 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcGen3D: Learning Neural Procedural Graph Representations for Image-to-3D Reconstruction
Nov 10, 2025We introduce ProcGen3D, a new approach for 3D content creation by generating procedural graph abstractions of 3D objects, which can then be decoded into rich, complex 3D assets. Inspired by the prevalent use of procedural generators in production 3D applications, we propose a sequentialized, graph-based procedural graph representation for 3D assets. We use this to learn to approximate the landscape of a procedural generator for image-based 3D reconstruction. We employ edge-based tokenization to encode the procedural graphs, and train a transformer prior to predict the next token conditioned on an input RGB image. Crucially, to enable better alignment of our generated outputs to an input image, we incorporate Monte Carlo Tree Search (MCTS) guided sampling into our generation process, steering output procedural graphs towards more image-faithful reconstructions. Our approach is applicable across a variety of objects that can be synthesized with procedural generators. Extensive experiments on cacti, trees, and bridges show that our neural procedural graph generation outperforms both state-of-the-art generative 3D methods and domain-specific modeling techniques. Furthermore, this enables improved generalization on real-world input images, despite training only on synthetic data.
MeshArt: Generating Articulated Meshes with Structure-guided Transformers
Dec 16, 2024



Articulated 3D object generation is fundamental for creating realistic, functional, and interactable virtual assets which are not simply static. We introduce MeshArt, a hierarchical transformer-based approach to generate articulated 3D meshes with clean, compact geometry, reminiscent of human-crafted 3D models. We approach articulated mesh generation in a part-by-part fashion across two stages. First, we generate a high-level articulation-aware object structure; then, based on this structural information, we synthesize each part's mesh faces. Key to our approach is modeling both articulation structures and part meshes as sequences of quantized triangle embeddings, leading to a unified hierarchical framework with transformers for autoregressive generation. Object part structures are first generated as their bounding primitives and articulation modes; a second transformer, guided by these articulation structures, then generates each part's mesh triangles. To ensure coherency among generated parts, we introduce structure-guided conditioning that also incorporates local part mesh connectivity. MeshArt shows significant improvements over state of the art, with 57.1% improvement in structure coverage and a 209-point improvement in mesh generation FID.
S2P3: Self-Supervised Polarimetric Pose Prediction
Dec 02, 2023



This paper proposes the first self-supervised 6D object pose prediction from multimodal RGB+polarimetric images. The novel training paradigm comprises 1) a physical model to extract geometric information of polarized light, 2) a teacher-student knowledge distillation scheme and 3) a self-supervised loss formulation through differentiable rendering and an invertible physical constraint. Both networks leverage the physical properties of polarized light to learn robust geometric representations by encoding shape priors and polarization characteristics derived from our physical model. Geometric pseudo-labels from the teacher support the student network without the need for annotated real data. Dense appearance and geometric information of objects are obtained through a differentiable renderer with the predicted pose for self-supervised direct coupling. The student network additionally features our proposed invertible formulation of the physical shape priors that enables end-to-end self-supervised training through physical constraints of derived polarization characteristics compared against polarimetric input images. We specifically focus on photometrically challenging objects with texture-less or reflective surfaces and transparent materials for which the most prominent performance gain is reported.
DiffCAD: Weakly-Supervised Probabilistic CAD Model Retrieval and Alignment from an RGB Image
Nov 30, 2023Perceiving 3D structures from RGB images based on CAD model primitives can enable an effective, efficient 3D object-based representation of scenes. However, current approaches rely on supervision from expensive annotations of CAD models associated with real images, and encounter challenges due to the inherent ambiguities in the task -- both in depth-scale ambiguity in monocular perception, as well as inexact matches of CAD database models to real observations. We thus propose DiffCAD, the first weakly-supervised probabilistic approach to CAD retrieval and alignment from an RGB image. We formulate this as a conditional generative task, leveraging diffusion to learn implicit probabilistic models capturing the shape, pose, and scale of CAD objects in an image. This enables multi-hypothesis generation of different plausible CAD reconstructions, requiring only a few hypotheses to characterize ambiguities in depth/scale and inexact shape matches. Our approach is trained only on synthetic data, leveraging monocular depth and mask estimates to enable robust zero-shot adaptation to various real target domains. Despite being trained solely on synthetic data, our multi-hypothesis approach can even surpass the supervised state-of-the-art on the Scan2CAD dataset by 5.9% with 8 hypotheses.
Polarimetric Information for Multi-Modal 6D Pose Estimation of Photometrically Challenging Objects with Limited Data
Aug 21, 2023



