 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention meets Geometry: Geometry Guided Spatial-Temporal Attention for Consistent Self-Supervised Monocular Depth Estimation
Paper and Code

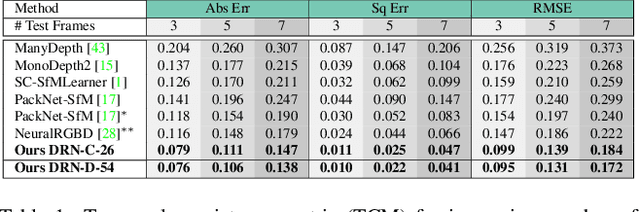

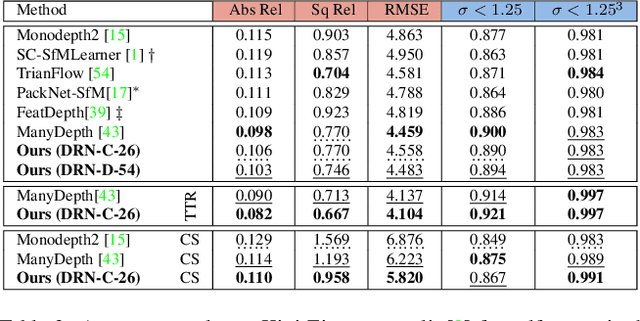
Inferring geometrically consistent dense 3D scenes across a tuple of temporally consecutive images remains challenging for self-supervised monocular depth prediction pipelines. This paper explores how the increasingly popular transformer architecture, together with novel regularized loss formulations, can improve depth consistency while preserving accuracy. We propose a spatial attention module that correlates coarse depth predictions to aggregate local geometric information. A novel temporal attention mechanism further processes the local geometric information in a global context across consecutive images. Additionally, we introduce geometric constraints between frames regularized by photometric cycle consistency. By combining our proposed regularization and the novel spatial-temporal-attention module we fully leverage both the geometric and appearance-based consistency across monocular frames. This yields geometrically meaningful attention and improves temporal depth stability and accuracy compared to previous methods.