPO using the target test labels when, in real-world scenarios, they are not available. This has resulted in over-optimism about DA research progress compared to reality. In this paper, we analyse the state of DA when using good evaluation practice, by benchmarking a suite of candidate validation criteria and using them to assess popular adaptation algorithms. We show that there are challenges across all three branches of domain adaptation methodology including Unsupervised Domain Adaptation (UDA), Source-Free Domain Adaptation (SFDA), and Test Time Adaptation (TTA). While the results show that realistically achievable performance is often worse than expected, they also show that using proper validation splits is beneficial, as well as showing that some previously unexplored validation metrics provide the best options to date. Altogether, our improved practices covering data, training, validation and hyperparameter optimisation form a new rigorous pipeline to improve benchmarking, and hence research progress, within this important field going forward.
Fairness meets Cross-Domain Learning: a new perspective on Models and Metrics
Mar 25, 2023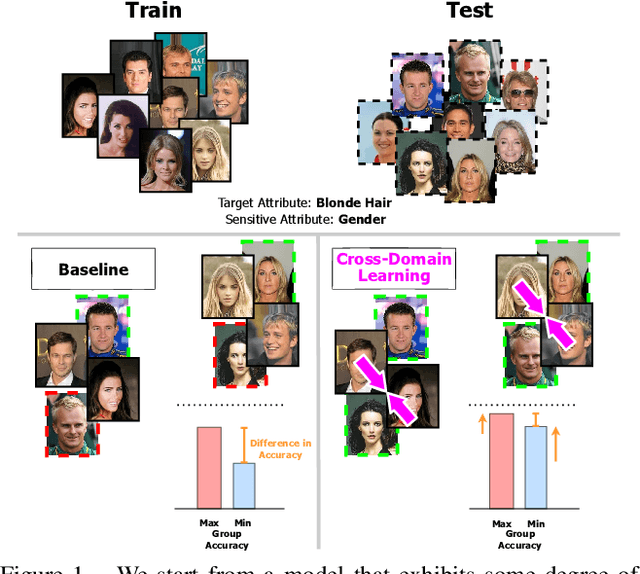
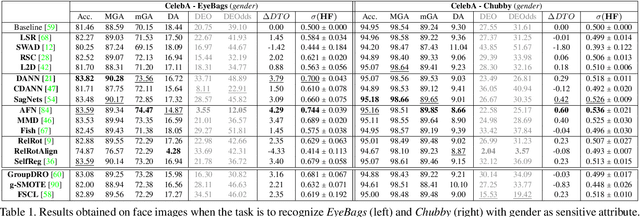
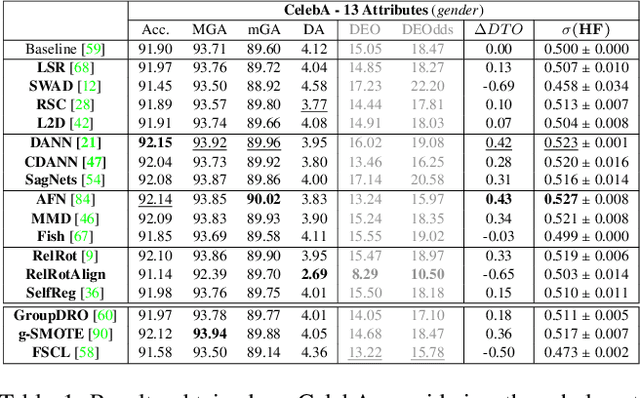
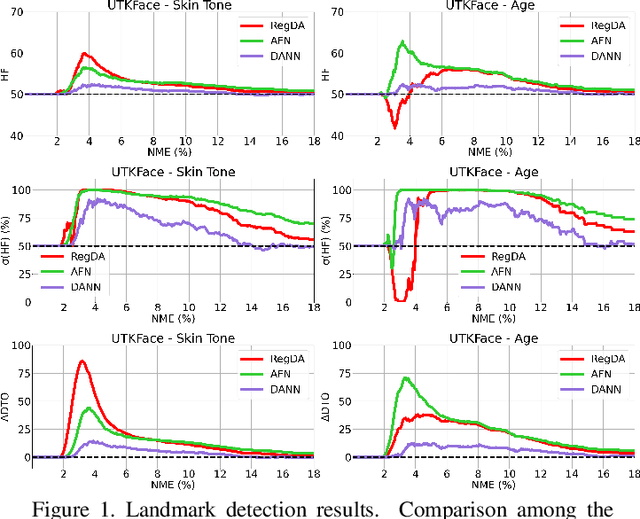
Deep learning-based recognition systems are deployed at scale for several real-world applications that inevitably involve our social life. Although being of great support when making complex decisions, they might capture spurious data correlations and leverage sensitive attributes (e.g. age, gender, ethnicity). How to factor out this information while keeping a high prediction performance is a task with still several open questions, many of which are shared with those of the domain adaptation and generalization literature which focuses on avoiding visual domain biases. In this work, we propose an in-depth study of the relationship between cross-domain learning (CD) and model fairness by introducing a benchmark on face and medical images spanning several demographic groups as well as classification and localization tasks. After having highlighted the limits of the current evaluation metrics, we introduce a new Harmonic Fairness (HF) score to assess jointly how fair and accurate every model is with respect to a reference baseline. Our study covers 14 CD approaches alongside three state-of-the-art fairness algorithms and shows how the former can outperform the latter. Overall, our work paves the way for a more systematic analysis of fairness problems in computer vision. Code available at: https://github.com/iurada/fairness_crossdomain
Accelerating Self-Supervised Learning via Efficient Training Strategies
