 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Law of Data Reconstruction for Random Features (and Beyond)
Sep 26, 2025



Large-scale deep learning models are known to memorize parts of the training set. In machine learning theory, memorization is often framed as interpolation or label fitting, and classical results show that this can be achieved when the number of parameters $p$ in the model is larger than the number of training samples $n$. In this work, we consider memorization from the perspective of data reconstruction, demonstrating that this can be achieved when $p$ is larger than $dn$, where $d$ is the dimensionality of the data. More specifically, we show that, in the random features model, when $p \gg dn$, the subspace spanned by the training samples in feature space gives sufficient information to identify the individual samples in input space. Our analysis suggests an optimization method to reconstruct the dataset from the model parameters, and we demonstrate that this method performs well on various architectures (random features, two-layer fully-connected and deep residual networks). Our results reveal a law of data reconstruction, according to which the entire training dataset can be recovered as $p$ exceeds the threshold $dn$.
Efficient Model Editing with Task-Localized Sparse Fine-tuning
Apr 03, 2025Task arithmetic has emerged as a promising approach for editing models by representing task-specific knowledge as composable task vectors. However, existing methods rely on network linearization to derive task vectors, leading to computational bottlenecks during training and inference. Moreover, linearization alone does not ensure weight disentanglement, the key property that enables conflict-free composition of task vectors. To address this, we propose TaLoS which allows to build sparse task vectors with minimal interference without requiring explicit linearization and sharing information across tasks. We find that pre-trained models contain a subset of parameters with consistently low gradient sensitivity across tasks, and that sparsely updating only these parameters allows for promoting weight disentanglement during fine-tuning. Our experiments prove that TaLoS improves training and inference efficiency while outperforming current methods in task addition and negation. By enabling modular parameter editing, our approach fosters practical deployment of adaptable foundation models in real-world applications.
Transient Fault Tolerant Semantic Segmentation for Autonomous Driving
Aug 30, 2024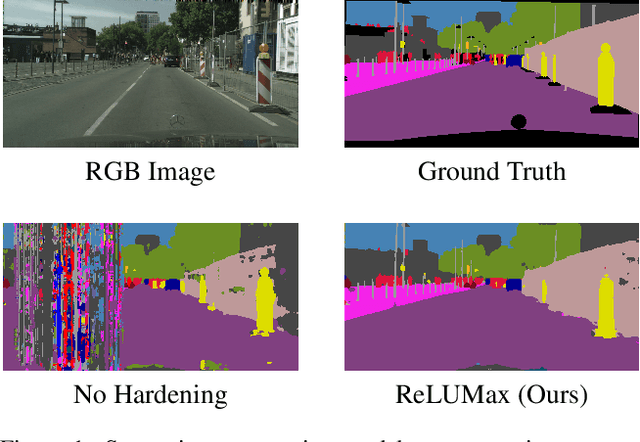
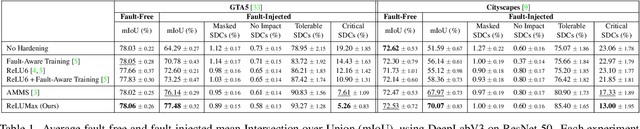
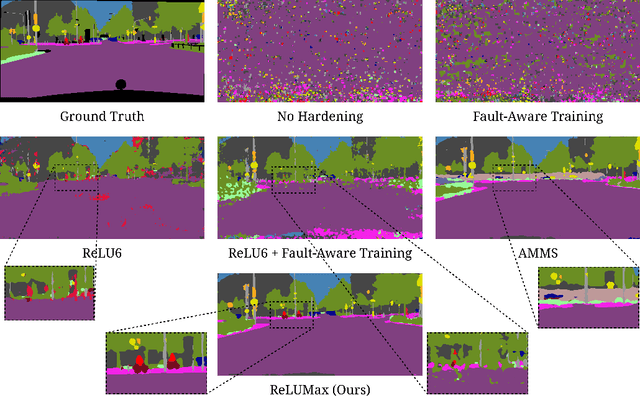

Deep learning models are crucial for autonomous vehicle perception, but their reliability is challenged by algorithmic limitations and hardware faults. We address the latter by examining fault-tolerance in semantic segmentation models. Using established hardware fault models, we evaluate existing hardening techniques both in terms of accuracy and uncertainty and introduce ReLUMax, a novel simple activation function designed to enhance resilience against transient faults. ReLUMax integrates seamlessly into existing architectures without time overhead. Our experiments demonstrate that ReLUMax effectively improves robustness, preserving performance and boosting prediction confidence, thus contributing to the development of reliable autonomous driving systems.
