 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Supervised Task for Fault Detection in Satellite Multivariate Time Series
Jul 03, 2024In the space sector, due to environmental conditions and restricted accessibility, robust fault detection methods are imperative for ensuring mission success and safeguarding valuable assets. This work proposes a novel approach leveraging Physics-Informed Real NVP neural networks, renowned for their ability to model complex and high-dimensional distributions, augmented with a self-supervised task based on sensors' data permutation. It focuses on enhancing fault detection within the satellite multivariate time series. The experiments involve various configurations, including pre-training with self-supervision, multi-task learning, and standalone self-supervised training. Results indicate significant performance improvements across all settings. In particular, employing only the self-supervised loss yields the best overall results, suggesting its efficacy in guiding the network to extract relevant features for fault detection. This study presents a promising direction for improving fault detection in space systems and warrants further exploration in other datasets and applications.
Physics-Informed Real NVP for Satellite Power System Fault Detection
May 27, 2024



The unique challenges posed by the space environment, characterized by extreme conditions and limited accessibility, raise the need for robust and reliable techniques to identify and prevent satellite faults. Fault detection methods in the space sector are required to ensure mission success and to protect valuable assets. In this context, this paper proposes an Artificial Intelligence (AI) based fault detection methodology and evaluates its performance on ADAPT (Advanced Diagnostics and Prognostics Testbed), an Electrical Power System (EPS) dataset, crafted in laboratory by NASA. Our study focuses on the application of a physics-informed (PI) real-valued non-volume preserving (Real NVP) model for fault detection in space systems. The efficacy of this method is systematically compared against other AI approaches such as Gated Recurrent Unit (GRU) and Autoencoder-based techniques. Results show that our physics-informed approach outperforms existing methods of fault detection, demonstrating its suitability for addressing the unique challenges of satellite EPS sub-system faults. Furthermore, we unveil the competitive advantage of physics-informed loss in AI models to address specific space needs, namely robustness, reliability, and power constraints, crucial for space exploration and satellite missions.
Fairness meets Cross-Domain Learning: a new perspective on Models and Metrics
