 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCortex-Grounded Diffusion Models for Brain Image Generation
Jan 27, 2026Synthetic neuroimaging data can mitigate critical limitations of real-world datasets, including the scarcity of rare phenotypes, domain shifts across scanners, and insufficient longitudinal coverage. However, existing generative models largely rely on weak conditioning signals, such as labels or text, which lack anatomical grounding and often produce biologically implausible outputs. To this end, we introduce Cor2Vox, a cortex-grounded generative framework for brain magnetic resonance image (MRI) synthesis that ties image generation to continuous structural priors of the cerebral cortex. It leverages high-resolution cortical surfaces to guide a 3D shape-to-image Brownian bridge diffusion process, enabling topologically faithful synthesis and precise control over underlying anatomies. To support the generation of new, realistic brain shapes, we developed a large-scale statistical shape model of cortical morphology derived from over 33,000 UK Biobank scans. We validated the fidelity of Cor2Vox based on traditional image quality metrics, advanced cortical surface reconstruction, and whole-brain segmentation quality, outperforming many baseline methods. Across three applications, namely (i) anatomically consistent synthesis, (ii) simulation of progressive gray matter atrophy, and (iii) harmonization of in-house frontotemporal dementia scans with public datasets, Cor2Vox preserved fine-grained cortical morphology at the sub-voxel level, exhibiting remarkable robustness to variations in cortical geometry and disease phenotype without retraining.
TreeAdv: Tree-Structured Advantage Redistribution for Group-Based RL
Jan 07, 2026Reinforcement learning with group-based objectives, such as Group Relative Policy Optimization (GRPO), is a common framework for aligning large language models on complex reasoning tasks. However, standard GRPO treats each rollout trajectory as an independent flat sequence and assigns a single sequence-level advantage to all tokens, which leads to sample inefficiency and a length bias toward verbose, redundant chains of thought without improving logical depth. We introduce TreeAdv (Tree-Structured Advantage Redistribution for Group-Based RL), which makes the tree structure of group rollouts explicit for both exploration and advantage assignment. Specifically, TreeAdv builds a group of trees (a forest) based on an entropy-driven sampling method where each tree branches at high-uncertainty decisions while sharing low-uncertainty tokens across rollouts. Then, TreeAdv aggregates token-level advantages for internal tree segments by redistributing the advantages of complete rollouts (all leaf nodes), and TreeAdv can easily apply to group-based objectives such as GRPO or GSPO. Across 10 math reasoning benchmarks, TreeAdv consistently outperforms GRPO and GSPO, while using substantially fewer generated tokens under identical supervision, data, and decoding budgets.
Real Garment Benchmark (RGBench): A Comprehensive Benchmark for Robotic Garment Manipulation featuring a High-Fidelity Scalable Simulator
Nov 12, 2025While there has been significant progress to use simulated data to learn robotic manipulation of rigid objects, applying its success to deformable objects has been hindered by the lack of both deformable object models and realistic non-rigid body simulators. In this paper, we present Real Garment Benchmark (RGBench), a comprehensive benchmark for robotic manipulation of garments. It features a diverse set of over 6000 garment mesh models, a new high-performance simulator, and a comprehensive protocol to evaluate garment simulation quality with carefully measured real garment dynamics. Our experiments demonstrate that our simulator outperforms currently available cloth simulators by a large margin, reducing simulation error by 20% while maintaining a speed of 3 times faster. We will publicly release RGBench to accelerate future research in robotic garment manipulation. Website: https://rgbench.github.io/
HardcoreLogic: Challenging Large Reasoning Models with Long-tail Logic Puzzle Games
Oct 14, 2025Large Reasoning Models (LRMs) have demonstrated impressive performance on complex tasks, including logical puzzle games that require deriving solutions satisfying all constraints. However, whether they can flexibly apply appropriate rules to varying conditions, particularly when faced with non-canonical game variants, remains an open question. Existing corpora focus on popular puzzles like 9x9 Sudoku, risking overfitting to canonical formats and memorization of solution patterns, which can mask deficiencies in understanding novel rules or adapting strategies to new variants. To address this, we introduce HardcoreLogic, a challenging benchmark of over 5,000 puzzles across 10 games, designed to test the robustness of LRMs on the "long-tail" of logical games. HardcoreLogic systematically transforms canonical puzzles through three dimensions: Increased Complexity (IC), Uncommon Elements (UE), and Unsolvable Puzzles (UP), reducing reliance on shortcut memorization. Evaluations on a diverse set of LRMs reveal significant performance drops, even for models achieving top scores on existing benchmarks, indicating heavy reliance on memorized stereotypes. While increased complexity is the dominant source of difficulty, models also struggle with subtle rule variations that do not necessarily increase puzzle difficulty. Our systematic error analysis on solvable and unsolvable puzzles further highlights gaps in genuine reasoning. Overall, HardcoreLogic exposes the limitations of current LRMs and establishes a benchmark for advancing high-level logical reasoning.
