 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJRM: Joint Reconstruction Model for Multiple Objects without Alignment
Mar 27, 2026Object-centric reconstruction seeks to recover the 3D structure of a scene through composition of independent objects. While this independence can simplify modeling, it discards strong signals that could improve reconstruction, notably repetition where the same object model is seen multiple times in a scene, or across scans. We propose the Joint Reconstruction Model (JRM) to leverage repetition by framing object reconstruction as one of personalized generation: multiple observations share a common subject that should be consistent for all observations, while still adhering to the specific pose and state from each. Prior methods in this direction rely on explicit matching and rigid alignment across observations, making them sensitive to errors and difficult to extend to non-rigid transformations. In contrast, JRM is a 3D flow-matching generative model that implicitly aggregates unaligned observations in its latent space, learning to produce consistent and faithful reconstructions in a data-driven manner without explicit constraints. Evaluations on synthetic and real-world data show that JRM's implicit aggregation removes the need for explicit alignment, improves robustness to incorrect associations, and naturally handles non-rigid changes such as articulation. Overall, JRM outperforms both independent and alignment-based baselines in reconstruction quality.
NymeriaPlus: Enriching Nymeria Dataset with Additional Annotations and Data
Mar 19, 2026The Nymeria Dataset, released in 2024, is a large-scale collection of in-the-wild human activities captured with multiple egocentric wearable devices that are spatially localized and temporally synchronized. It provides body-motion ground truth recorded with a motion-capture suit, device trajectories, semi-dense 3D point clouds, and in-context narrations. In this paper, we upgrade Nymeria and introduce NymeriaPlus. NymeriaPlus features: (1) improved human motion in Momentum Human Rig (MHR) and SMPL formats; (2) dense 3D and 2D bounding box annotations for indoor objects and structural elements; (3) instance-level 3D object reconstructions; and (4) additional modalities e.g., basemap recordings, audio, and wristband videos. By consolidating these complementary modalities and annotations into a single, coherent benchmark, NymeriaPlus strengthens Nymeria into a more powerful in-the-wild egocentric dataset. We expect NymeriaPlus to bridge a key gap in existing egocentric resources and to support a broader range of research, including unique explorations of multimodal learning for embodied AI.
ShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
VertexRegen: Mesh Generation with Continuous Level of Detail
Aug 12, 2025We introduce VertexRegen, a novel mesh generation framework that enables generation at a continuous level of detail. Existing autoregressive methods generate meshes in a partial-to-complete manner and thus intermediate steps of generation represent incomplete structures. VertexRegen takes inspiration from progressive meshes and reformulates the process as the reversal of edge collapse, i.e. vertex split, learned through a generative model. Experimental results demonstrate that VertexRegen produces meshes of comparable quality to state-of-the-art methods while uniquely offering anytime generation with the flexibility to halt at any step to yield valid meshes with varying levels of detail.
Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling
Mar 14, 2025We present a novel human-in-the-loop approach to estimate 3D scene layout that uses human feedback from an egocentric standpoint. We study this approach through introduction of a novel local correction task, where users identify local errors and prompt a model to automatically correct them. Building on SceneScript, a state-of-the-art framework for 3D scene layout estimation that leverages structured language, we propose a solution that structures this problem as "infilling", a task studied in natural language processing. We train a multi-task version of SceneScript that maintains performance on global predictions while significantly improving its local correction ability. We integrate this into a human-in-the-loop system, enabling a user to iteratively refine scene layout estimates via a low-friction "one-click fix'' workflow. Our system enables the final refined layout to diverge from the training distribution, allowing for more accurate modelling of complex layouts.
MeshArt: Generating Articulated Meshes with Structure-guided Transformers
Dec 16, 2024



