 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardcoreLogic: Challenging Large Reasoning Models with Long-tail Logic Puzzle Games
Oct 14, 2025Large Reasoning Models (LRMs) have demonstrated impressive performance on complex tasks, including logical puzzle games that require deriving solutions satisfying all constraints. However, whether they can flexibly apply appropriate rules to varying conditions, particularly when faced with non-canonical game variants, remains an open question. Existing corpora focus on popular puzzles like 9x9 Sudoku, risking overfitting to canonical formats and memorization of solution patterns, which can mask deficiencies in understanding novel rules or adapting strategies to new variants. To address this, we introduce HardcoreLogic, a challenging benchmark of over 5,000 puzzles across 10 games, designed to test the robustness of LRMs on the "long-tail" of logical games. HardcoreLogic systematically transforms canonical puzzles through three dimensions: Increased Complexity (IC), Uncommon Elements (UE), and Unsolvable Puzzles (UP), reducing reliance on shortcut memorization. Evaluations on a diverse set of LRMs reveal significant performance drops, even for models achieving top scores on existing benchmarks, indicating heavy reliance on memorized stereotypes. While increased complexity is the dominant source of difficulty, models also struggle with subtle rule variations that do not necessarily increase puzzle difficulty. Our systematic error analysis on solvable and unsolvable puzzles further highlights gaps in genuine reasoning. Overall, HardcoreLogic exposes the limitations of current LRMs and establishes a benchmark for advancing high-level logical reasoning.
Not All Models Suit Expert Offloading: On Local Routing Consistency of Mixture-of-Expert Models
May 21, 2025Mixture-of-Experts (MoE) enables efficient scaling of large language models (LLMs) with sparsely activated experts during inference. To effectively deploy large MoE models on memory-constrained devices, many systems introduce *expert offloading* that caches a subset of experts in fast memory, leaving others on slow memory to run on CPU or load on demand. While some research has exploited the locality of expert activations, where consecutive tokens activate similar experts, the degree of this **local routing consistency** varies across models and remains understudied. In this paper, we propose two metrics to measure local routing consistency of MoE models: (1) **Segment Routing Best Performance (SRP)**, which evaluates how well a fixed group of experts can cover the needs of a segment of tokens, and (2) **Segment Cache Best Hit Rate (SCH)**, which measures the optimal segment-level cache hit rate under a given cache size limit. We analyzed 20 MoE LLMs with diverse sizes and architectures and found that models that apply MoE on every layer and do not use shared experts exhibit the highest local routing consistency. We further showed that domain-specialized experts contribute more to routing consistency than vocabulary-specialized ones, and that most models can balance between cache effectiveness and efficiency with cache sizes approximately 2x the active experts. These findings pave the way for memory-efficient MoE design and deployment without compromising inference speed. We publish the code for replicating experiments at https://github.com/ljcleo/moe-lrc .
From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents
Dec 04, 2024



Traditional sociological research often relies on human participation, which, though effective, is expensive, challenging to scale, and with ethical concerns. Recent advancements in large language models (LLMs) highlight their potential to simulate human behavior, enabling the replication of individual responses and facilitating studies on many interdisciplinary studies. In this paper, we conduct a comprehensive survey of this field, illustrating the recent progress in simulation driven by LLM-empowered agents. We categorize the simulations into three types: (1) Individual Simulation, which mimics specific individuals or demographic groups; (2) Scenario Simulation, where multiple agents collaborate to achieve goals within specific contexts; and (3) Society Simulation, which models interactions within agent societies to reflect the complexity and variety of real-world dynamics. These simulations follow a progression, ranging from detailed individual modeling to large-scale societal phenomena. We provide a detailed discussion of each simulation type, including the architecture or key components of the simulation, the classification of objectives or scenarios and the evaluation method. Afterward, we summarize commonly used datasets and benchmarks. Finally, we discuss the trends across these three types of simulation. A repository for the related sources is at {\url{https://github.com/FudanDISC/SocialAgent}}.
AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios
Oct 25, 2024