Dec 11, 2022Recently the focus of the computer vision community has shifted from expensive supervised learning towards self-supervised learning of visual representations. While the performance gap between supervised and self-supervised has been narrowing, the time for training self-supervised deep networks remains an order of magnitude larger than its supervised counterparts, which hinders progress, imposes carbon cost, and limits societal benefits to institutions with substantial resources. Motivated by these issues, this paper investigates reducing the training time of recent self-supervised methods by various model-agnostic strategies that have not been used for this problem. In particular, we study three strategies: an extendable cyclic learning rate schedule, a matching progressive augmentation magnitude and image resolutions schedule, and a hard positive mining strategy based on augmentation difficulty. We show that all three methods combined lead up to 2.7 times speed-up in the training time of several self-supervised methods while retaining comparable performance to the standard self-supervised learning setting.
Fisher SAM: Information Geometry and Sharpness Aware Minimisation
Jun 10, 2022
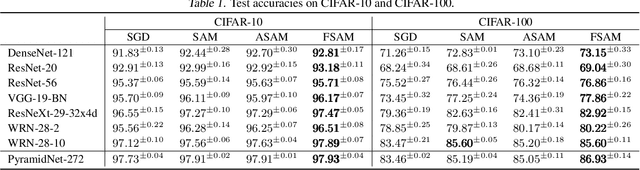

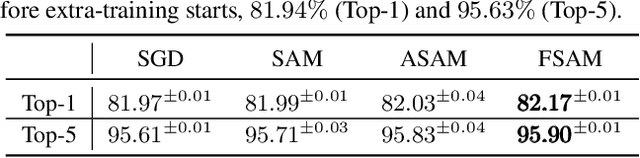
Recent sharpness-aware minimisation (SAM) is known to find flat minima which is beneficial for better generalisation with improved robustness. SAM essentially modifies the loss function by reporting the maximum loss value within the small neighborhood around the current iterate. However, it uses the Euclidean ball to define the neighborhood, which can be inaccurate since loss functions for neural networks are typically defined over probability distributions (e.g., class predictive probabilities), rendering the parameter space non Euclidean. In this paper we consider the information geometry of the model parameter space when defining the neighborhood, namely replacing SAM's Euclidean balls with ellipsoids induced by the Fisher information. Our approach, dubbed Fisher SAM, defines more accurate neighborhood structures that conform to the intrinsic metric of the underlying statistical manifold. For instance, SAM may probe the worst-case loss value at either a too nearby or inappropriately distant point due to the ignorance of the parameter space geometry, which is avoided by our Fisher SAM. Another recent Adaptive SAM approach stretches/shrinks the Euclidean ball in accordance with the scale of the parameter magnitudes. This might be dangerous, potentially destroying the neighborhood structure. We demonstrate improved performance of the proposed Fisher SAM on several benchmark datasets/tasks.
