 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning reusable concepts across different egocentric video understanding tasks
May 30, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. In this paper, we introduce Hier-EgoPack, a unified framework able to create a collection of task perspectives that can be carried across downstream tasks and used as a potential source of additional insights, as a backpack of skills that a robot can carry around and use when needed.
FORESCENE: FOREcasting human activity via latent SCENE graphs diffusion
Mar 08, 2025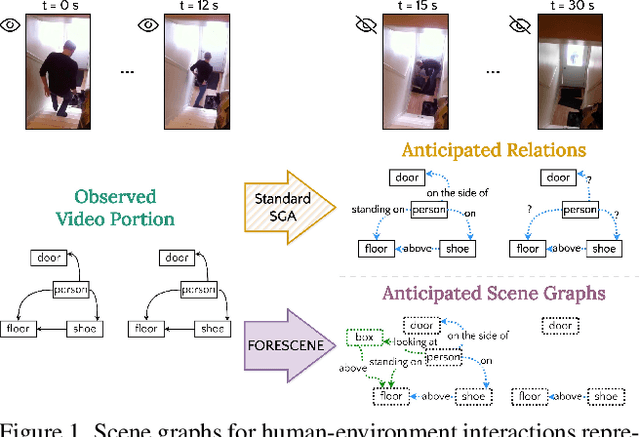
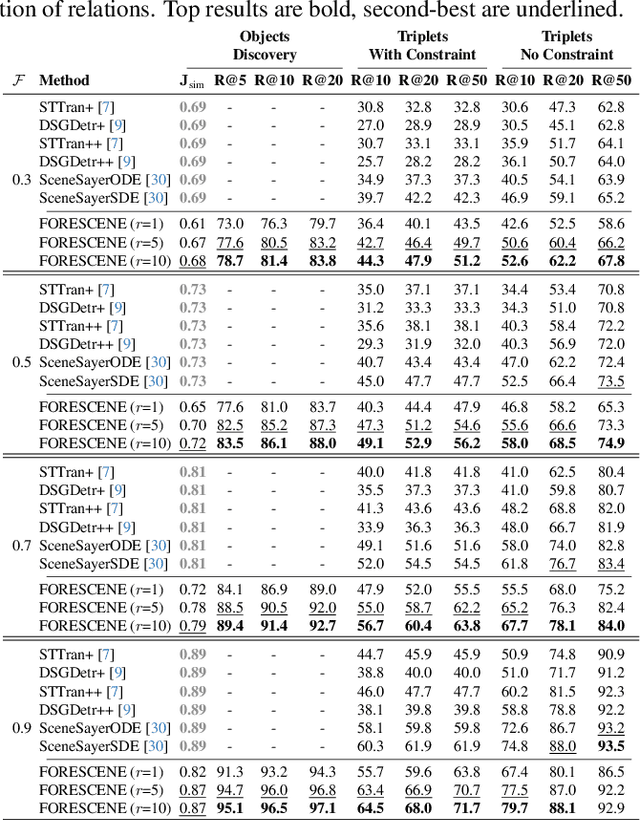
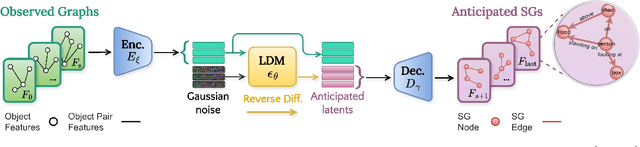
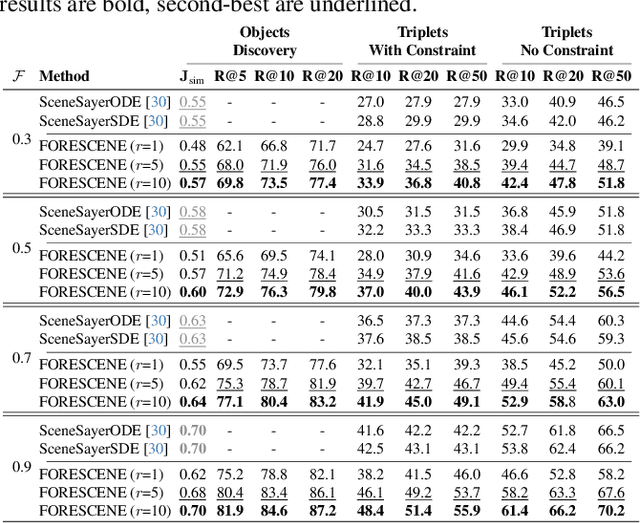
Forecasting human-environment interactions in daily activities is challenging due to the high variability of human behavior. While predicting directly from videos is possible, it is limited by confounding factors like irrelevant objects or background noise that do not contribute to the interaction. A promising alternative is using Scene Graphs (SGs) to track only the relevant elements. However, current methods for forecasting future SGs face significant challenges and often rely on unrealistic assumptions, such as fixed objects over time, limiting their applicability to long-term activities where interacted objects may appear or disappear. In this paper, we introduce FORESCENE, a novel framework for Scene Graph Anticipation (SGA) that predicts both object and relationship evolution over time. FORESCENE encodes observed video segments into a latent representation using a tailored Graph Auto-Encoder and forecasts future SGs using a Latent Diffusion Model (LDM). Our approach enables continuous prediction of interaction dynamics without making assumptions on the graph's content or structure. We evaluate FORESCENE on the Action Genome dataset, where it outperforms existing SGA methods while solving a significantly more complex task.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
Hier-EgoPack: Hierarchical Egocentric Video Understanding with Diverse Task Perspectives
Feb 04, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such a holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. A significant step in this direction is EgoPack, a unified framework for understanding human activities across diverse tasks with minimal overhead. EgoPack promotes information sharing and collaboration among downstream tasks, essential for efficiently learning new skills. In this paper, we introduce Hier-EgoPack, which advances EgoPack by enabling reasoning also across diverse temporal granularities, which expands its applicability to a broader range of downstream tasks. To achieve this, we propose a novel hierarchical architecture for temporal reasoning equipped with a GNN layer specifically designed to tackle the challenges of multi-granularity reasoning effectively. We evaluate our approach on multiple Ego4d benchmarks involving both clip-level and frame-level reasoning, demonstrating how our hierarchical unified architecture effectively solves these diverse tasks simultaneously.
