 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-Efficient Video Pre-training with Frozen Image Foundation Models
May 18, 2026Video foundation models achieve strong performance across many video understanding tasks, but typically require large-scale pre-training on massive video datasets, resulting in substantial data and compute costs. In contrast, modern image foundation models already provide powerful spatial representations. This raises an important question: can competitive video models be built by reusing these spatial representations and pre-training only for temporal reasoning? We take initial steps toward exploring a lightweight training paradigm that freezes a pre-trained image foundation model and trains only a recurrent temporal module to process streaming video. By reusing an image foundation model as a spatial encoder, this approach could significantly reduce the amount of video data and compute required compared to end-to-end video pre-training. In this work, we explore the feasibility of this approach before investing in computing for video pre-training. Our empirical findings across multiple video understanding tasks suggest that strong temporal performance can emerge without large-scale video pre-training, motivating future work on recurrent video foundation models obtained by pre-training a temporal module on top of a frozen image foundation model. Code: https://github.com/tue-mps/towards-video-image-frozen .
Orion-Lite: Distilling LLM Reasoning into Efficient Vision-Only Driving Models
Apr 09, 2026Leveraging the general world knowledge of Large Language Models (LLMs) holds significant promise for improving the ability of autonomous driving systems to handle rare and complex scenarios. While integrating LLMs into Vision-Language-Action (VLA) models has yielded state-of-the-art performance, their massive parameter counts pose severe challenges for latency-sensitive and energy-efficient deployment. Distilling LLM knowledge into a compact driving model offers a compelling solution to retain these reasoning capabilities while maintaining a manageable computational footprint. Although previous works have demonstrated the efficacy of distillation, these efforts have primarily focused on relatively simple scenarios and open-loop evaluations. Therefore, in this work, we investigate LLM distillation in more complex, interactive scenarios under closed-loop evaluation. We demonstrate that through a combination of latent feature distillation and ground-truth trajectory supervision, an efficient vision-only student model \textbf{Orion-Lite} can even surpass the performance of its massive VLA teacher, ORION. Setting a new state-of-the-art on the rigorous Bench2Drive benchmark, with a Driving Score of 80.6. Ultimately, this reveals that vision-only architectures still possess significant, untapped potential for high-performance reactive planning.
PMT: Plain Mask Transformer for Image and Video Segmentation with Frozen Vision Encoders
Mar 26, 2026Vision Foundation Models (VFMs) pre-trained at scale enable a single frozen encoder to serve multiple downstream tasks simultaneously. Recent VFM-based encoder-only models for image and video segmentation, such as EoMT and VidEoMT, achieve competitive accuracy with remarkably low latency, yet they require finetuning the encoder, sacrificing the multi-task encoder sharing that makes VFMs practically attractive for large-scale deployment. To reconcile encoder-only simplicity and speed with frozen VFM features, we propose the Plain Mask Decoder (PMD), a fast Transformer-based segmentation decoder that operates on top of frozen VFM features. The resulting model, the Plain Mask Transformer (PMT), preserves the architectural simplicity and low latency of encoder-only designs while keeping the encoder representation unchanged and shareable. The design seamlessly applies to both image and video segmentation, inheriting the generality of the encoder-only framework. On standard image segmentation benchmarks, PMT matches the frozen-encoder state of the art while running up to ~3x faster. For video segmentation, it even performs on par with fully finetuned methods, while being up to 8x faster than state-of-the-art frozen-encoder models. Code: https://github.com/tue-mps/pmt.
