 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning reusable concepts across different egocentric video understanding tasks
May 30, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. In this paper, we introduce Hier-EgoPack, a unified framework able to create a collection of task perspectives that can be carried across downstream tasks and used as a potential source of additional insights, as a backpack of skills that a robot can carry around and use when needed.
SANSA: Unleashing the Hidden Semantics in SAM2 for Few-Shot Segmentation
May 27, 2025Few-shot segmentation aims to segment unseen object categories from just a handful of annotated examples. This requires mechanisms that can both identify semantically related objects across images and accurately produce segmentation masks. We note that Segment Anything 2 (SAM2), with its prompt-and-propagate mechanism, offers both strong segmentation capabilities and a built-in feature matching process. However, we show that its representations are entangled with task-specific cues optimized for object tracking, which impairs its use for tasks requiring higher level semantic understanding. Our key insight is that, despite its class-agnostic pretraining, SAM2 already encodes rich semantic structure in its features. We propose SANSA (Semantically AligNed Segment Anything 2), a framework that makes this latent structure explicit, and repurposes SAM2 for few-shot segmentation through minimal task-specific modifications. SANSA achieves state-of-the-art performance on few-shot segmentation benchmarks specifically designed to assess generalization, outperforms generalist methods in the popular in-context setting, supports various prompts flexible interaction via points, boxes, or scribbles, and remains significantly faster and more compact than prior approaches. Code is available at https://github.com/ClaudiaCuttano/SANSA.