Mar 25, 2023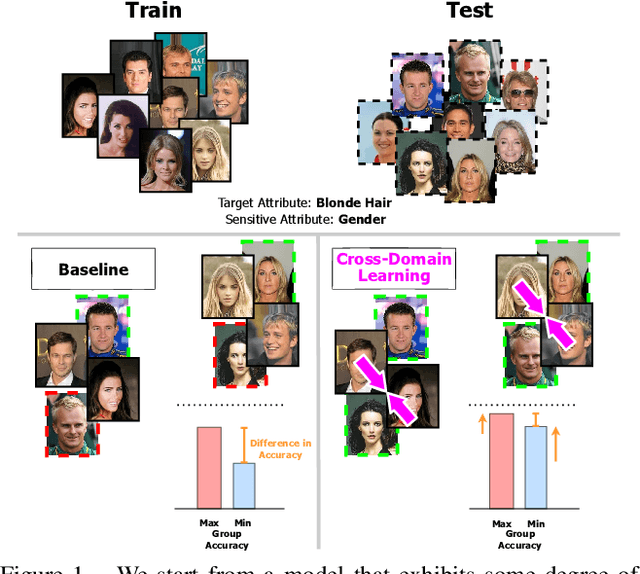
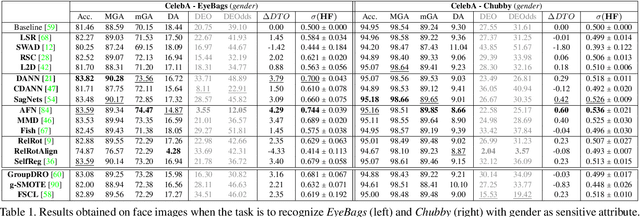
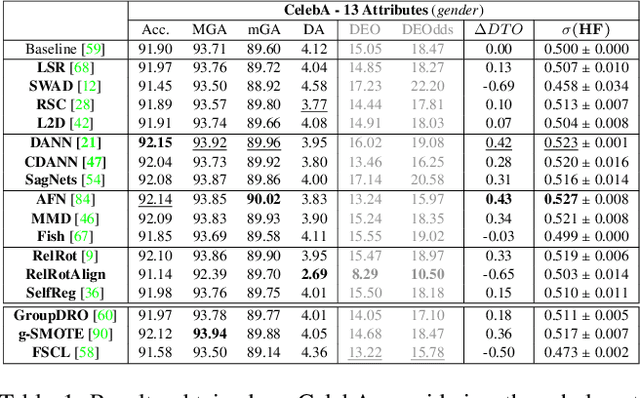
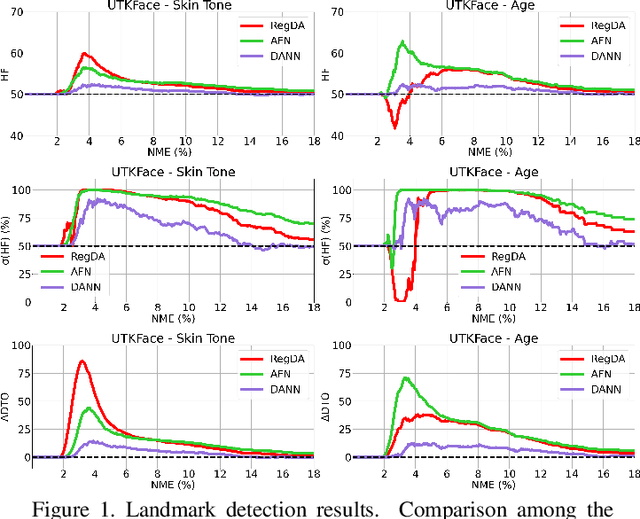
Deep learning-based recognition systems are deployed at scale for several real-world applications that inevitably involve our social life. Although being of great support when making complex decisions, they might capture spurious data correlations and leverage sensitive attributes (e.g. age, gender, ethnicity). How to factor out this information while keeping a high prediction performance is a task with still several open questions, many of which are shared with those of the domain adaptation and generalization literature which focuses on avoiding visual domain biases. In this work, we propose an in-depth study of the relationship between cross-domain learning (CD) and model fairness by introducing a benchmark on face and medical images spanning several demographic groups as well as classification and localization tasks. After having highlighted the limits of the current evaluation metrics, we introduce a new Harmonic Fairness (HF) score to assess jointly how fair and accurate every model is with respect to a reference baseline. Our study covers 14 CD approaches alongside three state-of-the-art fairness algorithms and shows how the former can outperform the latter. Overall, our work paves the way for a more systematic analysis of fairness problems in computer vision. Code available at: https://github.com/iurada/fairness_crossdomain
WiCV 2022: The Tenth Women In Computer Vision Workshop
Aug 24, 2022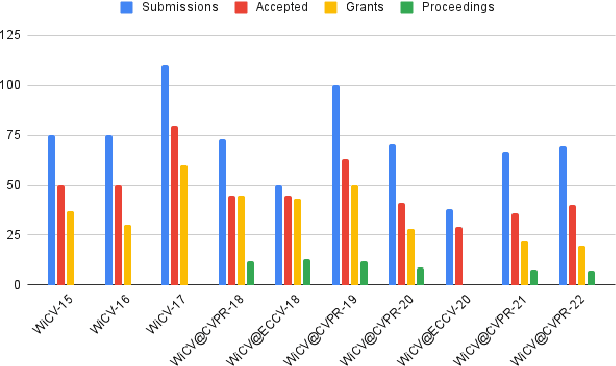
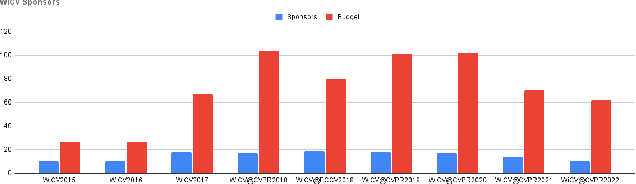
In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2022, organized alongside the hybrid CVPR 2022 in New Orleans, Louisiana. It provides a voice to a minority (female) group in the computer vision community and focuses on increasing the visibility of these researchers, both in academia and industry. WiCV believes that such an event can play an important role in lowering the gender imbalance in the field of computer vision. WiCV is organized each year where it provides a) opportunity for collaboration between researchers from minority groups, b) mentorship to female junior researchers, c) financial support to presenters to overcome monetary burden and d) large and diverse choice of role models, who can serve as examples to younger researchers at the beginning of their careers. In this paper, we present a report on the workshop program, trends over the past years, a summary of statistics regarding presenters, attendees, and sponsorship for the WiCV 2022 workshop.