Finding Lottery Tickets in Vision Models via Data-driven Spectral Foresight Pruning
Jun 03, 2024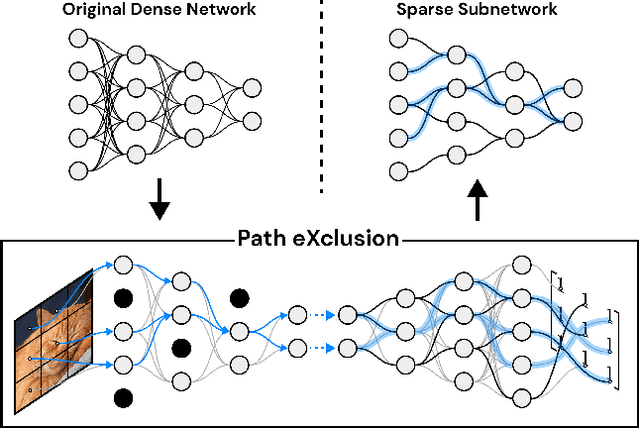
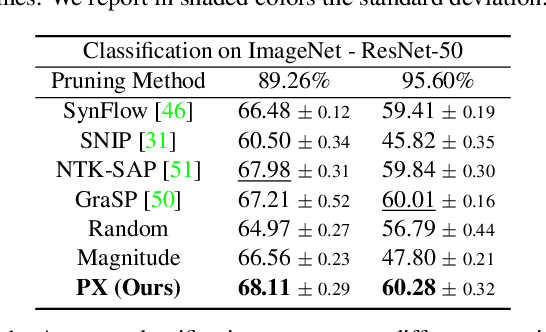
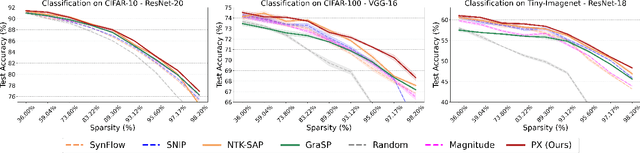
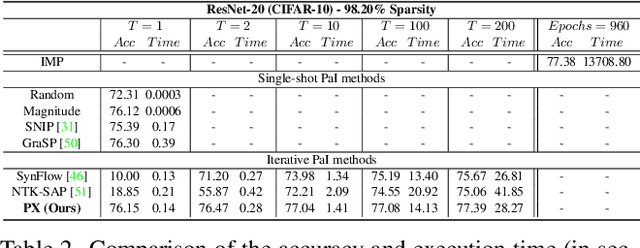
Recent advances in neural network pruning have shown how it is possible to reduce the computational costs and memory demands of deep learning models before training. We focus on this framework and propose a new pruning at initialization algorithm that leverages the Neural Tangent Kernel (NTK) theory to align the training dynamics of the sparse network with that of the dense one. Specifically, we show how the usually neglected data-dependent component in the NTK's spectrum can be taken into account by providing an analytical upper bound to the NTK's trace obtained by decomposing neural networks into individual paths. This leads to our Path eXclusion (PX), a foresight pruning method designed to preserve the parameters that mostly influence the NTK's trace. PX is able to find lottery tickets (i.e. good paths) even at high sparsity levels and largely reduces the need for additional training. When applied to pre-trained models it extracts subnetworks directly usable for several downstream tasks, resulting in performance comparable to those of the dense counterpart but with substantial cost and computational savings. Code available at: https://github.com/iurada/px-ntk-pruning
Fairness meets Cross-Domain Learning: a new perspective on Models and Metrics