Pushing the Limits of Simple Pipelines for Few-Shot Learning: External Data and Fine-Tuning Make a Difference
Apr 15, 2022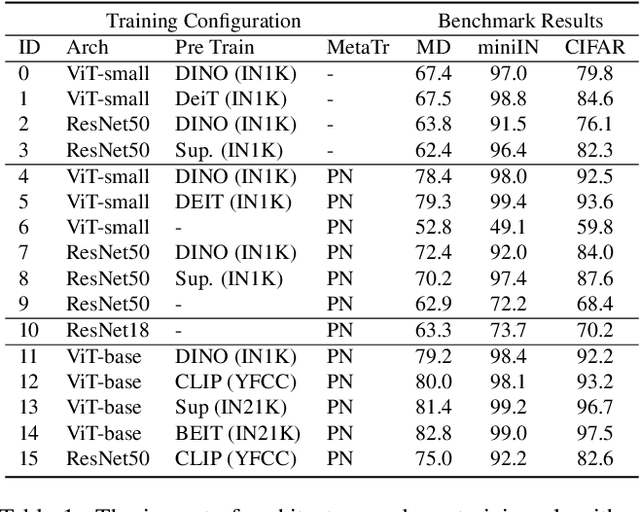
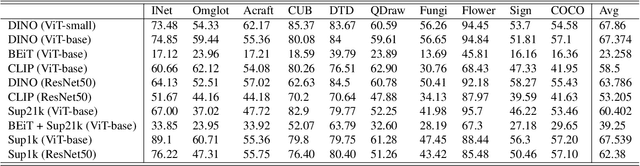

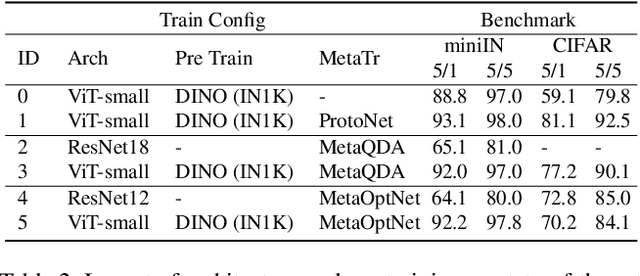
Few-shot learning (FSL) is an important and topical problem in computer vision that has motivated extensive research into numerous methods spanning from sophisticated meta-learning methods to simple transfer learning baselines. We seek to push the limits of a simple-but-effective pipeline for more realistic and practical settings of few-shot image classification. To this end, we explore few-shot learning from the perspective of neural network architecture, as well as a three stage pipeline of network updates under different data supplies, where unsupervised external data is considered for pre-training, base categories are used to simulate few-shot tasks for meta-training, and the scarcely labelled data of an novel task is taken for fine-tuning. We investigate questions such as: (1) How pre-training on external data benefits FSL? (2) How state-of-the-art transformer architectures can be exploited? and (3) How fine-tuning mitigates domain shift? Ultimately, we show that a simple transformer-based pipeline yields surprisingly good performance on standard benchmarks such as Mini-ImageNet, CIFAR-FS, CDFSL and Meta-Dataset. Our code and demo are available at https://hushell.github.io/pmf.