HiERO: understanding the hierarchy of human behavior enhances reasoning on egocentric videos
May 19, 2025Human activities are particularly complex and variable, and this makes challenging for deep learning models to reason about them. However, we note that such variability does have an underlying structure, composed of a hierarchy of patterns of related actions. We argue that such structure can emerge naturally from unscripted videos of human activities, and can be leveraged to better reason about their content. We present HiERO, a weakly-supervised method to enrich video segments features with the corresponding hierarchical activity threads. By aligning video clips with their narrated descriptions, HiERO infers contextual, semantic and temporal reasoning with an hierarchical architecture. We prove the potential of our enriched features with multiple video-text alignment benchmarks (EgoMCQ, EgoNLQ) with minimal additional training, and in zero-shot for procedure learning tasks (EgoProceL and Ego4D Goal-Step). Notably, HiERO achieves state-of-the-art performance in all the benchmarks, and for procedure learning tasks it outperforms fully-supervised methods by a large margin (+12.5% F1 on EgoProceL) in zero shot. Our results prove the relevance of using knowledge of the hierarchy of human activities for multiple reasoning tasks in egocentric vision.
Sim-is-More: Randomizing HW-NAS with Synthetic Devices
Apr 01, 2025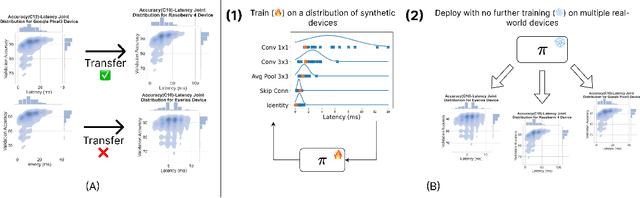
