 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiGraspNet: A Multitask 3D Vision Model for Multi-gripper Robotic Grasping
Feb 06, 2026Vision-based models for robotic grasping automate critical, repetitive, and draining industrial tasks. Existing approaches are typically limited in two ways: they either target a single gripper and are potentially applied on costly dual-arm setups, or rely on custom hybrid grippers that require ad-hoc learning procedures with logic that cannot be transferred across tasks, restricting their general applicability. In this work, we present MultiGraspNet, a novel multitask 3D deep learning method that predicts feasible poses simultaneously for parallel and vacuum grippers within a unified framework, enabling a single robot to handle multiple end effectors. The model is trained on the richly annotated GraspNet-1Billion and SuctionNet-1Billion datasets, which have been aligned for the purpose, and generates graspability masks quantifying the suitability of each scene point for successful grasps. By sharing early-stage features while maintaining gripper-specific refiners, MultiGraspNet effectively leverages complementary information across grasping modalities, enhancing robustness and adaptability in cluttered scenes. We characterize MultiGraspNet's performance with an extensive experimental analysis, demonstrating its competitiveness with single-task models on relevant benchmarks. We run real-world experiments on a single-arm multi-gripper robotic setup showing that our approach outperforms the vacuum baseline, grasping 16% percent more seen objects and 32% more of the novel ones, while obtaining competitive results for the parallel task.
A Law of Data Reconstruction for Random Features (and Beyond)
Sep 26, 2025



Large-scale deep learning models are known to memorize parts of the training set. In machine learning theory, memorization is often framed as interpolation or label fitting, and classical results show that this can be achieved when the number of parameters $p$ in the model is larger than the number of training samples $n$. In this work, we consider memorization from the perspective of data reconstruction, demonstrating that this can be achieved when $p$ is larger than $dn$, where $d$ is the dimensionality of the data. More specifically, we show that, in the random features model, when $p \gg dn$, the subspace spanned by the training samples in feature space gives sufficient information to identify the individual samples in input space. Our analysis suggests an optimization method to reconstruct the dataset from the model parameters, and we demonstrate that this method performs well on various architectures (random features, two-layer fully-connected and deep residual networks). Our results reveal a law of data reconstruction, according to which the entire training dataset can be recovered as $p$ exceeds the threshold $dn$.
Efficient Odd-One-Out Anomaly Detection
Sep 04, 2025The recently introduced odd-one-out anomaly detection task involves identifying the odd-looking instances within a multi-object scene. This problem presents several challenges for modern deep learning models, demanding spatial reasoning across multiple views and relational reasoning to understand context and generalize across varying object categories and layouts. We argue that these challenges must be addressed with efficiency in mind. To this end, we propose a DINO-based model that reduces the number of parameters by one third and shortens training time by a factor of three compared to the current state-of-the-art, while maintaining competitive performance. Our experimental evaluation also introduces a Multimodal Large Language Model baseline, providing insights into its current limitations in structured visual reasoning tasks. The project page can be found at https://silviochito.github.io/EfficientOddOneOut/
Learning reusable concepts across different egocentric video understanding tasks
May 30, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. In this paper, we introduce Hier-EgoPack, a unified framework able to create a collection of task perspectives that can be carried across downstream tasks and used as a potential source of additional insights, as a backpack of skills that a robot can carry around and use when needed.
Efficient Model Editing with Task-Localized Sparse Fine-tuning
Apr 03, 2025Task arithmetic has emerged as a promising approach for editing models by representing task-specific knowledge as composable task vectors. However, existing methods rely on network linearization to derive task vectors, leading to computational bottlenecks during training and inference. Moreover, linearization alone does not ensure weight disentanglement, the key property that enables conflict-free composition of task vectors. To address this, we propose TaLoS which allows to build sparse task vectors with minimal interference without requiring explicit linearization and sharing information across tasks. We find that pre-trained models contain a subset of parameters with consistently low gradient sensitivity across tasks, and that sparsely updating only these parameters allows for promoting weight disentanglement during fine-tuning. Our experiments prove that TaLoS improves training and inference efficiency while outperforming current methods in task addition and negation. By enabling modular parameter editing, our approach fosters practical deployment of adaptable foundation models in real-world applications.