Vision-Language-Vision Auto-Encoder: Scalable Knowledge Distillation from Diffusion Models
Jul 09, 2025Building state-of-the-art Vision-Language Models (VLMs) with strong captioning capabilities typically necessitates training on billions of high-quality image-text pairs, requiring millions of GPU hours. This paper introduces the Vision-Language-Vision (VLV) auto-encoder framework, which strategically leverages key pretrained components: a vision encoder, the decoder of a Text-to-Image (T2I) diffusion model, and subsequently, a Large Language Model (LLM). Specifically, we establish an information bottleneck by regularizing the language representation space, achieved through freezing the pretrained T2I diffusion decoder. Our VLV pipeline effectively distills knowledge from the text-conditioned diffusion model using continuous embeddings, demonstrating comprehensive semantic understanding via high-quality reconstructions. Furthermore, by fine-tuning a pretrained LLM to decode the intermediate language representations into detailed descriptions, we construct a state-of-the-art (SoTA) captioner comparable to leading models like GPT-4o and Gemini 2.0 Flash. Our method demonstrates exceptional cost-efficiency and significantly reduces data requirements; by primarily utilizing single-modal images for training and maximizing the utility of existing pretrained models (image encoder, T2I diffusion model, and LLM), it circumvents the need for massive paired image-text datasets, keeping the total training expenditure under $1,000 USD.
MedBridge: Bridging Foundation Vision-Language Models to Medical Image Diagnosis
May 27, 2025Recent vision-language foundation models deliver state-of-the-art results on natural image classification but falter on medical images due to pronounced domain shifts. At the same time, training a medical foundation model requires substantial resources, including extensive annotated data and high computational capacity. To bridge this gap with minimal overhead, we introduce MedBridge, a lightweight multimodal adaptation framework that re-purposes pretrained VLMs for accurate medical image diagnosis. MedBridge comprises three key components. First, a Focal Sampling module that extracts high-resolution local regions to capture subtle pathological features and compensate for the limited input resolution of general-purpose VLMs. Second, a Query Encoder (QEncoder) injects a small set of learnable queries that attend to the frozen feature maps of VLM, aligning them with medical semantics without retraining the entire backbone. Third, a Mixture of Experts mechanism, driven by learnable queries, harnesses the complementary strength of diverse VLMs to maximize diagnostic performance. We evaluate MedBridge on five medical imaging benchmarks across three key adaptation tasks, demonstrating its superior performance in both cross-domain and in-domain adaptation settings, even under varying levels of training data availability. Notably, MedBridge achieved over 6-15% improvement in AUC compared to state-of-the-art VLM adaptation methods in multi-label thoracic disease diagnosis, underscoring its effectiveness in leveraging foundation models for accurate and data-efficient medical diagnosis. Our code is available at https://github.com/ai-med/MedBridge.
AmorLIP: Efficient Language-Image Pretraining via Amortization
May 25, 2025



Contrastive Language-Image Pretraining (CLIP) has demonstrated strong zero-shot performance across diverse downstream text-image tasks. Existing CLIP methods typically optimize a contrastive objective using negative samples drawn from each minibatch. To achieve robust representation learning, these methods require extremely large batch sizes and escalate computational demands to hundreds or even thousands of GPUs. Prior approaches to mitigate this issue often compromise downstream performance, prolong training duration, or face scalability challenges with very large datasets. To overcome these limitations, we propose AmorLIP, an efficient CLIP pretraining framework that amortizes expensive computations involved in contrastive learning through lightweight neural networks, which substantially improves training efficiency and performance. Leveraging insights from a spectral factorization of energy-based models, we introduce novel amortization objectives along with practical techniques to improve training stability. Extensive experiments across 38 downstream tasks demonstrate the superior zero-shot classification and retrieval capabilities of AmorLIP, consistently outperforming standard CLIP baselines with substantial relative improvements of up to 12.24%.