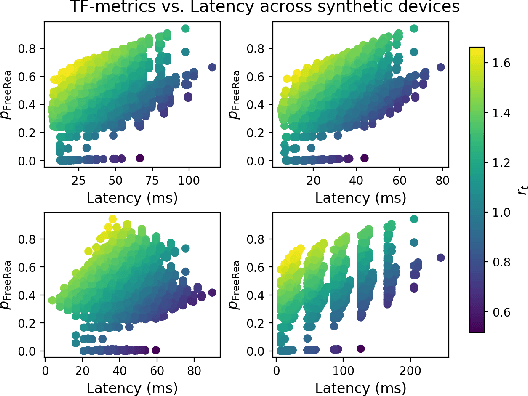
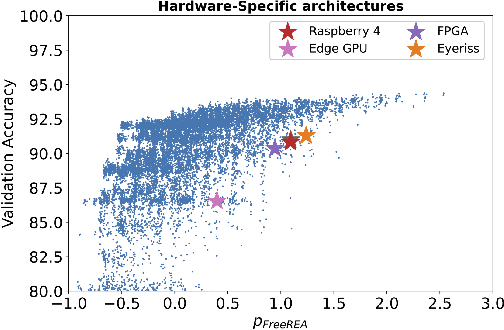
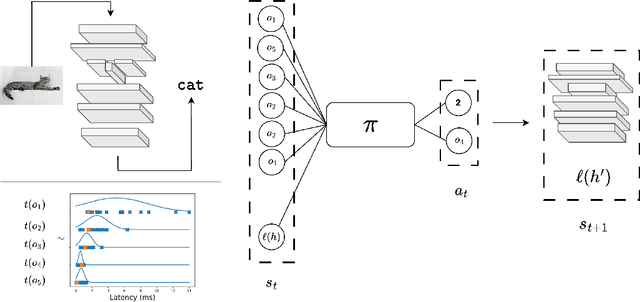
Existing hardware-aware NAS (HW-NAS) methods typically assume access to precise information circa the target device, either via analytical approximations of the post-compilation latency model, or through learned latency predictors. Such approximate approaches risk introducing estimation errors that may prove detrimental in risk-sensitive applications. In this work, we propose a two-stage HW-NAS framework, in which we first learn an architecture controller on a distribution of synthetic devices, and then directly deploy the controller on a target device. At test-time, our network controller deploys directly to the target device without relying on any pre-collected information, and only exploits direct interactions. In particular, the pre-training phase on synthetic devices enables the controller to design an architecture for the target device by interacting with it through a small number of high-fidelity latency measurements. To guarantee accessibility of our method, we only train our controller with training-free accuracy proxies, allowing us to scale the meta-training phase without incurring the overhead of full network training. We benchmark on HW-NATS-Bench, demonstrating that our method generalizes to unseen devices and searches for latency-efficient architectures by in-context adaptation using only a few real-world latency evaluations at test-time.
Your ViT is Secretly an Image Segmentation Model
Mar 24, 2025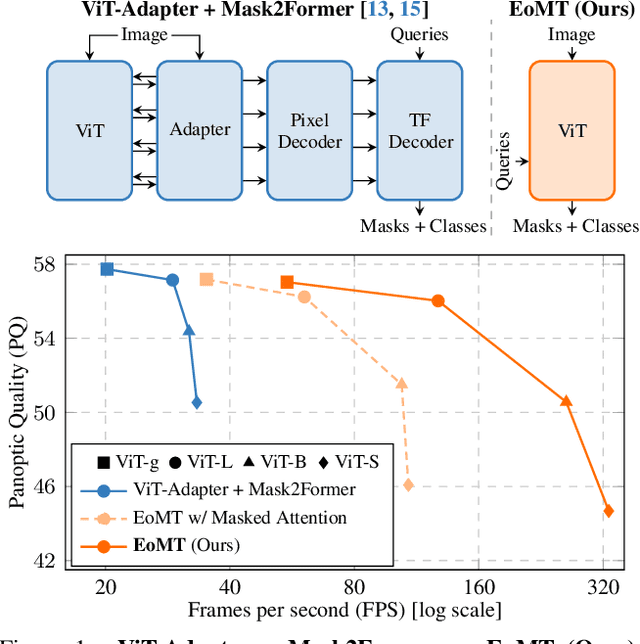
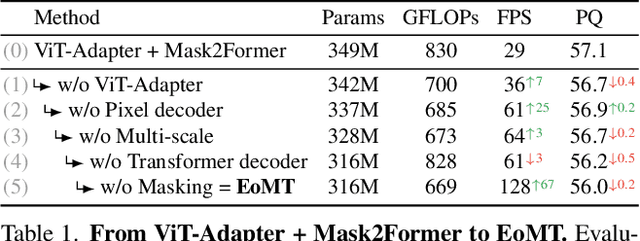