A Backpack Full of Skills: Egocentric Video Understanding with Diverse Task Perspectives
Mar 05, 2024



Human comprehension of a video stream is naturally broad: in a few instants, we are able to understand what is happening, the relevance and relationship of objects, and forecast what will follow in the near future, everything all at once. We believe that - to effectively transfer such an holistic perception to intelligent machines - an important role is played by learning to correlate concepts and to abstract knowledge coming from different tasks, to synergistically exploit them when learning novel skills. To accomplish this, we seek for a unified approach to video understanding which combines shared temporal modelling of human actions with minimal overhead, to support multiple downstream tasks and enable cooperation when learning novel skills. We then propose EgoPack, a solution that creates a collection of task perspectives that can be carried across downstream tasks and used as a potential source of additional insights, as a backpack of skills that a robot can carry around and use when needed. We demonstrate the effectiveness and efficiency of our approach on four Ego4D benchmarks, outperforming current state-of-the-art methods.
PolyDiff: Generating 3D Polygonal Meshes with Diffusion Models
Dec 18, 2023We introduce PolyDiff, the first diffusion-based approach capable of directly generating realistic and diverse 3D polygonal meshes. In contrast to methods that use alternate 3D shape representations (e.g. implicit representations), our approach is a discrete denoising diffusion probabilistic model that operates natively on the polygonal mesh data structure. This enables learning of both the geometric properties of vertices and the topological characteristics of faces. Specifically, we treat meshes as quantized triangle soups, progressively corrupted with categorical noise in the forward diffusion phase. In the reverse diffusion phase, a transformer-based denoising network is trained to revert the noising process, restoring the original mesh structure. At inference, new meshes can be generated by applying this denoising network iteratively, starting with a completely noisy triangle soup. Consequently, our model is capable of producing high-quality 3D polygonal meshes, ready for integration into downstream 3D workflows. Our extensive experimental analysis shows that PolyDiff achieves a significant advantage (avg. FID and JSD improvement of 18.2 and 5.8 respectively) over current state-of-the-art methods.
MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers
Nov 27, 2023



We introduce MeshGPT, a new approach for generating triangle meshes that reflects the compactness typical of artist-created meshes, in contrast to dense triangle meshes extracted by iso-surfacing methods from neural fields. Inspired by recent advances in powerful large language models, we adopt a sequence-based approach to autoregressively generate triangle meshes as sequences of triangles. We first learn a vocabulary of latent quantized embeddings, using graph convolutions, which inform these embeddings of the local mesh geometry and topology. These embeddings are sequenced and decoded into triangles by a decoder, ensuring that they can effectively reconstruct the mesh. A transformer is then trained on this learned vocabulary to predict the index of the next embedding given previous embeddings. Once trained, our model can be autoregressively sampled to generate new triangle meshes, directly generating compact meshes with sharp edges, more closely imitating the efficient triangulation patterns of human-crafted meshes. MeshGPT demonstrates a notable improvement over state of the art mesh generation methods, with a 9% increase in shape coverage and a 30-point enhancement in FID scores across various categories.
OpenPatch: a 3D patchwork for Out-Of-Distribution detection
Oct 06, 2023



Moving deep learning models from the laboratory setting to the open world entails preparing them to handle unforeseen conditions. In several applications the occurrence of novel classes during deployment poses a significant threat, thus it is crucial to effectively detect them. Ideally, this skill should be used when needed without requiring any further computational training effort at every new task. Out-of-distribution detection has attracted significant attention in the last years, however the majority of the studies deal with 2D images ignoring the inherent 3D nature of the real-world and often confusing between domain and semantic novelty. In this work, we focus on the latter, considering the objects geometric structure captured by 3D point clouds regardless of the specific domain. We advance the field by introducing OpenPatch that builds on a large pre-trained model and simply extracts from its intermediate features a set of patch representations that describe each known class. For any new sample, we obtain a novelty score by evaluating whether it can be recomposed mainly by patches of a single known class or rather via the contribution of multiple classes. We present an extensive experimental evaluation of our approach for the task of semantic novelty detection on real-world point cloud samples when the reference known data are synthetic. We demonstrate that OpenPatch excels in both the full and few-shot known sample scenarios, showcasing its robustness across varying pre-training objectives and network backbones. The inherent training-free nature of our method allows for its immediate application to a wide array of real-world tasks, offering a compelling advantage over approaches that need expensive retraining efforts.
