 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiGraspNet: A Multitask 3D Vision Model for Multi-gripper Robotic Grasping
Feb 06, 2026Vision-based models for robotic grasping automate critical, repetitive, and draining industrial tasks. Existing approaches are typically limited in two ways: they either target a single gripper and are potentially applied on costly dual-arm setups, or rely on custom hybrid grippers that require ad-hoc learning procedures with logic that cannot be transferred across tasks, restricting their general applicability. In this work, we present MultiGraspNet, a novel multitask 3D deep learning method that predicts feasible poses simultaneously for parallel and vacuum grippers within a unified framework, enabling a single robot to handle multiple end effectors. The model is trained on the richly annotated GraspNet-1Billion and SuctionNet-1Billion datasets, which have been aligned for the purpose, and generates graspability masks quantifying the suitability of each scene point for successful grasps. By sharing early-stage features while maintaining gripper-specific refiners, MultiGraspNet effectively leverages complementary information across grasping modalities, enhancing robustness and adaptability in cluttered scenes. We characterize MultiGraspNet's performance with an extensive experimental analysis, demonstrating its competitiveness with single-task models on relevant benchmarks. We run real-world experiments on a single-arm multi-gripper robotic setup showing that our approach outperforms the vacuum baseline, grasping 16% percent more seen objects and 32% more of the novel ones, while obtaining competitive results for the parallel task.
Efficient Odd-One-Out Anomaly Detection
Sep 04, 2025The recently introduced odd-one-out anomaly detection task involves identifying the odd-looking instances within a multi-object scene. This problem presents several challenges for modern deep learning models, demanding spatial reasoning across multiple views and relational reasoning to understand context and generalize across varying object categories and layouts. We argue that these challenges must be addressed with efficiency in mind. To this end, we propose a DINO-based model that reduces the number of parameters by one third and shortens training time by a factor of three compared to the current state-of-the-art, while maintaining competitive performance. Our experimental evaluation also introduces a Multimodal Large Language Model baseline, providing insights into its current limitations in structured visual reasoning tasks. The project page can be found at https://silviochito.github.io/EfficientOddOneOut/
A Modern Take on Visual Relationship Reasoning for Grasp Planning
Sep 03, 2024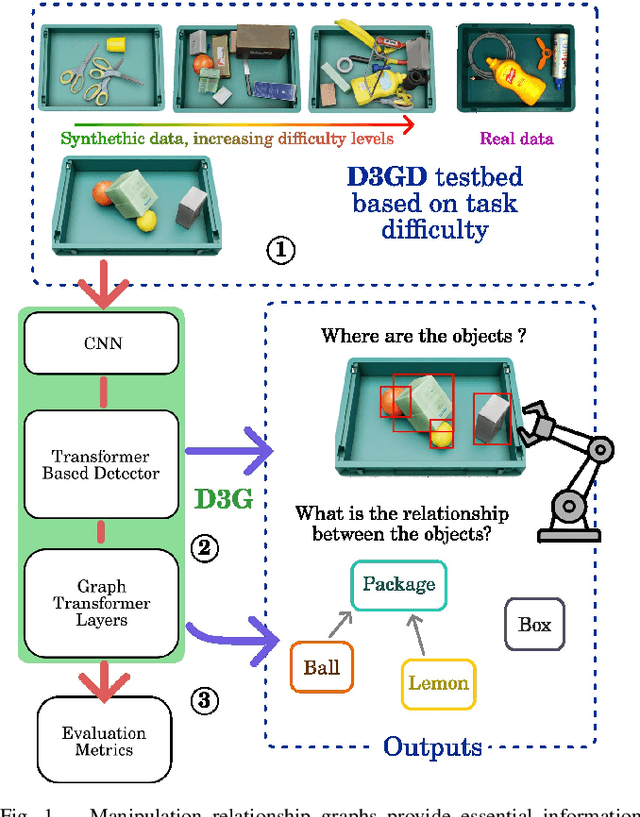
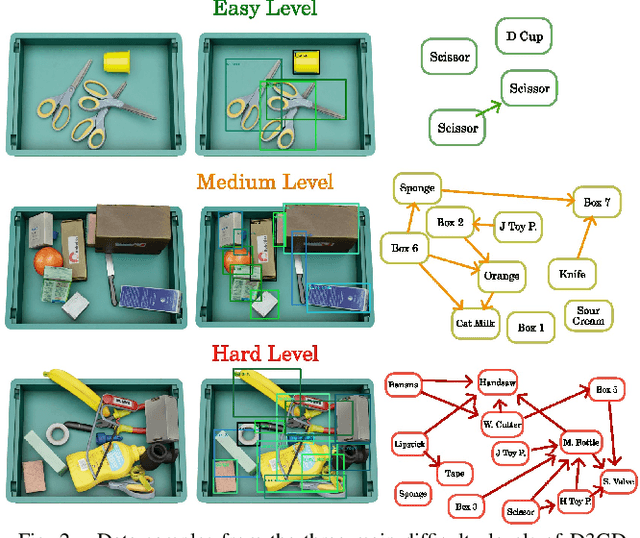
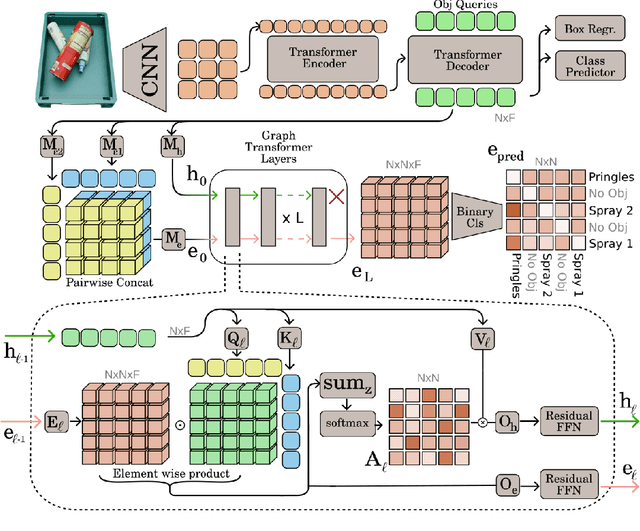
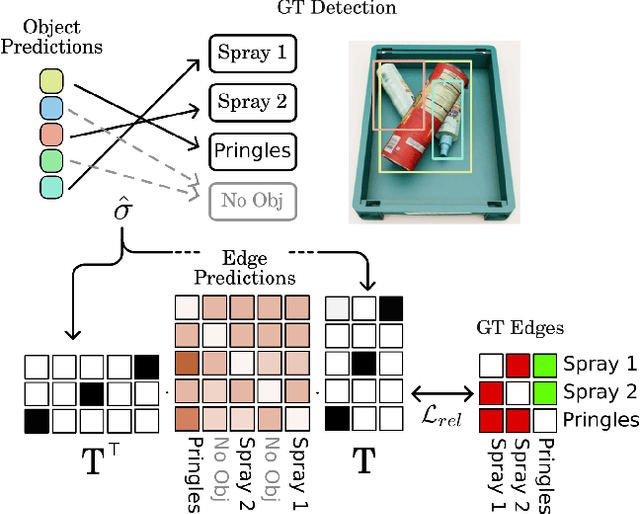