Not All Models Suit Expert Offloading: On Local Routing Consistency of Mixture-of-Expert Models
May 21, 2025Mixture-of-Experts (MoE) enables efficient scaling of large language models (LLMs) with sparsely activated experts during inference. To effectively deploy large MoE models on memory-constrained devices, many systems introduce *expert offloading* that caches a subset of experts in fast memory, leaving others on slow memory to run on CPU or load on demand. While some research has exploited the locality of expert activations, where consecutive tokens activate similar experts, the degree of this **local routing consistency** varies across models and remains understudied. In this paper, we propose two metrics to measure local routing consistency of MoE models: (1) **Segment Routing Best Performance (SRP)**, which evaluates how well a fixed group of experts can cover the needs of a segment of tokens, and (2) **Segment Cache Best Hit Rate (SCH)**, which measures the optimal segment-level cache hit rate under a given cache size limit. We analyzed 20 MoE LLMs with diverse sizes and architectures and found that models that apply MoE on every layer and do not use shared experts exhibit the highest local routing consistency. We further showed that domain-specialized experts contribute more to routing consistency than vocabulary-specialized ones, and that most models can balance between cache effectiveness and efficiency with cache sizes approximately 2x the active experts. These findings pave the way for memory-efficient MoE design and deployment without compromising inference speed. We publish the code for replicating experiments at https://github.com/ljcleo/moe-lrc .
Process Reward Modeling with Entropy-Driven Uncertainty
Mar 28, 2025



This paper presents the Entropy-Driven Unified Process Reward Model (EDU-PRM), a novel framework that approximates state-of-the-art performance in process supervision while drastically reducing training costs. EDU-PRM introduces an entropy-guided dynamic step partitioning mechanism, using logit distribution entropy to pinpoint high-uncertainty regions during token generation dynamically. This self-assessment capability enables precise step-level feedback without manual fine-grained annotation, addressing a critical challenge in process supervision. Experiments on the Qwen2.5-72B model with only 7,500 EDU-PRM-generated training queries demonstrate accuracy closely approximating the full Qwen2.5-72B-PRM (71.1% vs. 71.6%), achieving a 98% reduction in query cost compared to prior methods. This work establishes EDU-PRM as an efficient approach for scalable process reward model training.
Mixture of Lookup Experts
Mar 20, 2025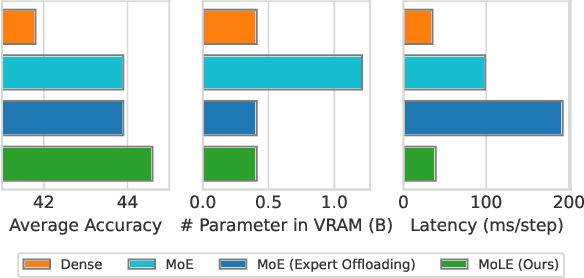

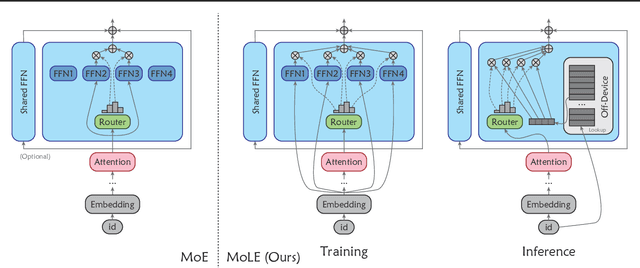
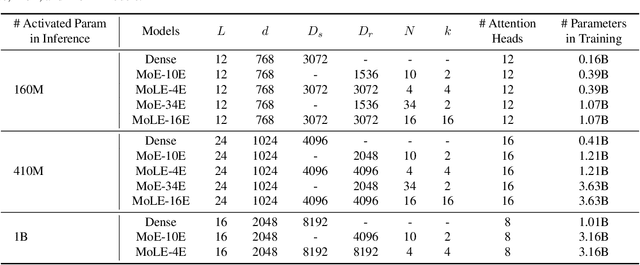
Mixture-of-Experts (MoE) activates only a subset of experts during inference, allowing the model to maintain low inference FLOPs and latency even as the parameter count scales up. However, since MoE dynamically selects the experts, all the experts need to be loaded into VRAM. Their large parameter size still limits deployment, and offloading, which load experts into VRAM only when needed, significantly increase inference latency. To address this, we propose Mixture of Lookup Experts (MoLE), a new MoE architecture that is efficient in both communication and VRAM usage. In MoLE, the experts are Feed-Forward Networks (FFNs) during training, taking the output of the embedding layer as input. Before inference, these experts can be re-parameterized as lookup tables (LUTs) that retrieves expert outputs based on input ids, and offloaded to storage devices. Therefore, we do not need to perform expert computations during inference. Instead, we directly retrieve the expert's computation results based on input ids and load them into VRAM, and thus the resulting communication overhead is negligible. Experiments show that, with the same FLOPs and VRAM usage, MoLE achieves inference speeds comparable to dense models and significantly faster than MoE with experts offloading, while maintaining performance on par with MoE.