Meta Mirror Descent: Optimiser Learning for Fast Convergence
Mar 05, 2022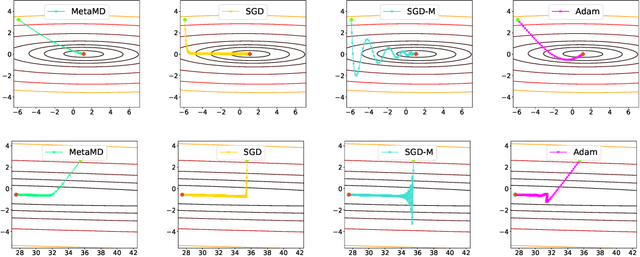
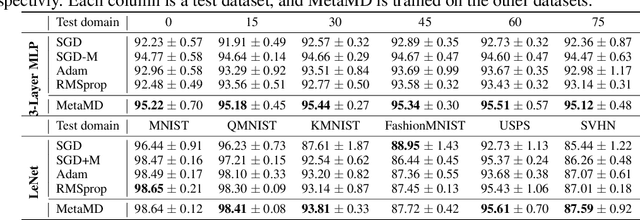
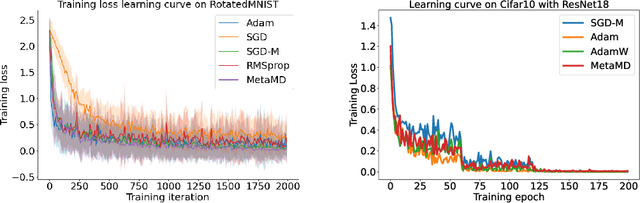
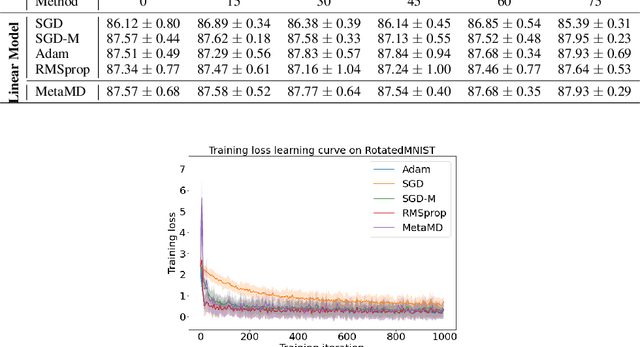
Optimisers are an essential component for training machine learning models, and their design influences learning speed and generalisation. Several studies have attempted to learn more effective gradient-descent optimisers via solving a bi-level optimisation problem where generalisation error is minimised with respect to optimiser parameters. However, most existing optimiser learning methods are intuitively motivated, without clear theoretical support. We take a different perspective starting from mirror descent rather than gradient descent, and meta-learning the corresponding Bregman divergence. Within this paradigm, we formalise a novel meta-learning objective of minimising the regret bound of learning. The resulting framework, termed Meta Mirror Descent (MetaMD), learns to accelerate optimisation speed. Unlike many meta-learned optimisers, it also supports convergence and generalisation guarantees and uniquely does so without requiring validation data. We evaluate our framework on a variety of tasks and architectures in terms of convergence rate and generalisation error and demonstrate strong performance.
