 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenPatch: a 3D patchwork for Out-Of-Distribution detection
Oct 06, 2023



Moving deep learning models from the laboratory setting to the open world entails preparing them to handle unforeseen conditions. In several applications the occurrence of novel classes during deployment poses a significant threat, thus it is crucial to effectively detect them. Ideally, this skill should be used when needed without requiring any further computational training effort at every new task. Out-of-distribution detection has attracted significant attention in the last years, however the majority of the studies deal with 2D images ignoring the inherent 3D nature of the real-world and often confusing between domain and semantic novelty. In this work, we focus on the latter, considering the objects geometric structure captured by 3D point clouds regardless of the specific domain. We advance the field by introducing OpenPatch that builds on a large pre-trained model and simply extracts from its intermediate features a set of patch representations that describe each known class. For any new sample, we obtain a novelty score by evaluating whether it can be recomposed mainly by patches of a single known class or rather via the contribution of multiple classes. We present an extensive experimental evaluation of our approach for the task of semantic novelty detection on real-world point cloud samples when the reference known data are synthetic. We demonstrate that OpenPatch excels in both the full and few-shot known sample scenarios, showcasing its robustness across varying pre-training objectives and network backbones. The inherent training-free nature of our method allows for its immediate application to a wide array of real-world tasks, offering a compelling advantage over approaches that need expensive retraining efforts.
Large Class Separation is not what you need for Relational Reasoning-based OOD Detection
Jul 12, 2023Standard recognition approaches are unable to deal with novel categories at test time. Their overconfidence on the known classes makes the predictions unreliable for safety-critical applications such as healthcare or autonomous driving. Out-Of-Distribution (OOD) detection methods provide a solution by identifying semantic novelty. Most of these methods leverage a learning stage on the known data, which means training (or fine-tuning) a model to capture the concept of normality. This process is clearly sensitive to the amount of available samples and might be computationally expensive for on-board systems. A viable alternative is that of evaluating similarities in the embedding space produced by large pre-trained models without any further learning effort. We focus exactly on such a fine-tuning-free OOD detection setting. This works presents an in-depth analysis of the recently introduced relational reasoning pre-training and investigates the properties of the learned embedding, highlighting the existence of a correlation between the inter-class feature distance and the OOD detection accuracy. As the class separation depends on the chosen pre-training objective, we propose an alternative loss function to control the inter-class margin, and we show its advantage with thorough experiments.
Towards Open Set 3D Learning: A Benchmark on Object Point Clouds
Jul 23, 2022
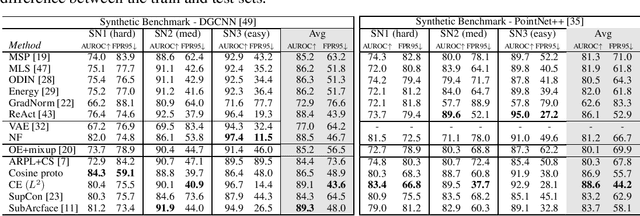