FORESCENE: FOREcasting human activity via latent SCENE graphs diffusion
Mar 08, 2025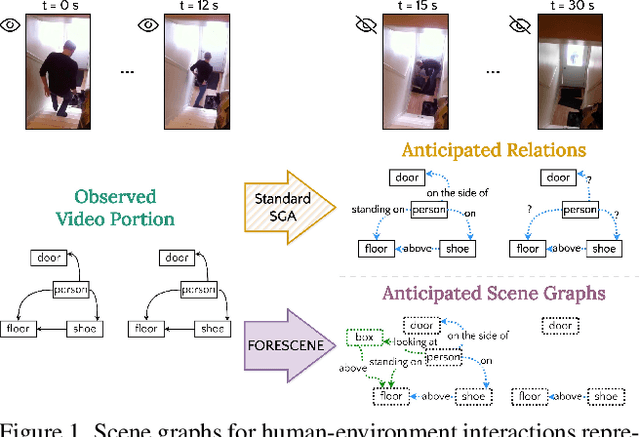
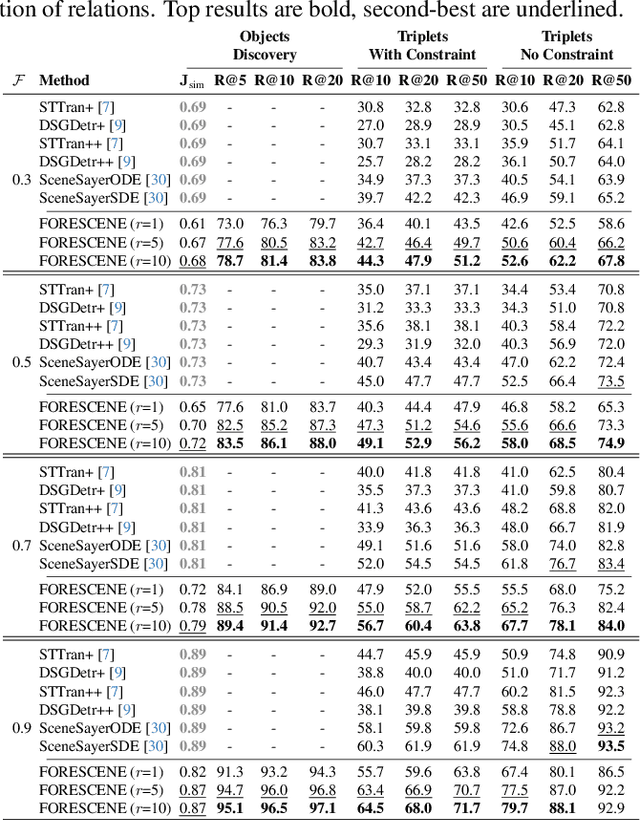
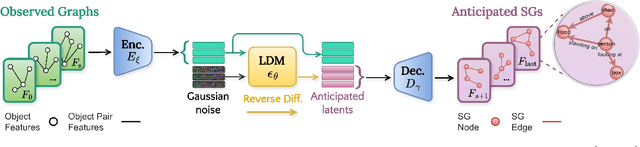
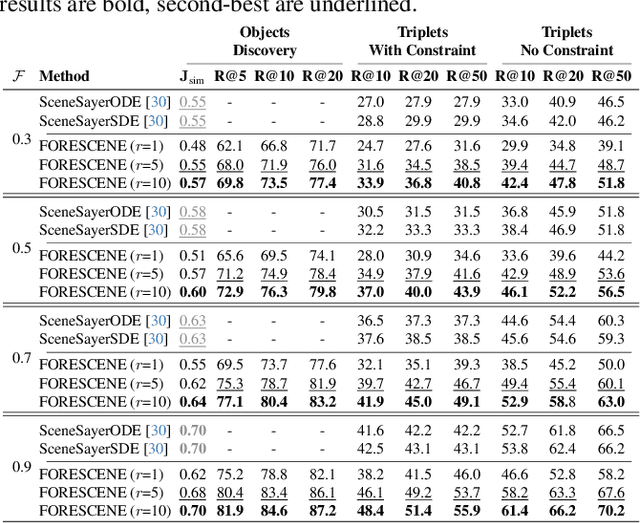
Forecasting human-environment interactions in daily activities is challenging due to the high variability of human behavior. While predicting directly from videos is possible, it is limited by confounding factors like irrelevant objects or background noise that do not contribute to the interaction. A promising alternative is using Scene Graphs (SGs) to track only the relevant elements. However, current methods for forecasting future SGs face significant challenges and often rely on unrealistic assumptions, such as fixed objects over time, limiting their applicability to long-term activities where interacted objects may appear or disappear. In this paper, we introduce FORESCENE, a novel framework for Scene Graph Anticipation (SGA) that predicts both object and relationship evolution over time. FORESCENE encodes observed video segments into a latent representation using a tailored Graph Auto-Encoder and forecasts future SGs using a Latent Diffusion Model (LDM). Our approach enables continuous prediction of interaction dynamics without making assumptions on the graph's content or structure. We evaluate FORESCENE on the Action Genome dataset, where it outperforms existing SGA methods while solving a significantly more complex task.