Sim-is-More: Randomizing HW-NAS with Synthetic Devices
Apr 01, 2025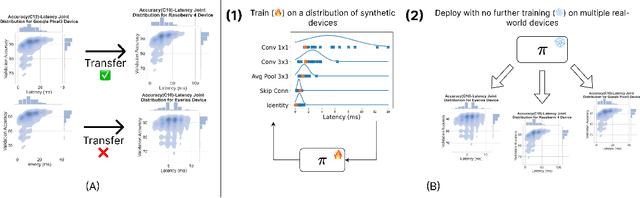
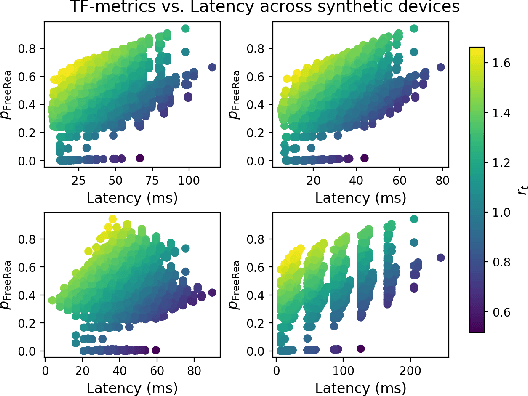
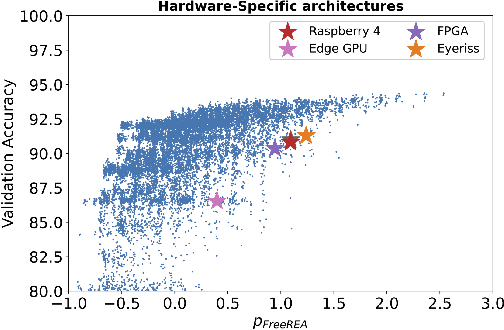
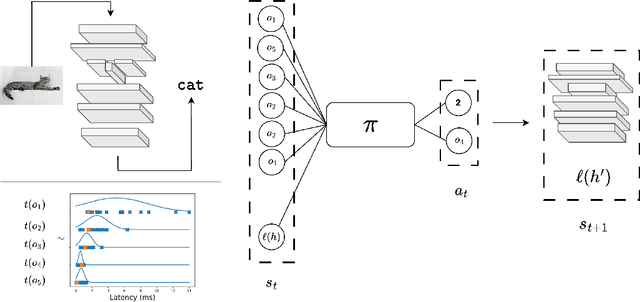
Existing hardware-aware NAS (HW-NAS) methods typically assume access to precise information circa the target device, either via analytical approximations of the post-compilation latency model, or through learned latency predictors. Such approximate approaches risk introducing estimation errors that may prove detrimental in risk-sensitive applications. In this work, we propose a two-stage HW-NAS framework, in which we first learn an architecture controller on a distribution of synthetic devices, and then directly deploy the controller on a target device. At test-time, our network controller deploys directly to the target device without relying on any pre-collected information, and only exploits direct interactions. In particular, the pre-training phase on synthetic devices enables the controller to design an architecture for the target device by interacting with it through a small number of high-fidelity latency measurements. To guarantee accessibility of our method, we only train our controller with training-free accuracy proxies, allowing us to scale the meta-training phase without incurring the overhead of full network training. We benchmark on HW-NATS-Bench, demonstrating that our method generalizes to unseen devices and searches for latency-efficient architectures by in-context adaptation using only a few real-world latency evaluations at test-time.
Your ViT is Secretly an Image Segmentation Model
Mar 24, 2025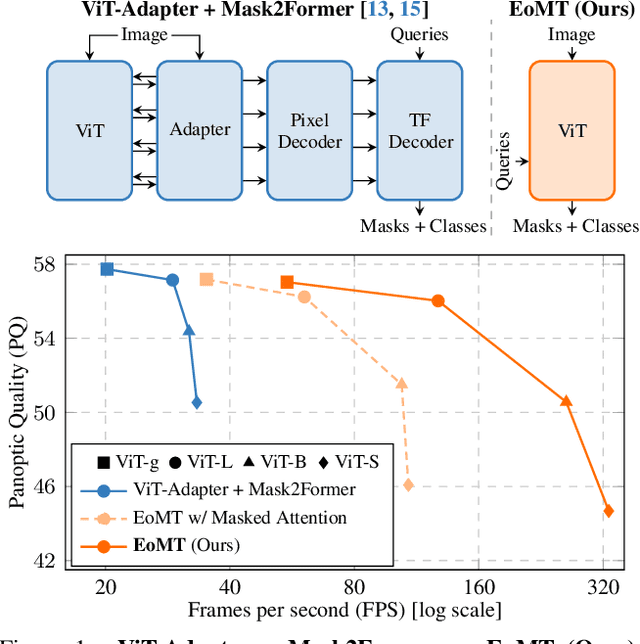
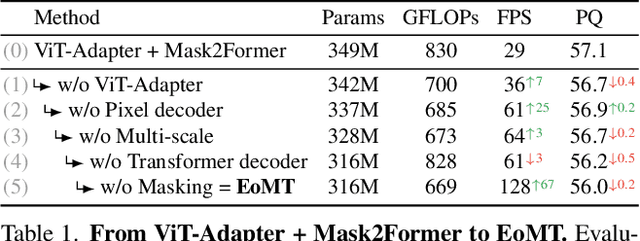
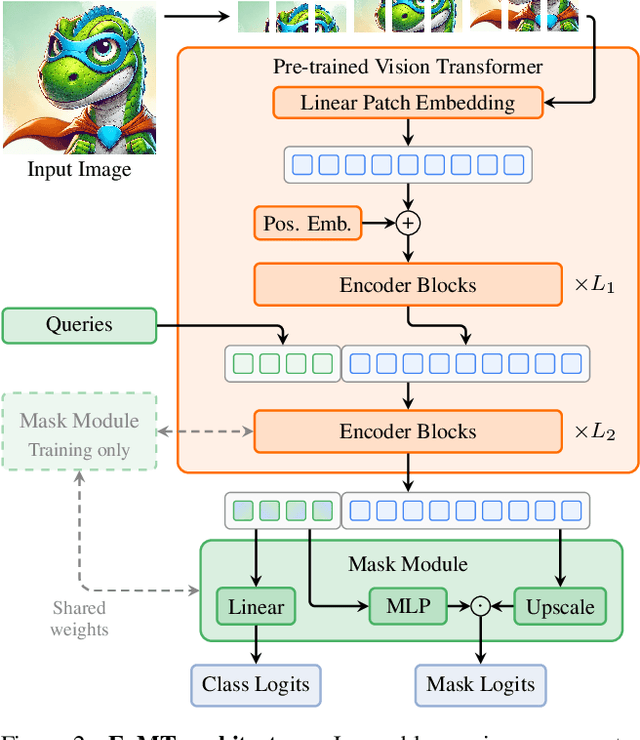
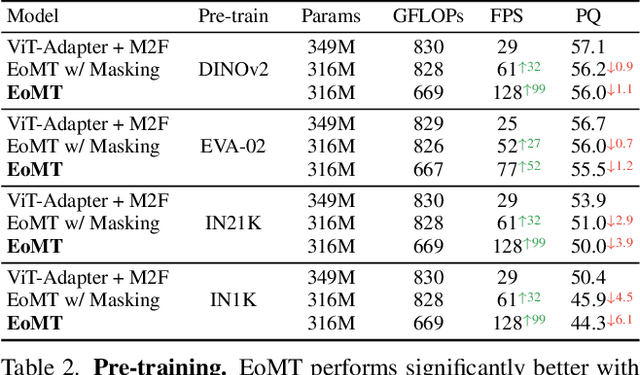
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4x faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.
Transient Fault Tolerant Semantic Segmentation for Autonomous Driving