In the last years, there has been significant progress in the field of 3D learning on classification, detection and segmentation problems. The vast majority of the existing studies focus on canonical closed-set conditions, neglecting the intrinsic open nature of the real-world. This limits the abilities of autonomous systems involved in safety-critical applications that require managing novel and unknown signals. In this context exploiting 3D data can be a valuable asset since it conveys rich information about the geometry of sensed objects and scenes. This paper provides the first broad study on Open Set 3D learning. We introduce a novel testbed with settings of increasing difficulty in terms of category semantic shift and cover both in-domain (synthetic-to-synthetic) and cross-domain (synthetic-to-real) scenarios. Moreover, we investigate the related out-of-distribution and Open Set 2D literature to understand if and how their most recent approaches are effective on 3D data. Our extensive benchmark positions several algorithms in the same coherent picture, revealing their strengths and limitations. The results of our analysis may serve as a reliable foothold for future tailored Open Set 3D models.
Semantic Novelty Detection via Relational Reasoning
Jul 18, 2022
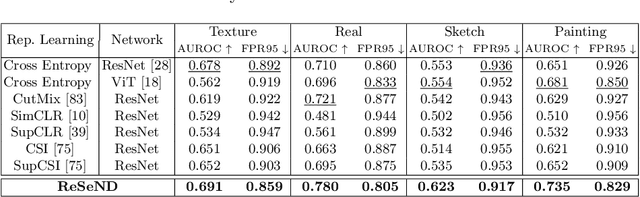
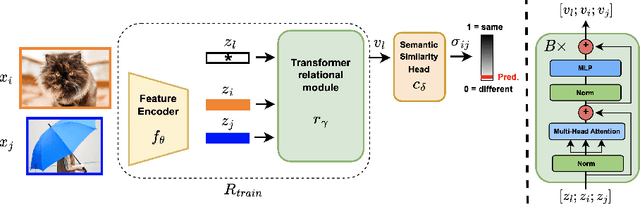
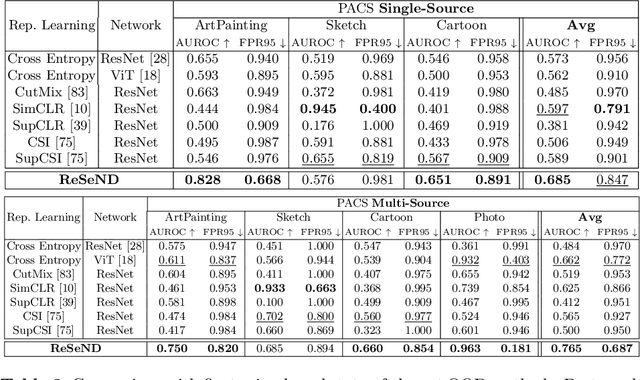
Semantic novelty detection aims at discovering unknown categories in the test data. This task is particularly relevant in safety-critical applications, such as autonomous driving or healthcare, where it is crucial to recognize unknown objects at deployment time and issue a warning to the user accordingly. Despite the impressive advancements of deep learning research, existing models still need a finetuning stage on the known categories in order to recognize the unknown ones. This could be prohibitive when privacy rules limit data access, or in case of strict memory and computational constraints (e.g. edge computing). We claim that a tailored representation learning strategy may be the right solution for effective and efficient semantic novelty detection. Besides extensively testing state-of-the-art approaches for this task, we propose a novel representation learning paradigm based on relational reasoning. It focuses on learning how to measure semantic similarity rather than recognizing known categories. Our experiments show that this knowledge is directly transferable to a wide range of scenarios, and it can be exploited as a plug-and-play module to convert closed-set recognition models into reliable open-set ones.
Contrastive Learning for Cross-Domain Open World Recognition
Mar 17, 2022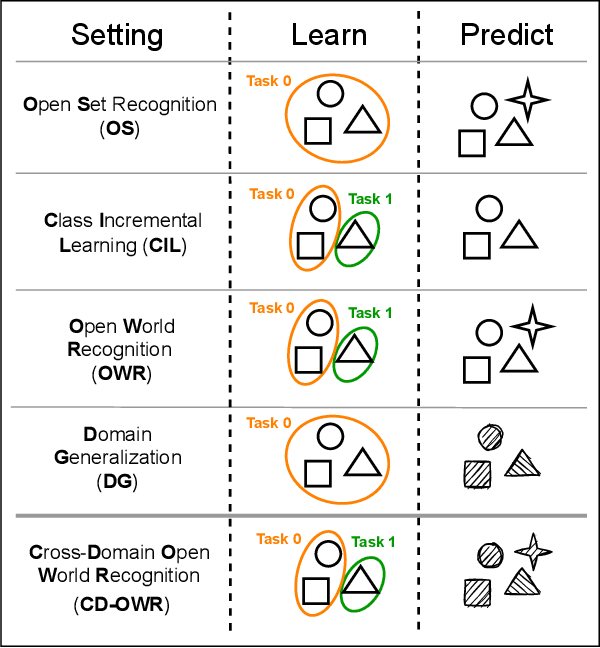

The ability to evolve is fundamental for any valuable autonomous agent whose knowledge cannot remain limited to that injected by the manufacturer. Consider for example a home assistant robot: it should be able to incrementally learn new object categories when requested, but also to recognize the same objects in different environments (rooms) and poses (hand-held/on the floor/above furniture), while rejecting unknown ones. Despite its importance, this scenario has started to raise interest in the robotic community only recently and the related research is still in its infancy, with existing experimental testbeds but no tailored methods. With this work, we propose the first learning approach that deals with all the previously mentioned challenges at once by exploiting a single contrastive objective. We show how it learns a feature space perfectly suitable to incrementally include new classes and is able to capture knowledge which generalizes across a variety of visual domains. Our method is endowed with a tailored effective stopping criterion for each learning episode and exploits a novel self-paced thresholding strategy that provides the classifier with a reliable rejection option. Both these contributions are based on the observation of the data statistics and do not need manual tuning. An extensive experimental analysis confirms the effectiveness of the proposed approach establishing the new state-of-the-art. The code is available at https://github.com/FrancescoCappio/Contrastive_Open_World.
Distance-based Hyperspherical Classification for Multi-source Open-Set Domain Adaptation
Jul 14, 2021