Interacting with real-world cluttered scenes pose several challenges to robotic agents that need to understand complex spatial dependencies among the observed objects to determine optimal pick sequences or efficient object retrieval strategies. Existing solutions typically manage simplified scenarios and focus on predicting pairwise object relationships following an initial object detection phase, but often overlook the global context or struggle with handling redundant and missing object relations. In this work, we present a modern take on visual relational reasoning for grasp planning. We introduce D3GD, a novel testbed that includes bin picking scenes with up to 35 objects from 97 distinct categories. Additionally, we propose D3G, a new end-to-end transformer-based dependency graph generation model that simultaneously detects objects and produces an adjacency matrix representing their spatial relationships. Recognizing the limitations of standard metrics, we employ the Average Precision of Relationships for the first time to evaluate model performance, conducting an extensive experimental benchmark. The obtained results establish our approach as the new state-of-the-art for this task, laying the foundation for future research in robotic manipulation. We publicly release the code and dataset at https://paolotron.github.io/d3g.github.io.
OpenPatch: a 3D patchwork for Out-Of-Distribution detection
Oct 06, 2023



Moving deep learning models from the laboratory setting to the open world entails preparing them to handle unforeseen conditions. In several applications the occurrence of novel classes during deployment poses a significant threat, thus it is crucial to effectively detect them. Ideally, this skill should be used when needed without requiring any further computational training effort at every new task. Out-of-distribution detection has attracted significant attention in the last years, however the majority of the studies deal with 2D images ignoring the inherent 3D nature of the real-world and often confusing between domain and semantic novelty. In this work, we focus on the latter, considering the objects geometric structure captured by 3D point clouds regardless of the specific domain. We advance the field by introducing OpenPatch that builds on a large pre-trained model and simply extracts from its intermediate features a set of patch representations that describe each known class. For any new sample, we obtain a novelty score by evaluating whether it can be recomposed mainly by patches of a single known class or rather via the contribution of multiple classes. We present an extensive experimental evaluation of our approach for the task of semantic novelty detection on real-world point cloud samples when the reference known data are synthetic. We demonstrate that OpenPatch excels in both the full and few-shot known sample scenarios, showcasing its robustness across varying pre-training objectives and network backbones. The inherent training-free nature of our method allows for its immediate application to a wide array of real-world tasks, offering a compelling advantage over approaches that need expensive retraining efforts.