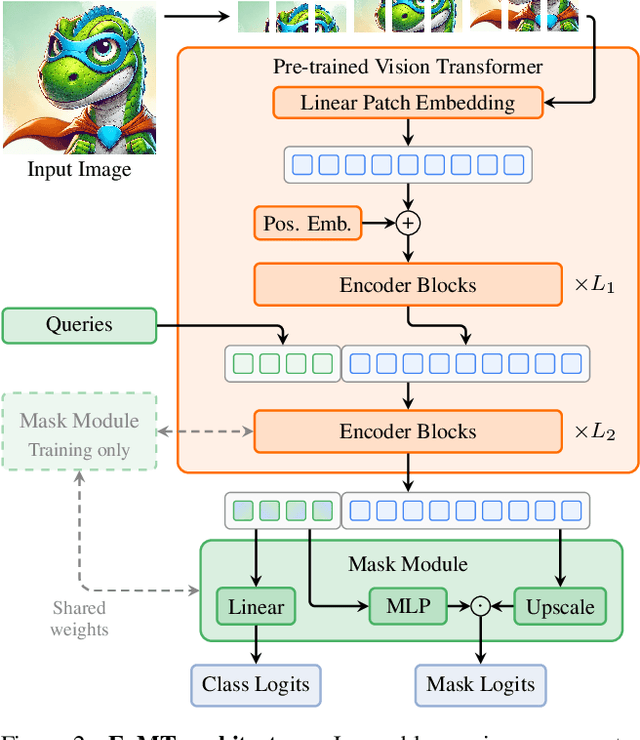
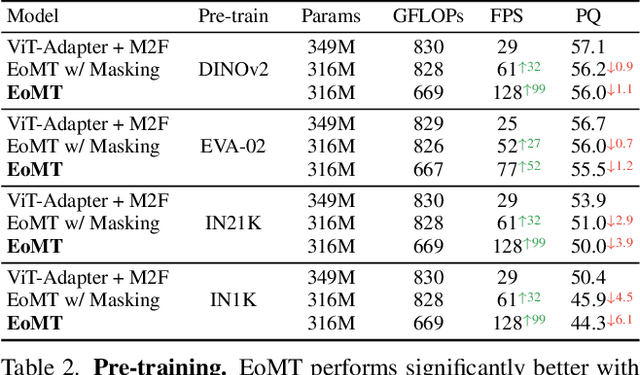
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4x faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.
FORESCENE: FOREcasting human activity via latent SCENE graphs diffusion
Mar 08, 2025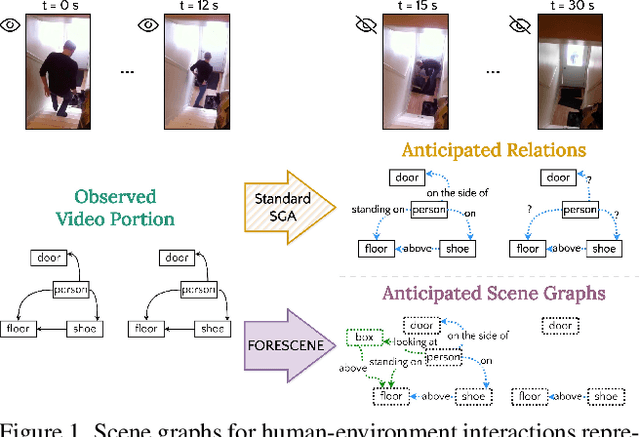
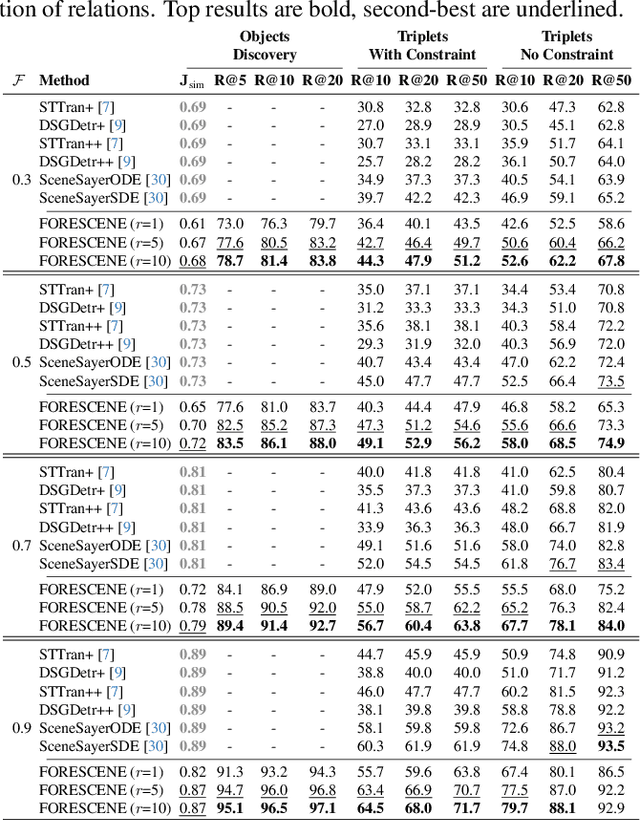
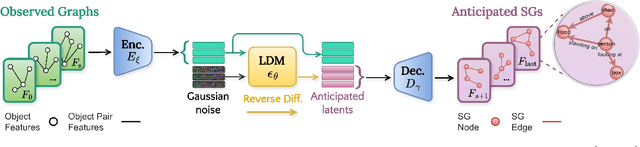
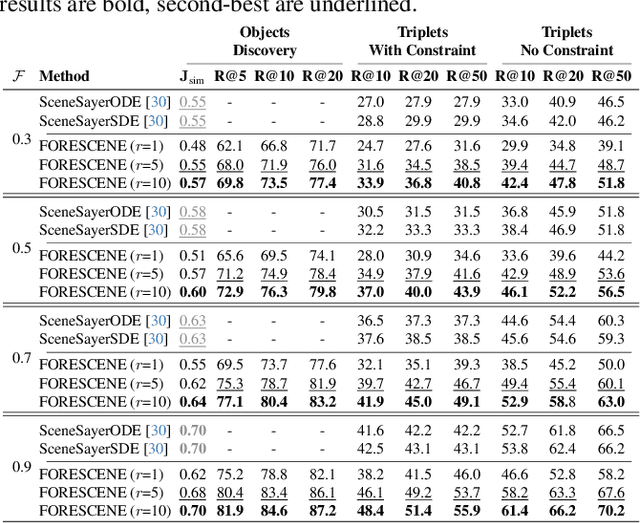
Forecasting human-environment interactions in daily activities is challenging due to the high variability of human behavior. While predicting directly from videos is possible, it is limited by confounding factors like irrelevant objects or background noise that do not contribute to the interaction. A promising alternative is using Scene Graphs (SGs) to track only the relevant elements. However, current methods for forecasting future SGs face significant challenges and often rely on unrealistic assumptions, such as fixed objects over time, limiting their applicability to long-term activities where interacted objects may appear or disappear. In this paper, we introduce FORESCENE, a novel framework for Scene Graph Anticipation (SGA) that predicts both object and relationship evolution over time. FORESCENE encodes observed video segments into a latent representation using a tailored Graph Auto-Encoder and forecasts future SGs using a Latent Diffusion Model (LDM). Our approach enables continuous prediction of interaction dynamics without making assumptions on the graph's content or structure. We evaluate FORESCENE on the Action Genome dataset, where it outperforms existing SGA methods while solving a significantly more complex task.