Semantic Novelty Detection via Relational Reasoning
Jul 18, 2022
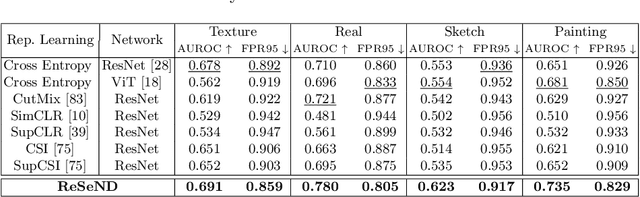
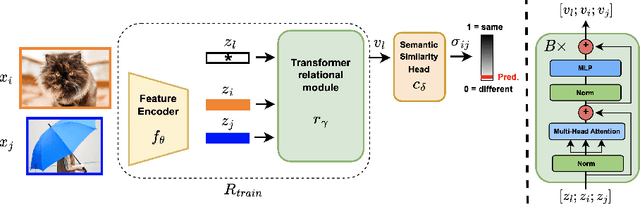
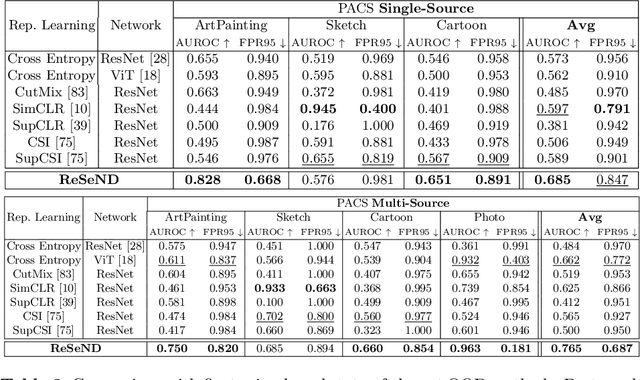
Semantic novelty detection aims at discovering unknown categories in the test data. This task is particularly relevant in safety-critical applications, such as autonomous driving or healthcare, where it is crucial to recognize unknown objects at deployment time and issue a warning to the user accordingly. Despite the impressive advancements of deep learning research, existing models still need a finetuning stage on the known categories in order to recognize the unknown ones. This could be prohibitive when privacy rules limit data access, or in case of strict memory and computational constraints (e.g. edge computing). We claim that a tailored representation learning strategy may be the right solution for effective and efficient semantic novelty detection. Besides extensively testing state-of-the-art approaches for this task, we propose a novel representation learning paradigm based on relational reasoning. It focuses on learning how to measure semantic similarity rather than recognizing known categories. Our experiments show that this knowledge is directly transferable to a wide range of scenarios, and it can be exploited as a plug-and-play module to convert closed-set recognition models into reliable open-set ones.