Towards Open Set 3D Learning: A Benchmark on Object Point Clouds
Jul 23, 2022
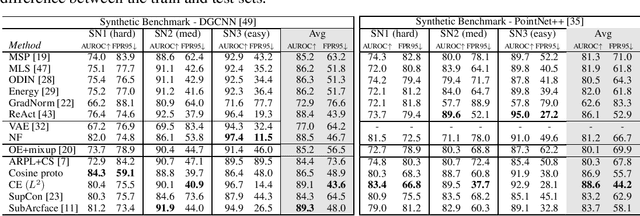


In the last years, there has been significant progress in the field of 3D learning on classification, detection and segmentation problems. The vast majority of the existing studies focus on canonical closed-set conditions, neglecting the intrinsic open nature of the real-world. This limits the abilities of autonomous systems involved in safety-critical applications that require managing novel and unknown signals. In this context exploiting 3D data can be a valuable asset since it conveys rich information about the geometry of sensed objects and scenes. This paper provides the first broad study on Open Set 3D learning. We introduce a novel testbed with settings of increasing difficulty in terms of category semantic shift and cover both in-domain (synthetic-to-synthetic) and cross-domain (synthetic-to-real) scenarios. Moreover, we investigate the related out-of-distribution and Open Set 2D literature to understand if and how their most recent approaches are effective on 3D data. Our extensive benchmark positions several algorithms in the same coherent picture, revealing their strengths and limitations. The results of our analysis may serve as a reliable foothold for future tailored Open Set 3D models.
End-to-End Learning to Grasp from Object Point Clouds
Mar 10, 2022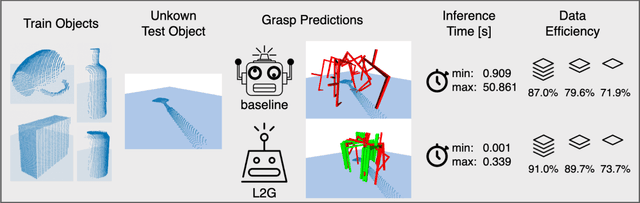
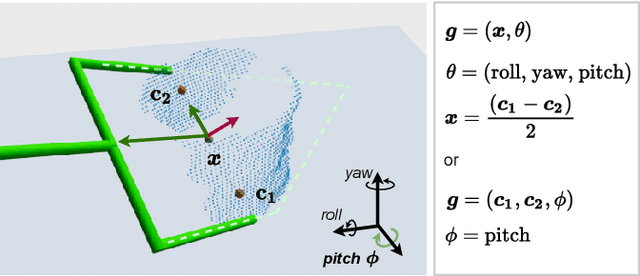
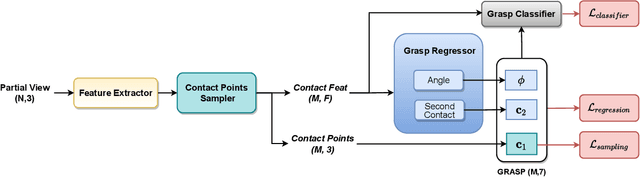
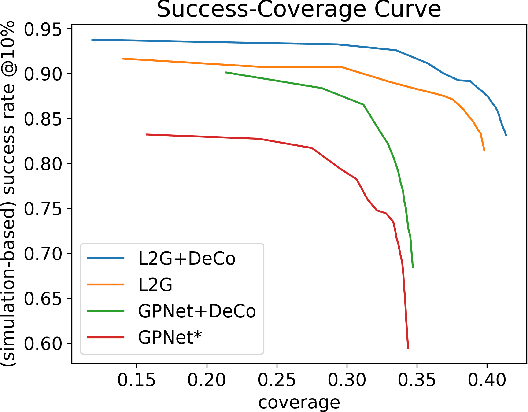
The ability to grasp objects is an essential skill that enables many robotic manipulation tasks. Recent works have studied point cloud-based methods for object grasping by starting from simulated datasets and have shown promising performance in real-world scenarios. Nevertheless, many of them still strongly rely on ad-hoc geometric heuristics to generate grasp candidates, which fail to generalize to objects with significantly different shapes with respect to those observed during training. Moreover, these methods are generally inefficient with respect to the number of training samples and the time needed during deployment. In this paper, we propose an end-to-end learning solution to generate 6-DOF parallel-jaw grasps starting from the partial view of the object. Our Learning to Grasp (L2G) method takes as input object point clouds and is guided by a principled multi-task optimization objective that generates a diverse set of grasps combining contact point sampling, grasp regression, and grasp evaluation. With a thorough experimental analysis, we show the effectiveness of the proposed method as well as its robustness and generalization abilities.