Hier-EgoPack: Hierarchical Egocentric Video Understanding with Diverse Task Perspectives
Feb 04, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such a holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. A significant step in this direction is EgoPack, a unified framework for understanding human activities across diverse tasks with minimal overhead. EgoPack promotes information sharing and collaboration among downstream tasks, essential for efficiently learning new skills. In this paper, we introduce Hier-EgoPack, which advances EgoPack by enabling reasoning also across diverse temporal granularities, which expands its applicability to a broader range of downstream tasks. To achieve this, we propose a novel hierarchical architecture for temporal reasoning equipped with a GNN layer specifically designed to tackle the challenges of multi-granularity reasoning effectively. We evaluate our approach on multiple Ego4d benchmarks involving both clip-level and frame-level reasoning, demonstrating how our hierarchical unified architecture effectively solves these diverse tasks simultaneously.
SAMWISE: Infusing wisdom in SAM2 for Text-Driven Video Segmentation
Nov 26, 2024



Referring Video Object Segmentation (RVOS) relies on natural language expressions to segment an object in a video clip. Existing methods restrict reasoning either to independent short clips, losing global context, or process the entire video offline, impairing their application in a streaming fashion. In this work, we aim to surpass these limitations and design an RVOS method capable of effectively operating in streaming-like scenarios while retaining contextual information from past frames. We build upon the Segment-Anything 2 (SAM2) model, that provides robust segmentation and tracking capabilities and is naturally suited for streaming processing. We make SAM2 wiser, by empowering it with natural language understanding and explicit temporal modeling at the feature extraction stage, without fine-tuning its weights, and without outsourcing modality interaction to external models. To this end, we introduce a novel adapter module that injects temporal information and multi-modal cues in the feature extraction process. We further reveal the phenomenon of tracking bias in SAM2 and propose a learnable module to adjust its tracking focus when the current frame features suggest a new object more aligned with the caption. Our proposed method, SAMWISE, achieves state-of-the-art across various benchmarks, by adding a negligible overhead of just 4.2 M parameters. The code is available at https://github.com/ClaudiaCuttano/SAMWISE
Select2Plan: Training-Free ICL-Based Planning through VQA and Memory Retrieval
Nov 06, 2024This study explores the potential of off-the-shelf Vision-Language Models (VLMs) for high-level robot planning in the context of autonomous navigation. Indeed, while most of existing learning-based approaches for path planning require extensive task-specific training/fine-tuning, we demonstrate how such training can be avoided for most practical cases. To do this, we introduce Select2Plan (S2P), a novel training-free framework for high-level robot planning which completely eliminates the need for fine-tuning or specialised training. By leveraging structured Visual Question-Answering (VQA) and In-Context Learning (ICL), our approach drastically reduces the need for data collection, requiring a fraction of the task-specific data typically used by trained models, or even relying only on online data. Our method facilitates the effective use of a generally trained VLM in a flexible and cost-efficient way, and does not require additional sensing except for a simple monocular camera. We demonstrate its adaptability across various scene types, context sources, and sensing setups. We evaluate our approach in two distinct scenarios: traditional First-Person View (FPV) and infrastructure-driven Third-Person View (TPV) navigation, demonstrating the flexibility and simplicity of our method. Our technique significantly enhances the navigational capabilities of a baseline VLM of approximately 50% in TPV scenario, and is comparable to trained models in the FPV one, with as few as 20 demonstrations.
Egocentric zone-aware action recognition across environments
Sep 21, 2024



Human activities exhibit a strong correlation between actions and the places where these are performed, such as washing something at a sink. More specifically, in daily living environments we may identify particular locations, hereinafter named activity-centric zones, which may afford a set of homogeneous actions. Their knowledge can serve as a prior to favor vision models to recognize human activities. However, the appearance of these zones is scene-specific, limiting the transferability of this prior information to unfamiliar areas and domains. This problem is particularly relevant in egocentric vision, where the environment takes up most of the image, making it even more difficult to separate the action from the context. In this paper, we discuss the importance of decoupling the domain-specific appearance of activity-centric zones from their universal, domain-agnostic representations, and show how the latter can improve the cross-domain transferability of Egocentric Action Recognition (EAR) models. We validate our solution on the EPIC-Kitchens-100 and Argo1M datasets