Contrastive Learning for Cross-Domain Open World Recognition
Mar 17, 2022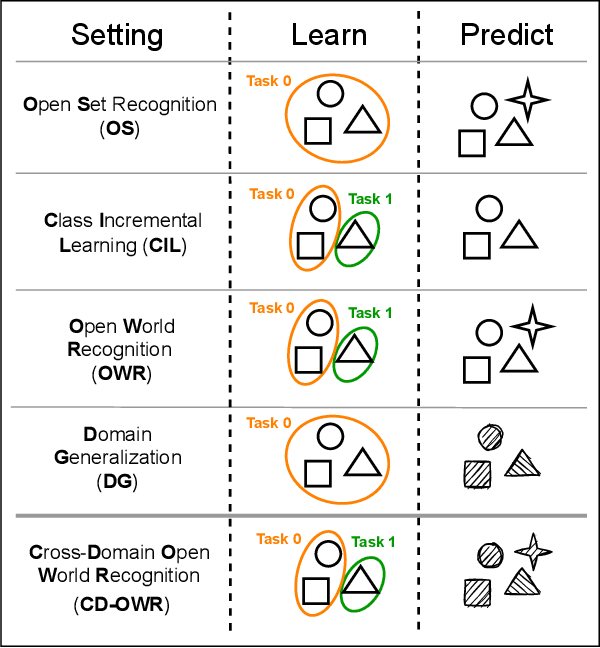

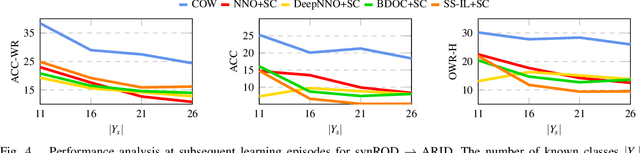
The ability to evolve is fundamental for any valuable autonomous agent whose knowledge cannot remain limited to that injected by the manufacturer. Consider for example a home assistant robot: it should be able to incrementally learn new object categories when requested, but also to recognize the same objects in different environments (rooms) and poses (hand-held/on the floor/above furniture), while rejecting unknown ones. Despite its importance, this scenario has started to raise interest in the robotic community only recently and the related research is still in its infancy, with existing experimental testbeds but no tailored methods. With this work, we propose the first learning approach that deals with all the previously mentioned challenges at once by exploiting a single contrastive objective. We show how it learns a feature space perfectly suitable to incrementally include new classes and is able to capture knowledge which generalizes across a variety of visual domains. Our method is endowed with a tailored effective stopping criterion for each learning episode and exploits a novel self-paced thresholding strategy that provides the classifier with a reliable rejection option. Both these contributions are based on the observation of the data statistics and do not need manual tuning. An extensive experimental analysis confirms the effectiveness of the proposed approach establishing the new state-of-the-art. The code is available at https://github.com/FrancescoCappio/Contrastive_Open_World.
Distance-based Hyperspherical Classification for Multi-source Open-Set Domain Adaptation
Jul 14, 2021



Vision systems trained in closed-world scenarios will inevitably fail when presented with new environmental conditions, new data distributions and novel classes at deployment time. How to move towards open-world learning is a long standing research question, but the existing solutions mainly focus on specific aspects of the problem (single domain Open-Set, multi-domain Closed-Set), or propose complex strategies which combine multiple losses and manually tuned hyperparameters. In this work we tackle multi-source Open-Set domain adaptation by introducing HyMOS: a straightforward supervised model that exploits the power of contrastive learning and the properties of its hyperspherical feature space to correctly predict known labels on the target, while rejecting samples belonging to any unknown class. HyMOS includes a tailored data balancing to enforce cross-source alignment and introduces style transfer among the instance transformations of contrastive learning for source-target adaptation, avoiding the risk of negative transfer. Finally a self-training strategy refines the model without the need for handcrafted thresholds. We validate our method over three challenging datasets and provide an extensive quantitative and qualitative experimental analysis. The obtained results show that HyMOS outperforms several Open-Set and universal domain adaptation approaches, defining the new state-of-the-art.
Towards Fairness Certification in Artificial Intelligence
Jun 04, 2021Thanks to the great progress of machine learning in the last years, several Artificial Intelligence (AI) techniques have been increasingly moving from the controlled research laboratory settings to our everyday life. AI is clearly supportive in many decision-making scenarios, but when it comes to sensitive areas such as health care, hiring policies, education, banking or justice, with major impact on individuals and society, it becomes crucial to establish guidelines on how to design, develop, deploy and monitor this technology. Indeed the decision rules elaborated by machine learning models are data-driven and there are multiple ways in which discriminatory biases can seep into data. Algorithms trained on those data incur the risk of amplifying prejudices and societal stereotypes by over associating protected attributes such as gender, ethnicity or disabilities with the prediction task. Starting from the extensive experience of the National Metrology Institute on measurement standards and certification roadmaps, and of Politecnico di Torino on machine learning as well as methods for domain bias evaluation and mastering, we propose a first joint effort to define the operational steps needed for AI fairness certification. Specifically we will overview the criteria that should be met by an AI system before coming into official service and the conformity assessment procedures useful to monitor its functioning for fair decisions.
