 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic Lifting for 3D Scene Understanding with Neural Fields
Dec 19, 2022



We propose Panoptic Lifting, a novel approach for learning panoptic 3D volumetric representations from images of in-the-wild scenes. Once trained, our model can render color images together with 3D-consistent panoptic segmentation from novel viewpoints. Unlike existing approaches which use 3D input directly or indirectly, our method requires only machine-generated 2D panoptic segmentation masks inferred from a pre-trained network. Our core contribution is a panoptic lifting scheme based on a neural field representation that generates a unified and multi-view consistent, 3D panoptic representation of the scene. To account for inconsistencies of 2D instance identifiers across views, we solve a linear assignment with a cost based on the model's current predictions and the machine-generated segmentation masks, thus enabling us to lift 2D instances to 3D in a consistent way. We further propose and ablate contributions that make our method more robust to noisy, machine-generated labels, including test-time augmentations for confidence estimates, segment consistency loss, bounded segmentation fields, and gradient stopping. Experimental results validate our approach on the challenging Hypersim, Replica, and ScanNet datasets, improving by 8.4, 13.8, and 10.6% in scene-level PQ over state of the art.
Modeling the Background for Incremental and Weakly-Supervised Semantic Segmentation
Jan 31, 2022
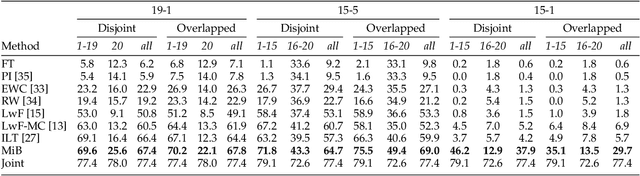
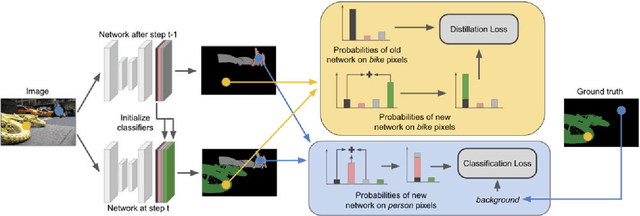
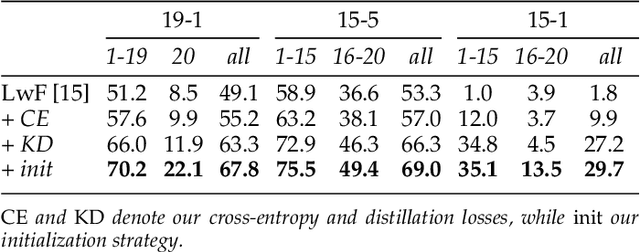
Deep neural networks have enabled major progresses in semantic segmentation. However, even the most advanced neural architectures suffer from important limitations. First, they are vulnerable to catastrophic forgetting, i.e. they perform poorly when they are required to incrementally update their model as new classes are available. Second, they rely on large amount of pixel-level annotations to produce accurate segmentation maps. To tackle these issues, we introduce a novel incremental class learning approach for semantic segmentation taking into account a peculiar aspect of this task: since each training step provides annotation only for a subset of all possible classes, pixels of the background class exhibit a semantic shift. Therefore, we revisit the traditional distillation paradigm by designing novel loss terms which explicitly account for the background shift. Additionally, we introduce a novel strategy to initialize classifier's parameters at each step in order to prevent biased predictions toward the background class. Finally, we demonstrate that our approach can be extended to point- and scribble-based weakly supervised segmentation, modeling the partial annotations to create priors for unlabeled pixels. We demonstrate the effectiveness of our approach with an extensive evaluation on the Pascal-VOC, ADE20K, and Cityscapes datasets, significantly outperforming state-of-the-art methods.
Boosting Binary Masks for Multi-Domain Learning through Affine Transformations
Mar 25, 2021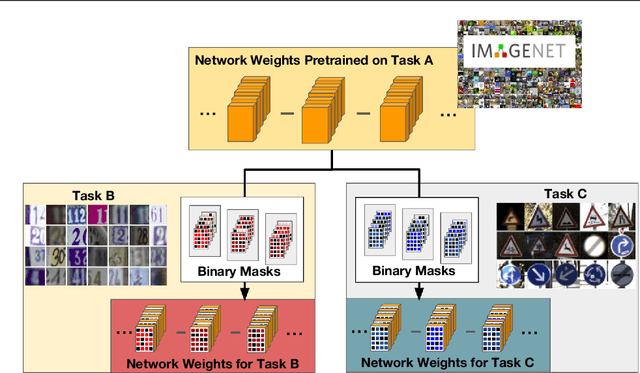
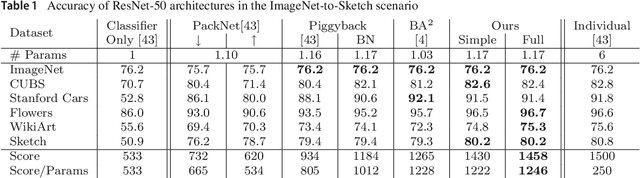
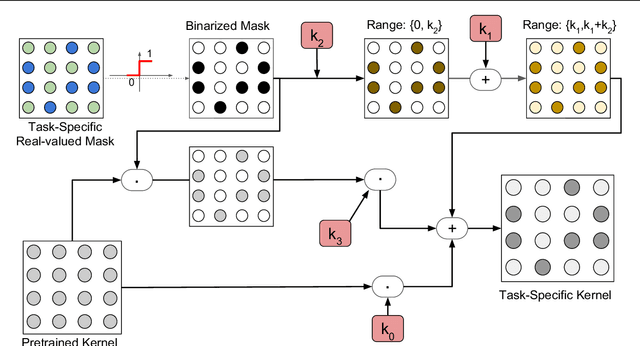
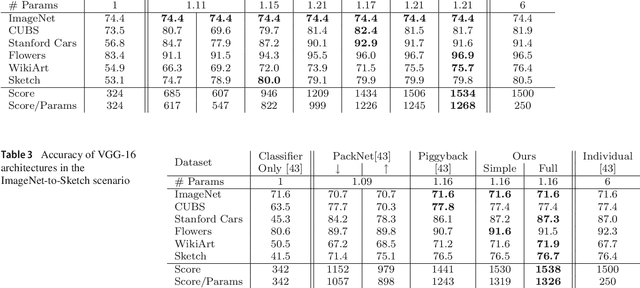
In this work, we present a new, algorithm for multi-domain learning. Given a pretrained architecture and a set of visual domains received sequentially, the goal of multi-domain learning is to produce a single model performing a task in all the domains together. Recent works showed how we can address this problem by masking the internal weights of a given original conv-net through learned binary variables. In this work, we provide a general formulation of binary mask based models for multi-domain learning by affine transformations of the original network parameters. Our formulation obtains significantly higher levels of adaptation to new domains, achieving performances comparable to domain-specific models while requiring slightly more than 1 bit per network parameter per additional domain. Experiments on two popular benchmarks showcase the power of our approach, achieving performances close to state-of-the-art methods on the Visual Decathlon Challenge.