 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Learning: A Tutorial
Oct 14, 2025


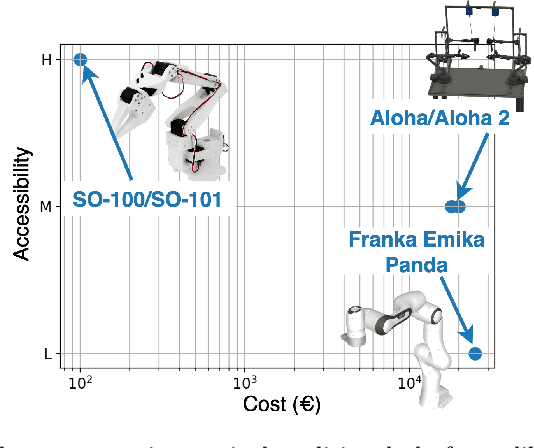
Robot learning is at an inflection point, driven by rapid advancements in machine learning and the growing availability of large-scale robotics data. This shift from classical, model-based methods to data-driven, learning-based paradigms is unlocking unprecedented capabilities in autonomous systems. This tutorial navigates the landscape of modern robot learning, charting a course from the foundational principles of Reinforcement Learning and Behavioral Cloning to generalist, language-conditioned models capable of operating across diverse tasks and even robot embodiments. This work is intended as a guide for researchers and practitioners, and our goal is to equip the reader with the conceptual understanding and practical tools necessary to contribute to developments in robot learning, with ready-to-use examples implemented in $\texttt{lerobot}$.
Sim-is-More: Randomizing HW-NAS with Synthetic Devices
Apr 01, 2025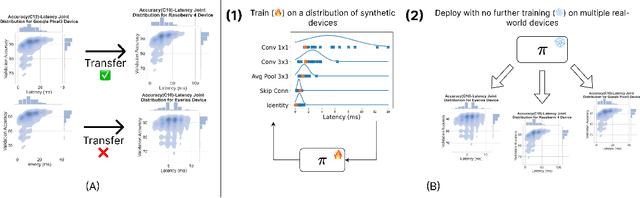
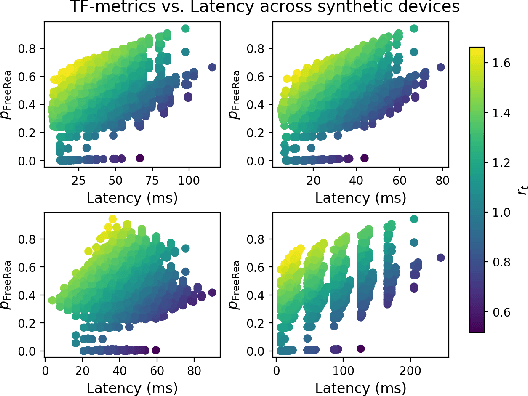
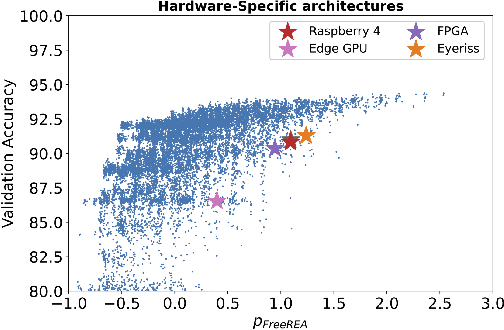
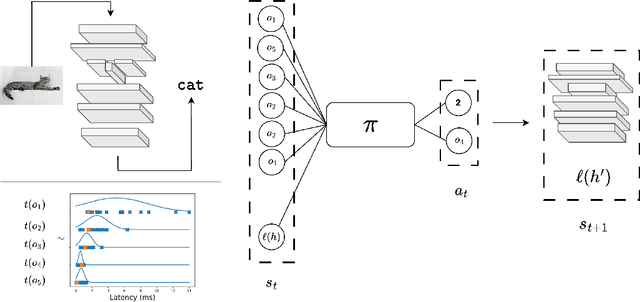
Existing hardware-aware NAS (HW-NAS) methods typically assume access to precise information circa the target device, either via analytical approximations of the post-compilation latency model, or through learned latency predictors. Such approximate approaches risk introducing estimation errors that may prove detrimental in risk-sensitive applications. In this work, we propose a two-stage HW-NAS framework, in which we first learn an architecture controller on a distribution of synthetic devices, and then directly deploy the controller on a target device. At test-time, our network controller deploys directly to the target device without relying on any pre-collected information, and only exploits direct interactions. In particular, the pre-training phase on synthetic devices enables the controller to design an architecture for the target device by interacting with it through a small number of high-fidelity latency measurements. To guarantee accessibility of our method, we only train our controller with training-free accuracy proxies, allowing us to scale the meta-training phase without incurring the overhead of full network training. We benchmark on HW-NATS-Bench, demonstrating that our method generalizes to unseen devices and searches for latency-efficient architectures by in-context adaptation using only a few real-world latency evaluations at test-time.
TempoRL: laser pulse temporal shape optimization with Deep Reinforcement Learning
Apr 20, 2023High Power Laser's (HPL) optimal performance is essential for the success of a wide variety of experimental tasks related to light-matter interactions. Traditionally, HPL parameters are optimised in an automated fashion relying on black-box numerical methods. However, these can be demanding in terms of computational resources and usually disregard transient and complex dynamics. Model-free Deep Reinforcement Learning (DRL) offers a promising alternative framework for optimising HPL performance since it allows to tune the control parameters as a function of system states subject to nonlinear temporal dynamics without requiring an explicit dynamics model of those. Furthermore, DRL aims to find an optimal control policy rather than a static parameter configuration, particularly suitable for dynamic processes involving sequential decision-making. This is particularly relevant as laser systems are typically characterised by dynamic rather than static traits. Hence the need for a strategy to choose the control applied based on the current context instead of one single optimal control configuration. This paper investigates the potential of DRL in improving the efficiency and safety of HPL control systems. We apply this technique to optimise the temporal profile of laser pulses in the L1 pump laser hosted at the ELI Beamlines facility. We show how to adapt DRL to the setting of spectral phase control by solely tuning dispersion coefficients of the spectral phase and reaching pulses similar to transform limited with full-width at half-maximum (FWHM) of ca1.6 ps.