Mar 25, 2023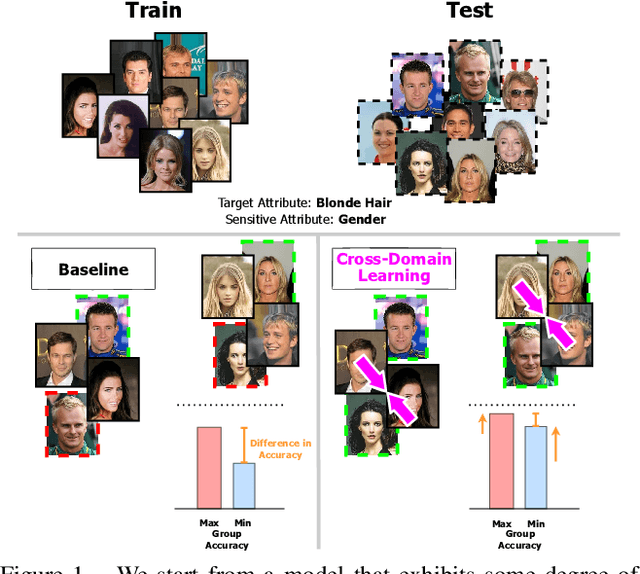
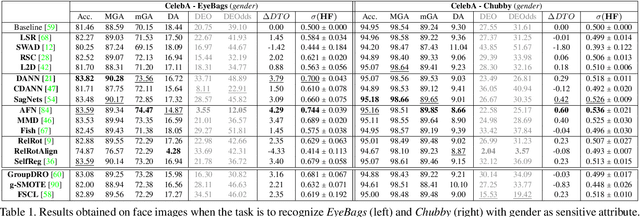
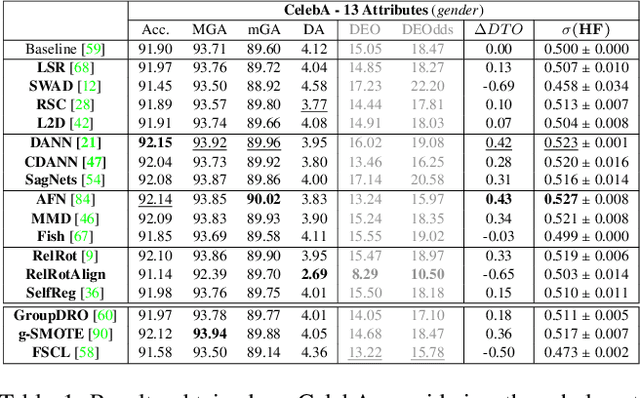
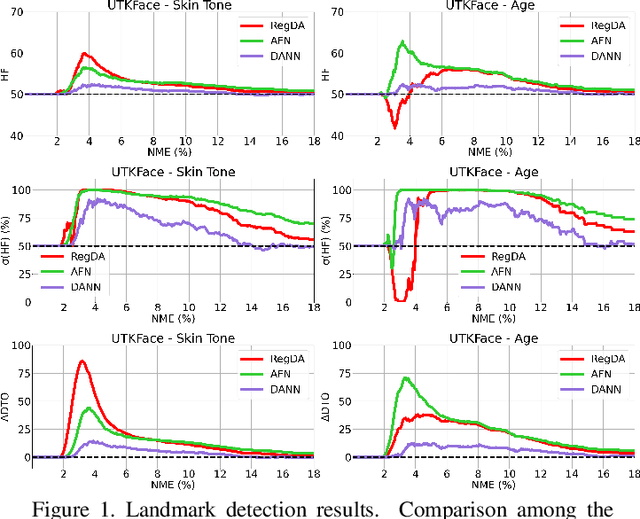
Deep learning-based recognition systems are deployed at scale for several real-world applications that inevitably involve our social life. Although being of great support when making complex decisions, they might capture spurious data correlations and leverage sensitive attributes (e.g. age, gender, ethnicity). How to factor out this information while keeping a high prediction performance is a task with still several open questions, many of which are shared with those of the domain adaptation and generalization literature which focuses on avoiding visual domain biases. In this work, we propose an in-depth study of the relationship between cross-domain learning (CD) and model fairness by introducing a benchmark on face and medical images spanning several demographic groups as well as classification and localization tasks. After having highlighted the limits of the current evaluation metrics, we introduce a new Harmonic Fairness (HF) score to assess jointly how fair and accurate every model is with respect to a reference baseline. Our study covers 14 CD approaches alongside three state-of-the-art fairness algorithms and shows how the former can outperform the latter. Overall, our work paves the way for a more systematic analysis of fairness problems in computer vision. Code available at: https://github.com/iurada/fairness_crossdomain