Why Do Self-Supervised Models Transfer? Investigating the Impact of Invariance on Downstream Tasks
Nov 22, 2021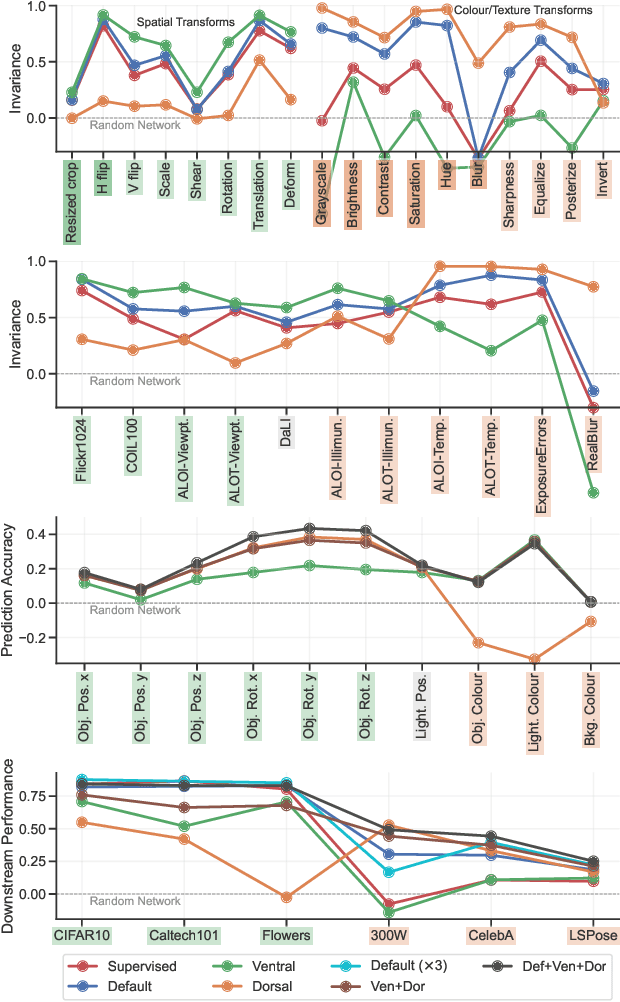


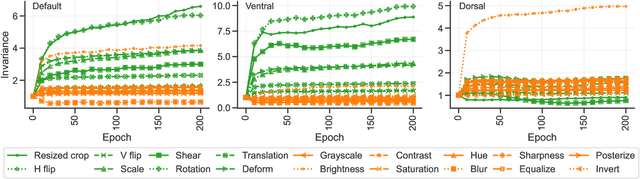
Self-supervised learning is a powerful paradigm for representation learning on unlabelled images. A wealth of effective new methods based on instance matching rely on data augmentation to drive learning, and these have reached a rough agreement on an augmentation scheme that optimises popular recognition benchmarks. However, there is strong reason to suspect that different tasks in computer vision require features to encode different (in)variances, and therefore likely require different augmentation strategies. In this paper, we measure the invariances learned by contrastive methods and confirm that they do learn invariance to the augmentations used and further show that this invariance largely transfers to related real-world changes in pose and lighting. We show that learned invariances strongly affect downstream task performance and confirm that different downstream tasks benefit from polar opposite (in)variances, leading to performance loss when the standard augmentation strategy is used. Finally, we demonstrate that a simple fusion of representations with complementary invariances ensures wide transferability to all the diverse downstream tasks considered.
Self-Supervised Representation Learning: Introduction, Advances and Challenges
Oct 18, 2021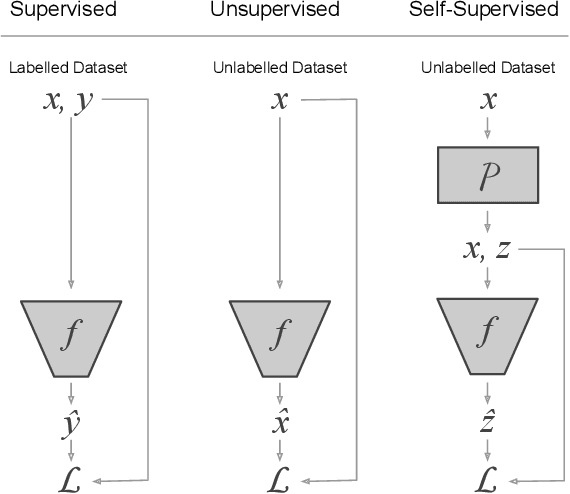
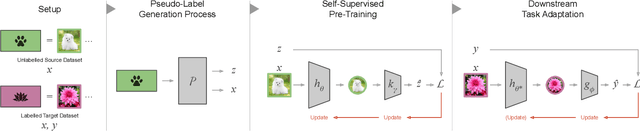
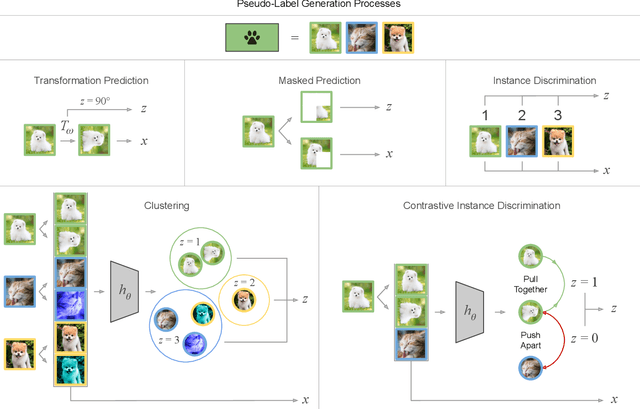

Self-supervised representation learning methods aim to provide powerful deep feature learning without the requirement of large annotated datasets, thus alleviating the annotation bottleneck that is one of the main barriers to practical deployment of deep learning today. These methods have advanced rapidly in recent years, with their efficacy