MaskPlanner: Learning-Based Object-Centric Motion Generation from 3D Point Clouds
Feb 26, 2025Object-Centric Motion Generation (OCMG) plays a key role in a variety of industrial applications$\unicode{x2014}$such as robotic spray painting and welding$\unicode{x2014}$requiring efficient, scalable, and generalizable algorithms to plan multiple long-horizon trajectories over free-form 3D objects. However, existing solutions rely on specialized heuristics, expensive optimization routines, or restrictive geometry assumptions that limit their adaptability to real-world scenarios. In this work, we introduce a novel, fully data-driven framework that tackles OCMG directly from 3D point clouds, learning to generalize expert path patterns across free-form surfaces. We propose MaskPlanner, a deep learning method that predicts local path segments for a given object while simultaneously inferring "path masks" to group these segments into distinct paths. This design induces the network to capture both local geometric patterns and global task requirements in a single forward pass. Extensive experimentation on a realistic robotic spray painting scenario shows that our approach attains near-complete coverage (above 99%) for unseen objects, while it remains task-agnostic and does not explicitly optimize for paint deposition. Moreover, our real-world validation on a 6-DoF specialized painting robot demonstrates that the generated trajectories are directly executable and yield expert-level painting quality. Our findings crucially highlight the potential of the proposed learning method for OCMG to reduce engineering overhead and seamlessly adapt to several industrial use cases.
Hier-EgoPack: Hierarchical Egocentric Video Understanding with Diverse Task Perspectives
Feb 04, 2025Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such a holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. A significant step in this direction is EgoPack, a unified framework for understanding human activities across diverse tasks with minimal overhead. EgoPack promotes information sharing and collaboration among downstream tasks, essential for efficiently learning new skills. In this paper, we introduce Hier-EgoPack, which advances EgoPack by enabling reasoning also across diverse temporal granularities, which expands its applicability to a broader range of downstream tasks. To achieve this, we propose a novel hierarchical architecture for temporal reasoning equipped with a GNN layer specifically designed to tackle the challenges of multi-granularity reasoning effectively. We evaluate our approach on multiple Ego4d benchmarks involving both clip-level and frame-level reasoning, demonstrating how our hierarchical unified architecture effectively solves these diverse tasks simultaneously.