Aug 30, 2024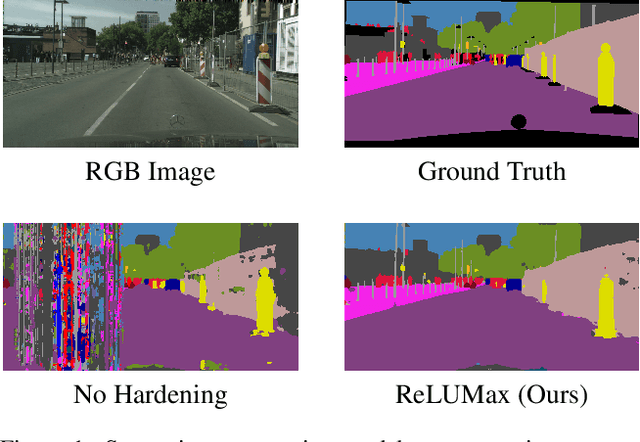
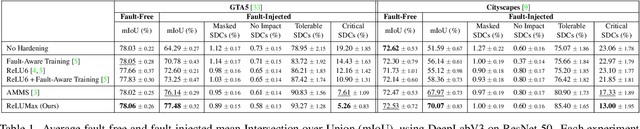
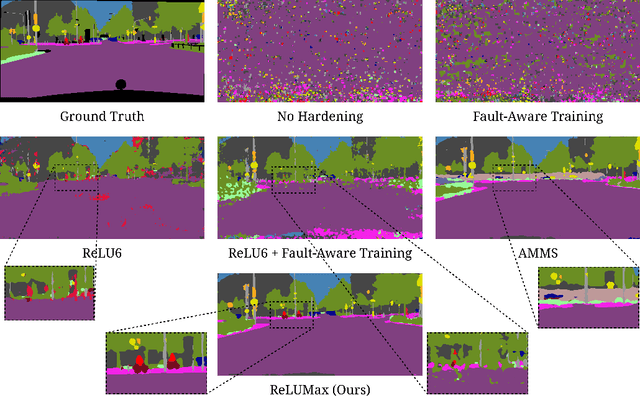

Deep learning models are crucial for autonomous vehicle perception, but their reliability is challenged by algorithmic limitations and hardware faults. We address the latter by examining fault-tolerance in semantic segmentation models. Using established hardware fault models, we evaluate existing hardening techniques both in terms of accuracy and uncertainty and introduce ReLUMax, a novel simple activation function designed to enhance resilience against transient faults. ReLUMax integrates seamlessly into existing architectures without time overhead. Our experiments demonstrate that ReLUMax effectively improves robustness, preserving performance and boosting prediction confidence, thus contributing to the development of reliable autonomous driving systems.
The revenge of BiSeNet: Efficient Multi-Task Image Segmentation
Apr 15, 2024Recent advancements in image segmentation have focused on enhancing the efficiency of the models to meet the demands of real-time applications, especially on edge devices. However, existing research has primarily concentrated on single-task settings, especially on semantic segmentation, leading to redundant efforts and specialized architectures for different tasks. To address this limitation, we propose a novel architecture for efficient multi-task image segmentation, capable of handling various segmentation tasks without sacrificing efficiency or accuracy. We introduce BiSeNetFormer, that leverages the efficiency of two-stream semantic segmentation architectures and it extends them into a mask classification framework. Our approach maintains the efficient spatial and context paths to capture detailed and semantic information, respectively, while leveraging an efficient transformed-based segmentation head that computes the binary masks and class probabilities. By seamlessly supporting multiple tasks, namely