Large language models (LLMs) are increasingly leveraged to empower autonomous agents to simulate human beings in various fields of behavioral research. However, evaluating their capacity to navigate complex social interactions remains a challenge. Previous studies face limitations due to insufficient scenario diversity, complexity, and a single-perspective focus. To this end, we introduce AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios. Drawing on Dramaturgical Theory, AgentSense employs a bottom-up approach to create 1,225 diverse social scenarios constructed from extensive scripts. We evaluate LLM-driven agents through multi-turn interactions, emphasizing both goal completion and implicit reasoning. We analyze goals using ERG theory and conduct comprehensive experiments. Our findings highlight that LLMs struggle with goals in complex social scenarios, especially high-level growth needs, and even GPT-4o requires improvement in private information reasoning.
Overview of the CAIL 2023 Argument Mining Track
Jun 20, 2024
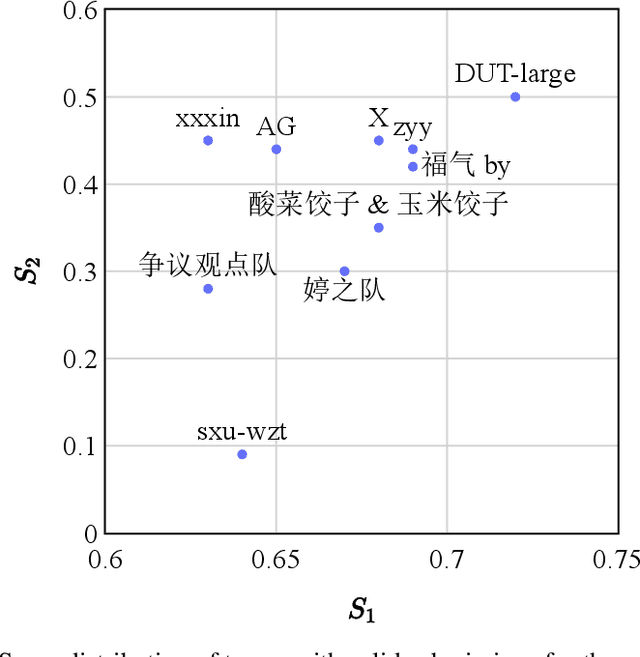
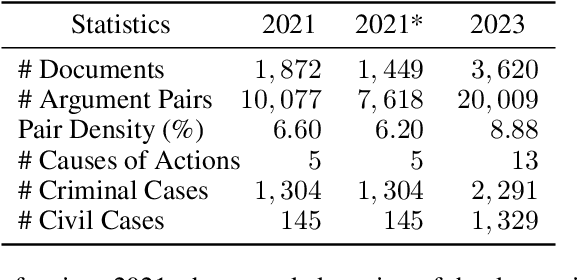
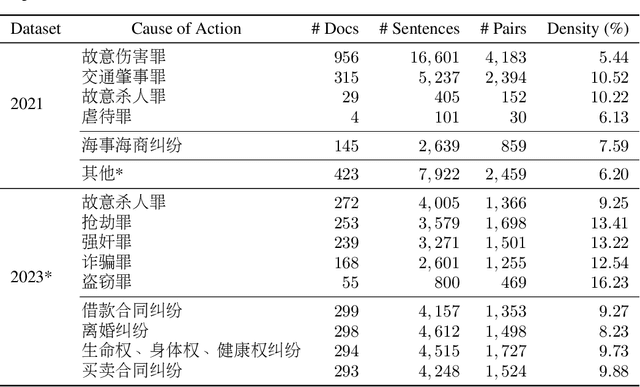
We give a detailed overview of the CAIL 2023 Argument Mining Track, one of the Chinese AI and Law Challenge (CAIL) 2023 tracks. The main goal of the track is to identify and extract interacting argument pairs in trial dialogs. It mainly uses summarized judgment documents but can also refer to trial recordings. The track consists of two stages, and we introduce the tasks designed for each stage; we also extend the data from previous events into a new dataset -- CAIL2023-ArgMine -- with annotated new cases from various causes of action. We outline several submissions that achieve the best results, including their methods for different stages. While all submissions rely on language models, they have incorporated strategies that may benefit future work in this field.
Debatrix: Multi-dimensinal Debate Judge with Iterative Chronological Analysis Based on LLM
Mar 12, 2024



How can we construct an automated debate judge to evaluate an extensive, vibrant, multi-turn debate? This task is challenging, as judging a debate involves grappling with lengthy texts, intricate argument relationships, and multi-dimensional assessments. At the same time, current research mainly focuses on short dialogues, rarely touching upon the evaluation of an entire debate. In this paper, by leveraging Large Language Models (LLMs), we propose Debatrix, which makes the analysis and assessment of multi-turn debates more aligned with majority preferences. Specifically, Debatrix features a vertical, iterative chronological analysis and a horizontal, multi-dimensional evaluation collaboration. To align with real-world debate scenarios, we introduced the PanelBench benchmark, comparing our system's performance to actual debate outcomes. The findings indicate a notable enhancement over directly using LLMs for debate evaluation. Source code and benchmark data are available online at https://github.com/ljcleo/Debatrix .
Hi-ArG: Exploring the Integration of Hierarchical Argumentation Graphs in Language Pretraining
Dec 01, 2023



The knowledge graph is a structure to store and represent knowledge, and recent studies have discussed its capability to assist language models for various applications. Some variations of knowledge graphs aim to record arguments and their relations for computational argumentation tasks. However, many must simplify semantic types to fit specific schemas, thus losing flexibility and expression ability. In this paper, we propose the Hierarchical Argumentation Graph (Hi-ArG), a new structure to organize arguments. We also introduce two approaches to exploit Hi-ArG, including a text-graph multi-modal model GreaseArG and a new pre-training framework augmented with graph information. Experiments on two argumentation tasks have shown that after further pre-training and fine-tuning, GreaseArG supersedes same-scale language models on these tasks, while incorporating graph information during further pre-training can also improve the performance of vanilla language models. Code for this paper is available at https://github.com/ljcleo/Hi-ArG .