A Modern Take on Visual Relationship Reasoning for Grasp Planning
Sep 03, 2024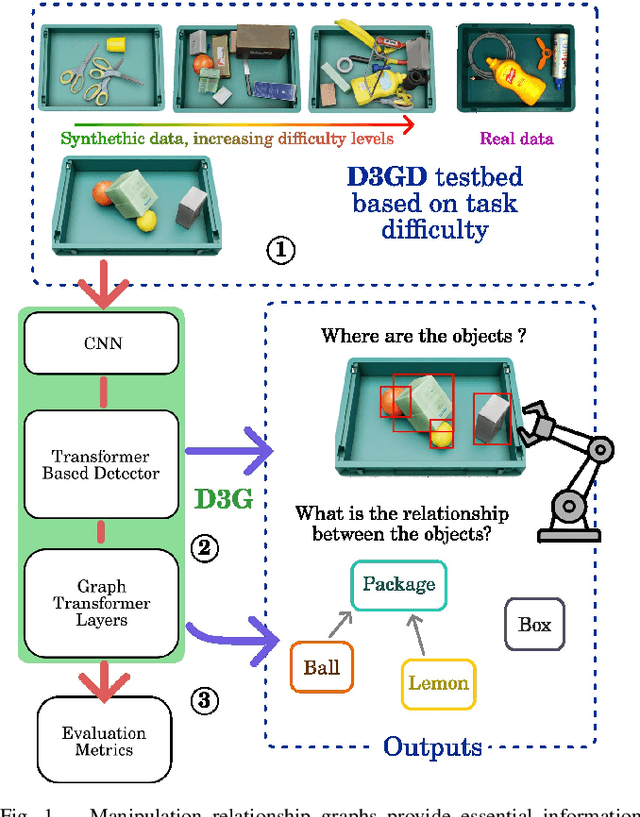
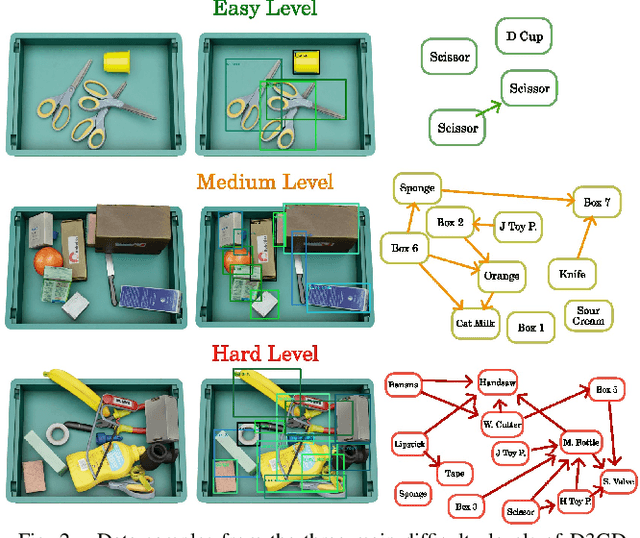
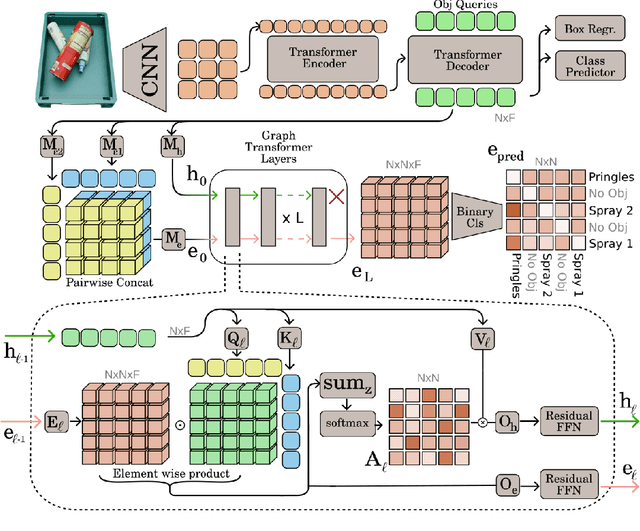
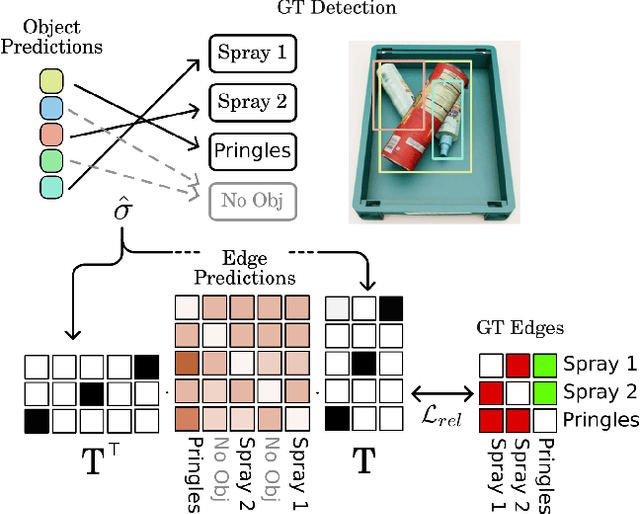
Interacting with real-world cluttered scenes pose several challenges to robotic agents that need to understand complex spatial dependencies among the observed objects to determine optimal pick sequences or efficient object retrieval strategies. Existing solutions typically manage simplified scenarios and focus on predicting pairwise object relationships following an initial object detection phase, but often overlook the global context or struggle with handling redundant and missing object relations. In this work, we present a modern take on visual relational reasoning for grasp planning. We introduce D3GD, a novel testbed that includes bin picking scenes with up to 35 objects from 97 distinct categories. Additionally, we propose D3G, a new end-to-end transformer-based dependency graph generation model that simultaneously detects objects and produces an adjacency matrix representing their spatial relationships. Recognizing the limitations of standard metrics, we employ the Average Precision of Relationships for the first time to