approaching and sometimes surpassing fully supervised pre-training alternatives across a variety of data modalities including image, video, sound, text and graphs. This article introduces this vibrant area including key concepts, the four main families of approach and associated state of the art, and how self-supervised methods are applied to diverse modalities of data. We further discuss practical considerations including workflows, representation transferability, and compute cost. Finally, we survey the major open challenges in the field that provide fertile ground for future work.
Towards Unsupervised Sketch-based Image Retrieval
May 18, 2021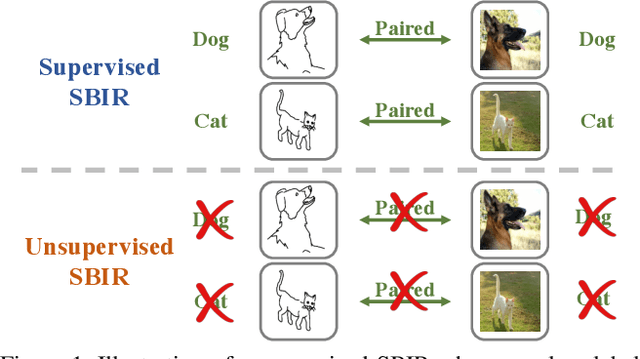
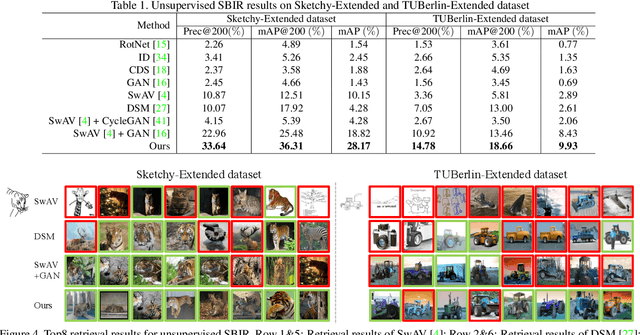


Current supervised sketch-based image retrieval (SBIR) methods achieve excellent performance. However, the cost of data collection and labeling imposes an intractable barrier to practical deployment of real applications. In this paper, we present the first attempt at unsupervised SBIR to remove the labeling cost (category annotations and sketch-photo pairings) that is conventionally needed for training. Existing single-domain unsupervised representation learning methods perform poorly in this application, due to the unique cross-domain (sketch and photo) nature of the problem. We therefore introduce a novel framework that simultaneously performs unsupervised representation learning and sketch-photo domain alignment. Technically this is underpinned by exploiting joint distribution optimal transport (JDOT) to align data from different domains during representation learning, which we extend with trainable cluster prototypes and feature memory banks to further improve scalability and efficacy. Extensive experiments show that our framework achieves excellent performance in the new unsupervised setting, and performs comparably or better than state-of-the-art in the zero-shot setting.