6D pose estimation pipelines that rely on RGB-only or RGB-D data show limitations for photometrically challenging objects with e.g. textureless surfaces, reflections or transparency. A supervised learning-based method utilising complementary polarisation information as input modality is proposed to overcome such limitations. This supervised approach is then extended to a self-supervised paradigm by leveraging physical characteristics of polarised light, thus eliminating the need for annotated real data. The methods achieve significant advancements in pose estimation by leveraging geometric information from polarised light and incorporating shape priors and invertible physical constraints.
Polarimetric Pose Prediction
Dec 07, 2021
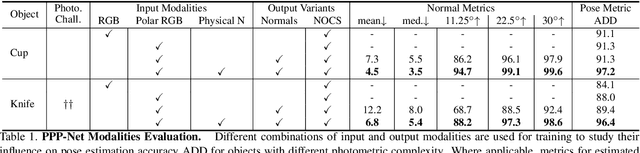
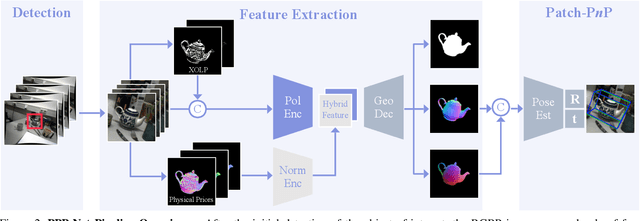
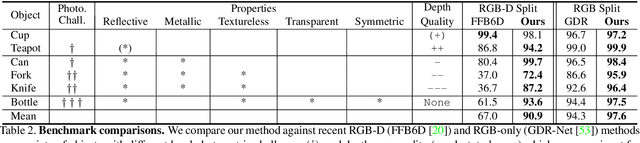
Light has many properties that can be passively measured by vision sensors. Colour-band separated wavelength and intensity are arguably the most commonly used ones for monocular 6D object pose estimation. This paper explores how complementary polarisation information, i.e. the orientation of light wave oscillations, can influence the accuracy of pose predictions. A hybrid model that leverages physical priors jointly with a data-driven learning strategy is designed and carefully tested on objects with different amount of photometric complexity. Our design not only significantly improves the pose accuracy in relation to photometric state-of-the-art approaches, but also enables object pose estimation for highly reflective and transparent objects.
Attention meets Geometry: Geometry Guided Spatial-Temporal Attention for Consistent Self-Supervised Monocular Depth Estimation
Oct 15, 2021
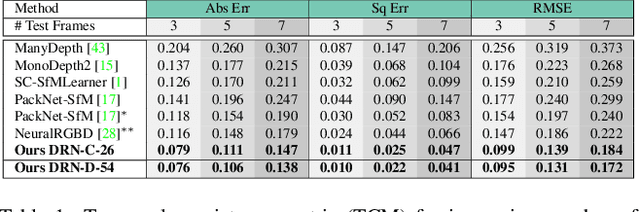

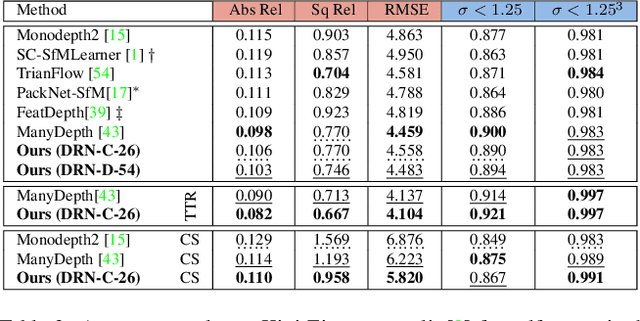
Inferring geometrically consistent dense 3D scenes across a tuple of temporally consecutive images remains challenging for self-supervised monocular depth prediction pipelines. This paper explores how the increasingly popular transformer architecture, together with novel regularized loss formulations, can improve depth consistency while preserving accuracy. We propose a spatial attention module that correlates coarse depth predictions to aggregate local geometric information. A novel temporal attention mechanism further processes the local geometric information in a global context across consecutive images. Additionally, we introduce geometric constraints between frames regularized by photometric cycle consistency. By combining our proposed regularization and the novel spatial-temporal-attention module we fully leverage both the geometric and appearance-based consistency across monocular frames. This yields geometrically meaningful attention and improves temporal depth stability and accuracy compared to previous methods.