evaluate model performance, conducting an extensive experimental benchmark. The obtained results establish our approach as the new state-of-the-art for this task, laying the foundation for future research in robotic manipulation. We publicly release the code and dataset at https://paolotron.github.io/d3g.github.io.
Transient Fault Tolerant Semantic Segmentation for Autonomous Driving
Aug 30, 2024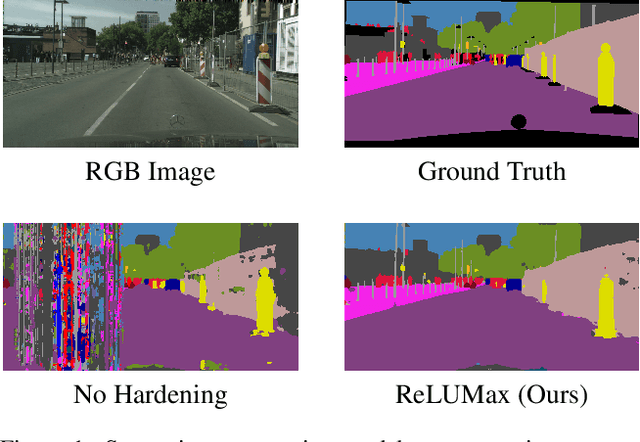
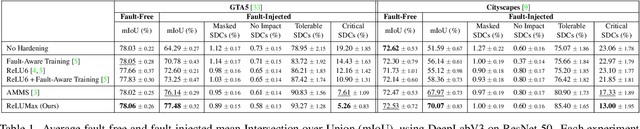
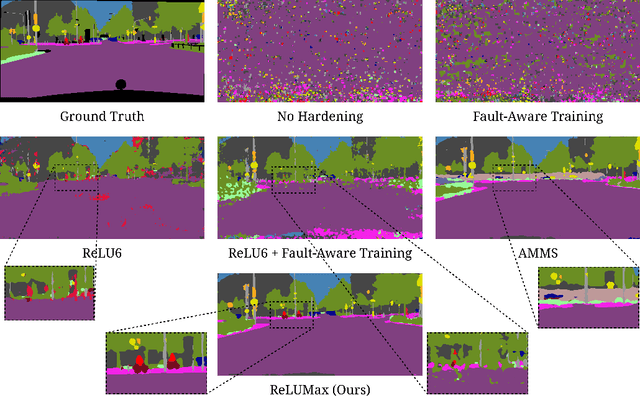

Deep learning models are crucial for autonomous vehicle perception, but their reliability is challenged by algorithmic limitations and hardware faults. We address the latter by examining fault-tolerance in semantic segmentation models. Using established hardware fault models, we evaluate existing hardening techniques both in terms of accuracy and uncertainty and introduce ReLUMax, a novel simple activation function designed to enhance resilience against transient faults. ReLUMax integrates seamlessly into existing architectures without time overhead. Our experiments demonstrate that ReLUMax effectively improves robustness, preserving performance and boosting prediction confidence, thus contributing to the development of reliable autonomous driving systems.