Vision systems trained in closed-world scenarios will inevitably fail when presented with new environmental conditions, new data distributions and novel classes at deployment time. How to move towards open-world learning is a long standing research question, but the existing solutions mainly focus on specific aspects of the problem (single domain Open-Set, multi-domain Closed-Set), or propose complex strategies which combine multiple losses and manually tuned hyperparameters. In this work we tackle multi-source Open-Set domain adaptation by introducing HyMOS: a straightforward supervised model that exploits the power of contrastive learning and the properties of its hyperspherical feature space to correctly predict known labels on the target, while rejecting samples belonging to any unknown class. HyMOS includes a tailored data balancing to enforce cross-source alignment and introduces style transfer among the instance transformations of contrastive learning for source-target adaptation, avoiding the risk of negative transfer. Finally a self-training strategy refines the model without the need for handcrafted thresholds. We validate our method over three challenging datasets and provide an extensive quantitative and qualitative experimental analysis. The obtained results show that HyMOS outperforms several Open-Set and universal domain adaptation approaches, defining the new state-of-the-art.
Rethinking Domain Generalization Baselines
Jan 27, 2021
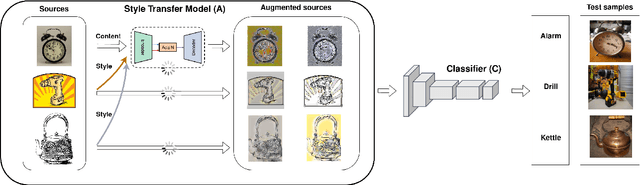
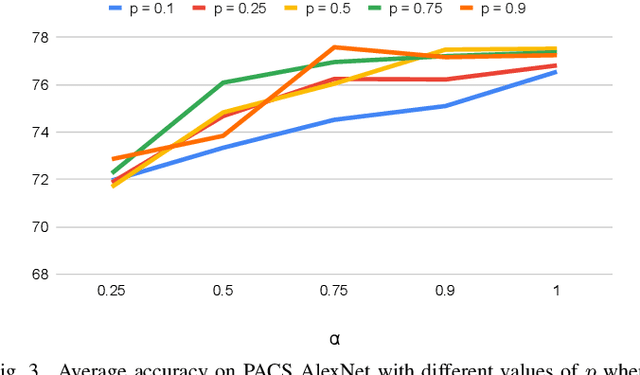

Despite being very powerful in standard learning settings, deep learning models can be extremely brittle when deployed in scenarios different from those on which they were trained. Domain generalization methods investigate this problem and data augmentation strategies have shown to be helpful tools to increase data variability, supporting model robustness across domains. In our work we focus on style transfer data augmentation and we present how it can be implemented with a simple and inexpensive strategy to improve generalization. Moreover, we analyze the behavior of current state of the art domain generalization methods when integrated with this augmentation solution: our thorough experimental evaluation shows that their original effect almost always disappears with respect to the augmented baseline. This issue open new scenarios for domain generalization research, highlighting the need of novel methods properly able to take advantage of the introduced data variability.
One-Shot Unsupervised Cross-Domain Detection
May 23, 2020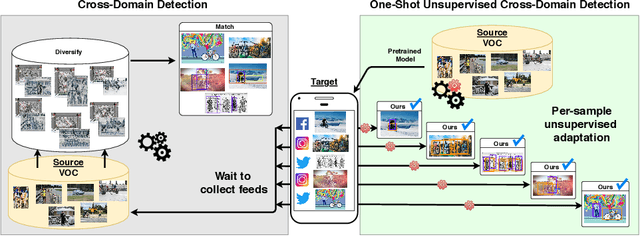
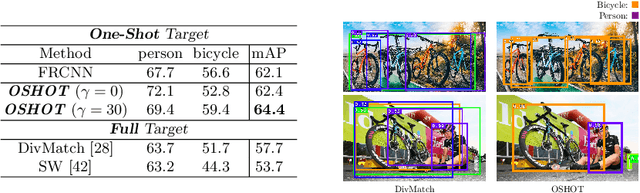
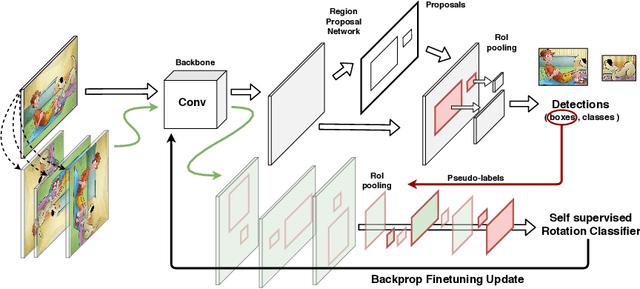

Despite impressive progress in object detection over the last years, it is still an open challenge to reliably detect objects across visual domains. Although the topic has attracted attention recently, current approaches all rely on the ability to access a sizable amount of target data for use at training time. This is a heavy assumption, as often it is not possible to anticipate the domain where a detector will be used, nor to access it in advance for data acquisition. Consider for instance the task of monitoring image feeds from social media: as every image is created and uploaded by a different user it belongs to a different target domain that is impossible to foresee during training. This paper addresses this setting, presenting an object detection algorithm able to perform unsupervised adaption across domains by using only one target sample, seen at test time. We achieve this by introducing a multi-task architecture that one-shot adapts to any incoming sample by iteratively solving a self-supervised task on it. We further enhance this auxiliary adaptation with cross-task pseudo-labeling. A thorough benchmark analysis against the most recent cross-domain detection methods and a detailed ablation study show the advantage of our method, which sets the state-of-the-art in the defined one-shot scenario.