 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORESCENE: FOREcasting human activity via latent SCENE graphs diffusion
Paper and Code
Mar 08, 2025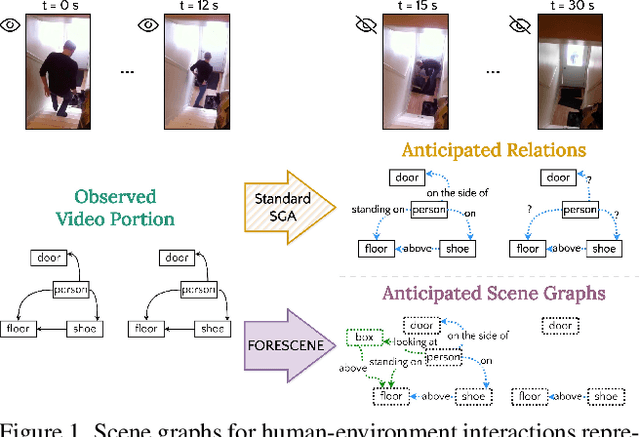
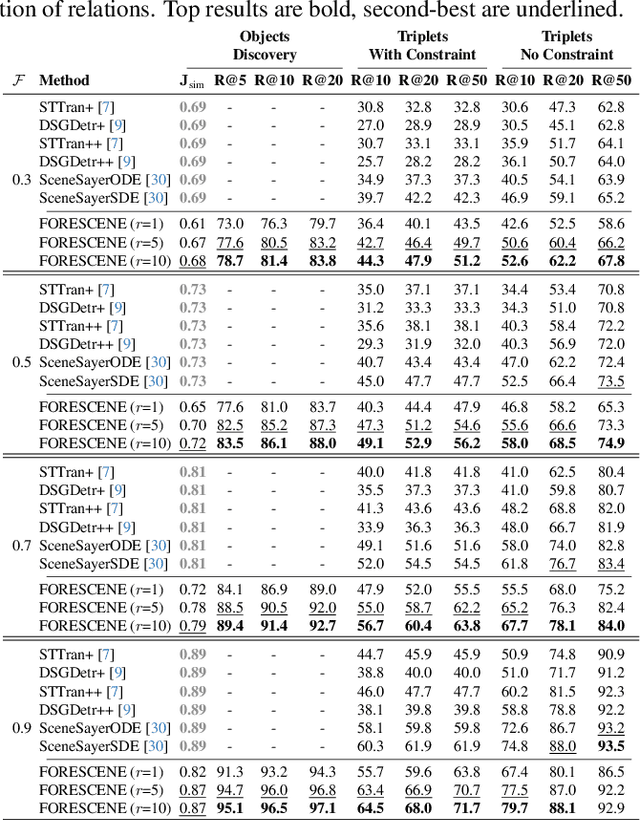
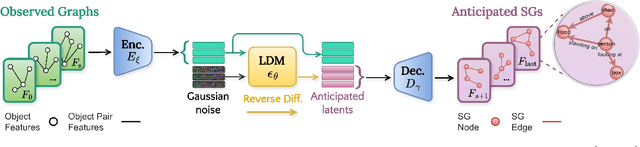
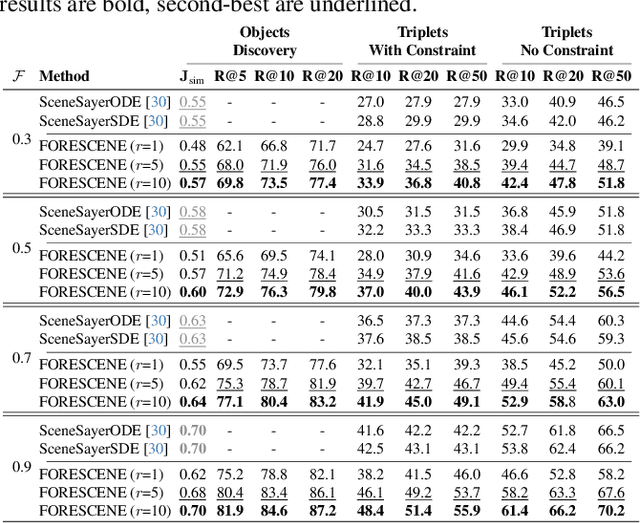
Forecasting human-environment interactions in daily activities is challenging due to the high variability of human behavior. While predicting directly from videos is possible, it is limited by confounding factors like irrelevant objects or background noise that do not contribute to the interaction. A promising alternative is using Scene Graphs (SGs) to track only the relevant elements. However, current methods for forecasting future SGs face significant challenges and often rely on unrealistic assumptions, such as fixed objects over time, limiting their applicability to long-term activities where interacted objects may appear or disappear. In this paper, we introduce FORESCENE, a novel framework for Scene Graph Anticipation (SGA) that predicts both object and relationship evolution over time. FORESCENE encodes observed video segments into a latent representation using a tailored Graph Auto-Encoder and forecasts future SGs using a Latent Diffusion Model (LDM). Our approach enables continuous prediction of interaction dynamics without making assumptions on the graph's content or structure. We evaluate FORESCENE on the Action Genome dataset, where it outperforms existing SGA methods while solving a significantly more complex task.