Translate to Adapt: RGB-D Scene Recognition across Domains
Mar 26, 2021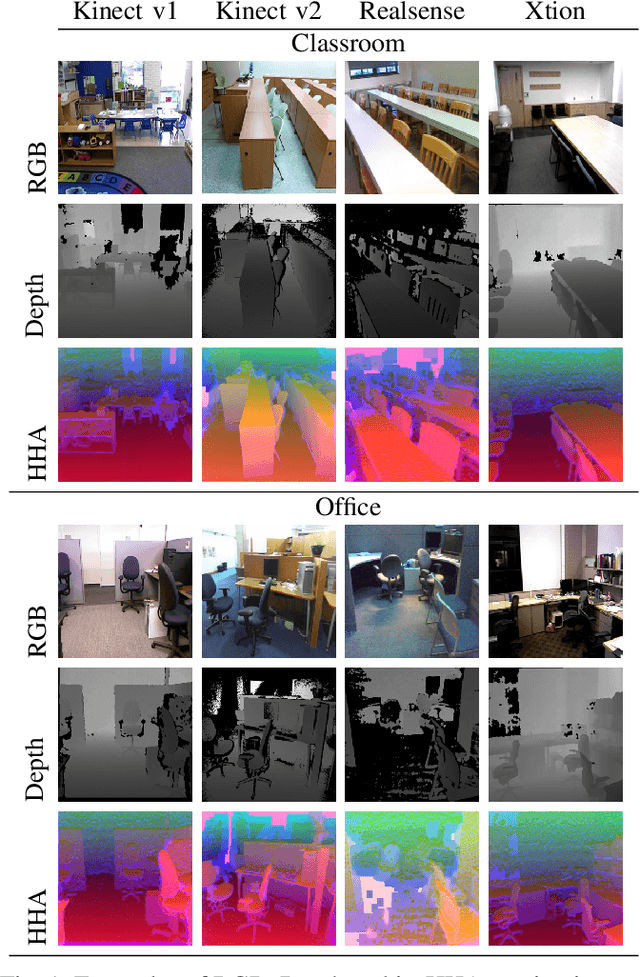
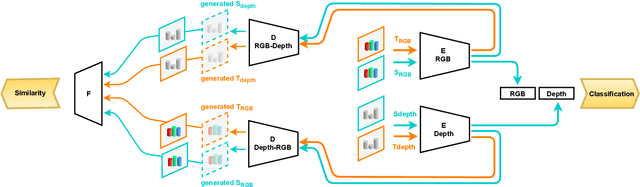


Scene classification is one of the basic problems in computer vision research with extensive applications in robotics. When available, depth images provide helpful geometric cues that complement the RGB texture information and help to identify more discriminative scene image features. Depth sensing technology developed fast in the last years and a great variety of 3D cameras have been introduced, each with different acquisition properties. However, when targeting big data collections, often multi-modal images are gathered disregarding their original nature. In this work we put under the spotlight the existence of a possibly severe domain shift issue within multi-modality scene recognition datasets. We design an experimental testbed to study this problem and present a method based on self-supervised inter-modality translation able to adapt across different camera domains. Our extensive experimental analysis confirms the effectiveness of the proposed approach.
