 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Binary Masks for Multi-Domain Learning through Affine Transformations
Paper and Code
Mar 25, 2021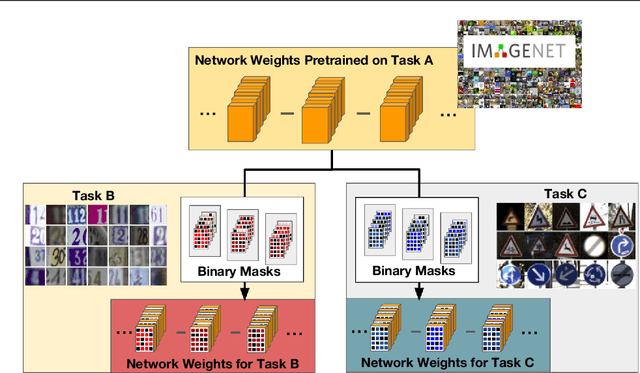
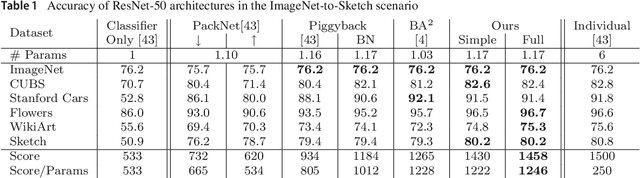
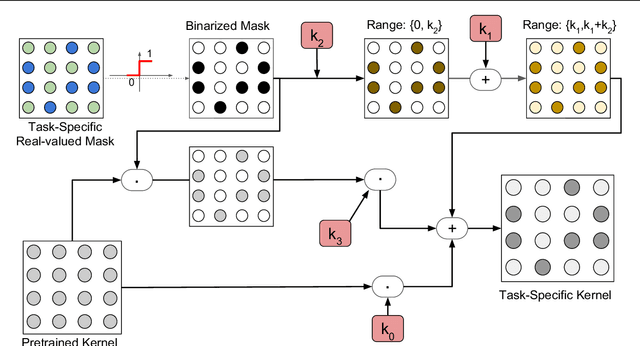
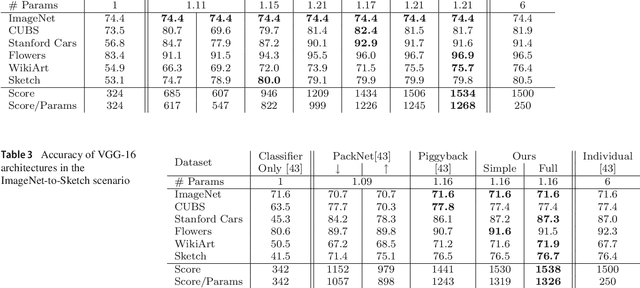
In this work, we present a new, algorithm for multi-domain learning. Given a pretrained architecture and a set of visual domains received sequentially, the goal of multi-domain learning is to produce a single model performing a task in all the domains together. Recent works showed how we can address this problem by masking the internal weights of a given original conv-net through learned binary variables. In this work, we provide a general formulation of binary mask based models for multi-domain learning by affine transformations of the original network parameters. Our formulation obtains significantly higher levels of adaptation to new domains, achieving performances comparable to domain-specific models while requiring slightly more than 1 bit per network parameter per additional domain. Experiments on two popular benchmarks showcase the power of our approach, achieving performances close to state-of-the-art methods on the Visual Decathlon Challenge.