semantic and panoptic segmentation, BiSeNetFormer offers a versatile solution for multi-task segmentation. We evaluate our approach on popular datasets, Cityscapes and ADE20K, demonstrating impressive inference speeds while maintaining competitive accuracy compared to state-of-the-art architectures. Our results indicate that BiSeNetFormer represents a significant advancement towards fast, efficient, and multi-task segmentation networks, bridging the gap between model efficiency and task adaptability.
PEM: Prototype-based Efficient MaskFormer for Image Segmentation
Mar 01, 2024



Recent transformer-based architectures have shown impressive results in the field of image segmentation. Thanks to their flexibility, they obtain outstanding performance in multiple segmentation tasks, such as semantic and panoptic, under a single unified framework. To achieve such impressive performance, these architectures employ intensive operations and require substantial computational resources, which are often not available, especially on edge devices. To fill this gap, we propose Prototype-based Efficient MaskFormer (PEM), an efficient transformer-based architecture that can operate in multiple segmentation tasks. PEM proposes a novel prototype-based cross-attention which leverages the redundancy of visual features to restrict the computation and improve the efficiency without harming the performance. In addition, PEM introduces an efficient multi-scale feature pyramid network, capable of extracting features that have high semantic content in an efficient way, thanks to the combination of deformable convolutions and context-based self-modulation. We benchmark the proposed PEM architecture on two tasks, semantic and panoptic segmentation, evaluated on two different datasets, Cityscapes and ADE20K. PEM demonstrates outstanding performance on every task and dataset, outperforming task-specific architectures while being comparable and even better than computationally-expensive baselines.