Articulated 3D object generation is fundamental for creating realistic, functional, and interactable virtual assets which are not simply static. We introduce MeshArt, a hierarchical transformer-based approach to generate articulated 3D meshes with clean, compact geometry, reminiscent of human-crafted 3D models. We approach articulated mesh generation in a part-by-part fashion across two stages. First, we generate a high-level articulation-aware object structure; then, based on this structural information, we synthesize each part's mesh faces. Key to our approach is modeling both articulation structures and part meshes as sequences of quantized triangle embeddings, leading to a unified hierarchical framework with transformers for autoregressive generation. Object part structures are first generated as their bounding primitives and articulation modes; a second transformer, guided by these articulation structures, then generates each part's mesh triangles. To ensure coherency among generated parts, we introduce structure-guided conditioning that also incorporates local part mesh connectivity. MeshArt shows significant improvements over state of the art, with 57.1% improvement in structure coverage and a 209-point improvement in mesh generation FID.
Meta 3D AssetGen: Text-to-Mesh Generation with High-Quality Geometry, Texture, and PBR Materials
Jul 02, 2024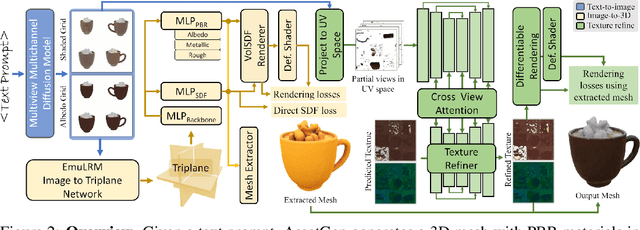
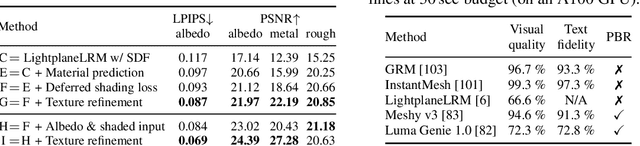
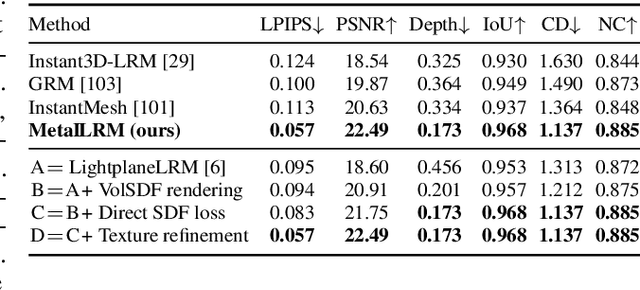

We present Meta 3D AssetGen (AssetGen), a significant advancement in text-to-3D generation which produces faithful, high-quality meshes with texture and material control. Compared to works that bake shading in the 3D object's appearance, AssetGen outputs physically-based rendering (PBR) materials, supporting realistic relighting. AssetGen generates first several views of the object with factored shaded and albedo appearance channels, and then reconstructs colours, metalness and roughness in 3D, using a deferred shading loss for efficient supervision. It also uses a sign-distance function to represent 3D shape more reliably and introduces a corresponding loss for direct shape supervision. This is implemented using fused kernels for high memory efficiency. After mesh extraction, a texture refinement transformer operating in UV space significantly improves sharpness and details. AssetGen achieves 17% improvement in Chamfer Distance and 40% in LPIPS over the best concurrent work for few-view reconstruction, and a human preference of 72% over the best industry competitors of comparable speed, including those that support PBR. Project page with generated assets: https://assetgen.github.io
Meta 3D Gen
Jul 02, 2024


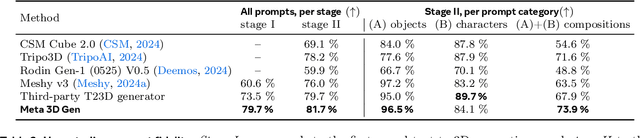
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
PolyDiff: Generating 3D Polygonal Meshes with Diffusion Models
Dec 18, 2023



We introduce PolyDiff, the first diffusion-based approach capable of directly generating realistic and diverse 3D polygonal meshes. In contrast to methods that use alternate 3D shape representations (e.g. implicit representations), our approach is a discrete denoising diffusion probabilistic model that operates natively on the polygonal mesh data structure. This enables learning of both the geometric properties of vertices and the topological characteristics of faces. Specifically, we treat meshes as quantized triangle soups, progressively corrupted with categorical noise in the forward diffusion phase. In the reverse diffusion phase, a transformer-based denoising network is trained to revert the noising process, restoring the original mesh structure. At inference, new meshes can be generated by applying this denoising network iteratively, starting with a completely noisy triangle soup. Consequently, our model is capable of producing high-quality 3D polygonal meshes, ready for integration into downstream 3D workflows. Our extensive experimental analysis shows that PolyDiff achieves a significant advantage (avg. FID and JSD improvement of 18.2 and 5.8 respectively) over current state-of-the-art methods.
MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers
Nov 27, 2023



We introduce MeshGPT, a new approach for generating triangle meshes that reflects the compactness typical of artist-created meshes, in contrast to dense triangle meshes extracted by iso-surfacing methods from neural fields. Inspired by recent advances in powerful large language models, we adopt a sequence-based approach to autoregressively generate triangle meshes as sequences of triangles. We first learn a vocabulary of latent quantized embeddings, using graph convolutions, which inform these embeddings of the local mesh geometry and topology. These embeddings are sequenced and decoded into triangles by a decoder, ensuring that they can effectively reconstruct the mesh. A transformer is then trained on this learned vocabulary to predict the index of the next embedding given previous embeddings. Once trained, our model can be autoregressively sampled to generate new triangle meshes, directly generating compact meshes with sharp edges, more closely imitating the efficient triangulation patterns of human-crafted meshes. MeshGPT demonstrates a notable improvement over state of the art mesh generation methods, with a 9% increase in shape coverage and a 30-point enhancement in FID scores across various categories.