Self-Supervised Learning Across Domains
Jul 24, 2020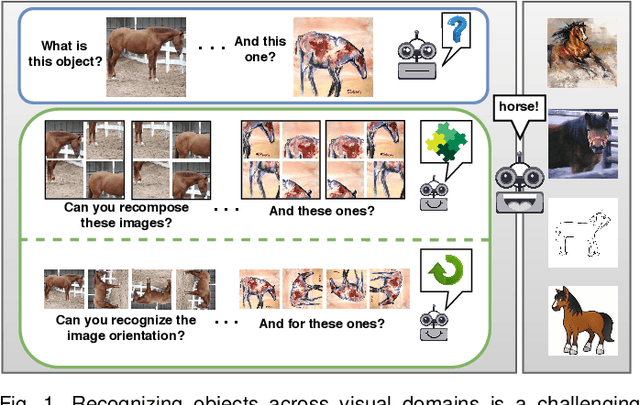
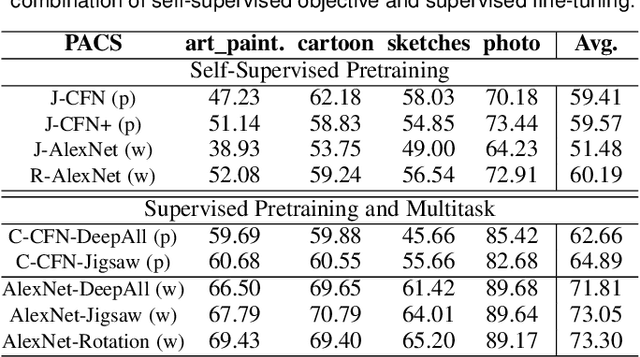
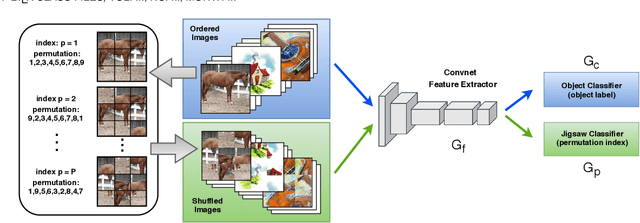
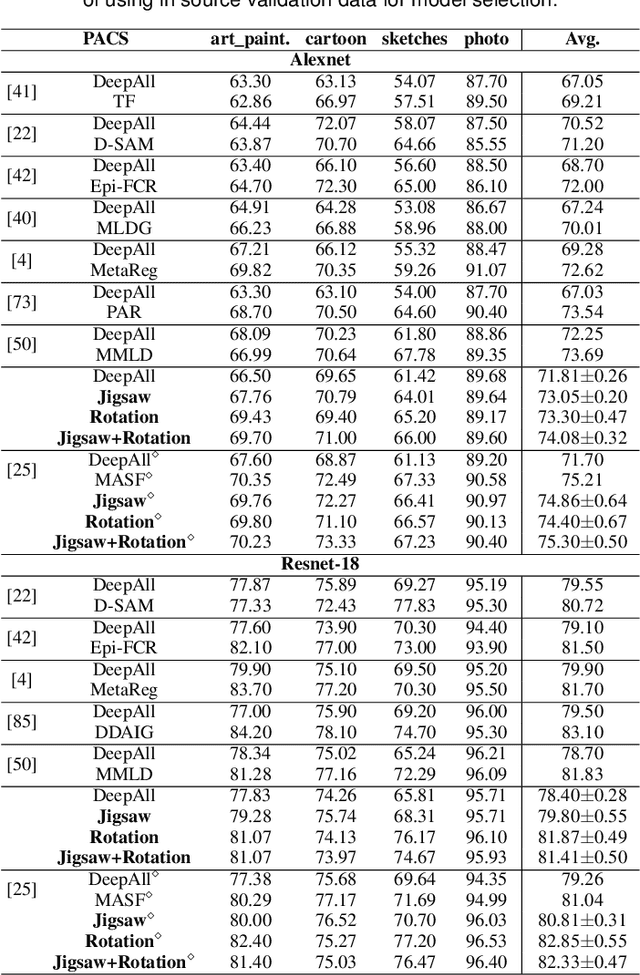
Human adaptability relies crucially on learning and merging knowledge from both supervised and unsupervised tasks: the parents point out few important concepts, but then the children fill in the gaps on their own. This is particularly effective, because supervised learning can never be exhaustive and thus learning autonomously allows to discover invariances and regularities that help to generalize. In this paper we propose to apply a similar approach to the problem of object recognition across domains: our model learns the semantic labels in a supervised fashion, and broadens its understanding of the data by learning from self-supervised signals on the same images. This secondary task helps the network to learn the concepts like spatial orientation and part correlation, while acting as a regularizer for the classification task. Extensive experiments confirm our intuition and show that our multi-task method combining supervised and self-supervised knowledge shows competitive results with respect to more complex domain generalization and adaptation solutions. It also proves its potential in the novel and challenging predictive and partial domain adaptation scenarios.