Entropic Score metric: Decoupling Topology and Size in Training-free NAS
Oct 06, 2023



Neural Networks design is a complex and often daunting task, particularly for resource-constrained scenarios typical of mobile-sized models. Neural Architecture Search is a promising approach to automate this process, but existing competitive methods require large training time and computational resources to generate accurate models. To overcome these limits, this paper contributes with: i) a novel training-free metric, named Entropic Score, to estimate model expressivity through the aggregated element-wise entropy of its activations; ii) a cyclic search algorithm to separately yet synergistically search model size and topology. Entropic Score shows remarkable ability in searching for the topology of the network, and a proper combination with LogSynflow, to search for model size, yields superior capability to completely design high-performance Hybrid Transformers for edge applications in less than 1 GPU hour, resulting in the fastest and most accurate NAS method for ImageNet classification.
Fault-Aware Design and Training to Enhance DNNs Reliability with Zero-Overhead
May 28, 2022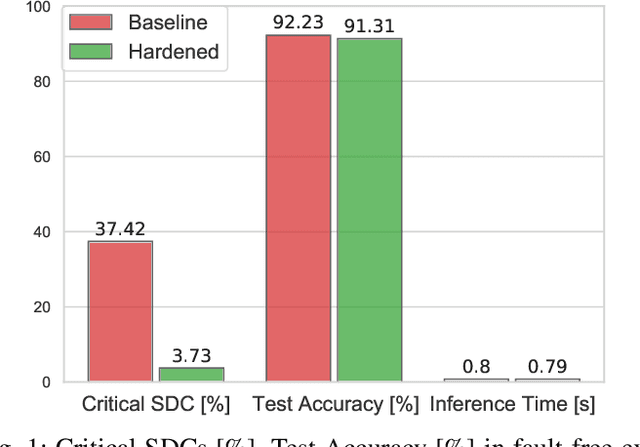
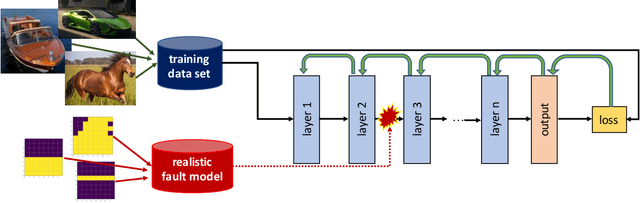
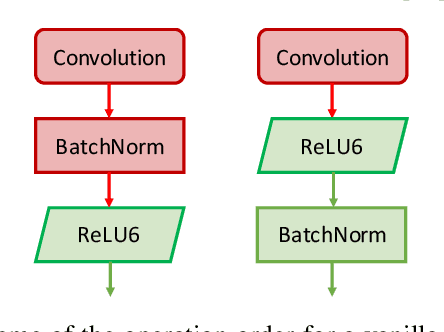
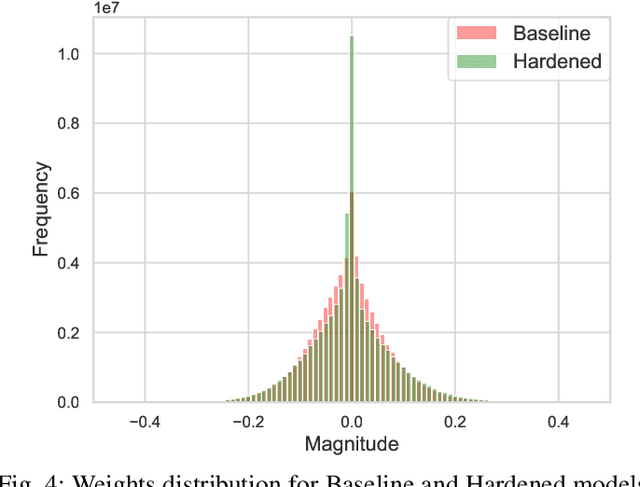
Deep Neural Networks (DNNs) enable a wide series of technological advancements, ranging from clinical imaging, to predictive industrial maintenance and autonomous driving. However, recent findings indicate that transient hardware faults may corrupt the models prediction dramatically. For instance, the radiation-induced misprediction probability can be so high to impede a safe deployment of DNNs models at scale, urging the need for efficient and effective hardening solutions. In this work, we propose to tackle the reliability issue both at training and model design time. First, we show that vanilla models are highly affected by transient faults, that can induce a performances drop up to 37%. Hence, we provide three zero-overhead solutions, based on DNN re-design and re-train, that can improve DNNs reliability to transient faults up to one order of magnitude. We complement our work with extensive ablation studies to quantify the gain in performances of each hardening component.