 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent KTO: Reinforcing Strategic Interactions of Large Language Model in Language Game
Jan 24, 2025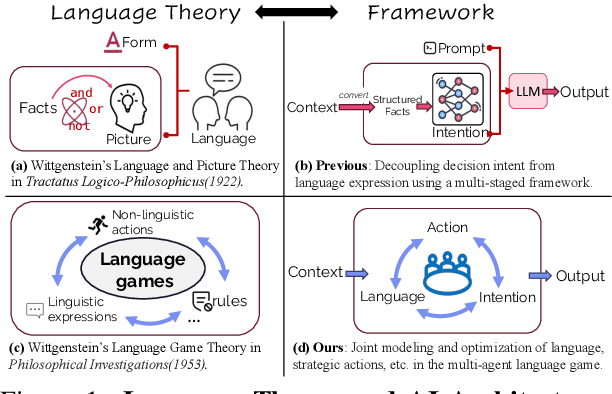



Achieving Artificial General Intelligence (AGI) requires AI agents that can not only make stratigic decisions but also engage in flexible and meaningful communication. Inspired by Wittgenstein's language game theory in Philosophical Investigations, we propose that language agents can learn through in-context interaction rather than traditional multi-stage frameworks that separate decision-making from language expression. Using Werewolf, a social deduction game that tests language understanding, strategic interaction, and adaptability, we develop the Multi-agent Kahneman & Tversky's Optimization (MaKTO). MaKTO engages diverse models in extensive gameplay to generate unpaired desirable and unacceptable responses, then employs KTO to refine the model's decision-making process. In 9-player Werewolf games, MaKTO achieves a 61% average win rate across various models, outperforming GPT-4o and two-stage RL agents by relative improvements of 23.0% and 10.9%, respectively. Notably, MaKTO also demonstrates human-like performance, winning 60% against expert players and showing only 49% detectability in Turing-style blind tests. These results showcase MaKTO's superior decision-making, strategic adaptation, and natural language generation in complex social deduction games.
AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios
Oct 25, 2024



Large language models (LLMs) are increasingly leveraged to empower autonomous agents to simulate human beings in various fields of behavioral research. However, evaluating their capacity to navigate complex social interactions remains a challenge. Previous studies face limitations due to insufficient scenario diversity, complexity, and a single-perspective focus. To this end, we introduce AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios. Drawing on Dramaturgical Theory, AgentSense employs a bottom-up approach to create 1,225 diverse social scenarios constructed from extensive scripts. We evaluate LLM-driven agents through multi-turn interactions, emphasizing both goal completion and implicit reasoning. We analyze goals using ERG theory and conduct comprehensive experiments. Our findings highlight that LLMs struggle with goals in complex social scenarios, especially high-level growth needs, and even GPT-4o requires improvement in private information reasoning.
AI-Press: A Multi-Agent News Generating and Feedback Simulation System Powered by Large Language Models
Oct 10, 2024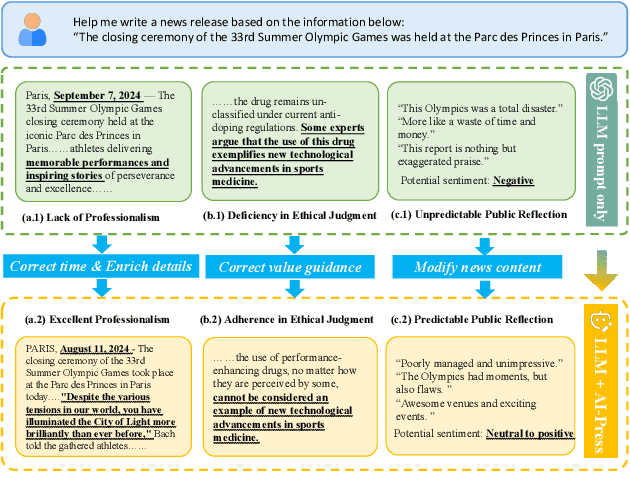
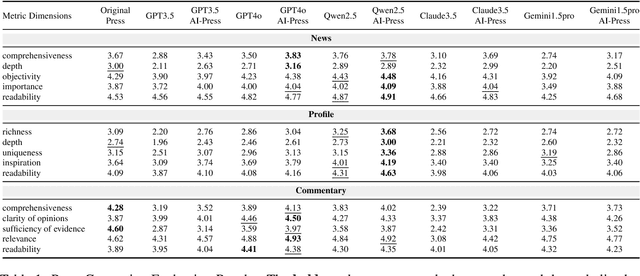
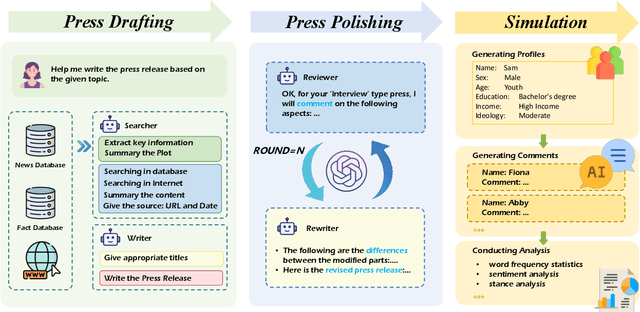
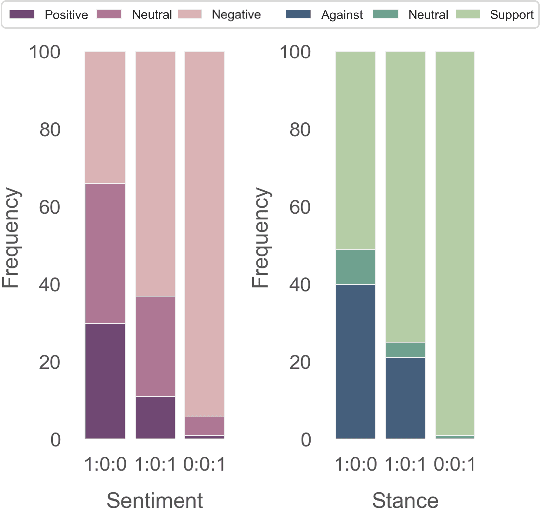
The rise of various social platforms has transformed journalism. The growing demand for news content has led to the increased use of large language models (LLMs) in news production due to their speed and cost-effectiveness. However, LLMs still encounter limitations in professionalism and ethical judgment in news generation. Additionally, predicting public feedback is usually difficult before news is released. To tackle these challenges, we introduce AI-Press, an automated news drafting and polishing system based on multi-agent collaboration and Retrieval-Augmented Generation. We develop a feedback simulation system that generates public feedback considering demographic distributions. Through extensive quantitative and qualitative evaluations, our system shows significant improvements in news-generating capabilities and verifies the effectiveness of public feedback simulation.
SoMeLVLM: A Large Vision Language Model for Social Media Processing
Feb 20, 2024

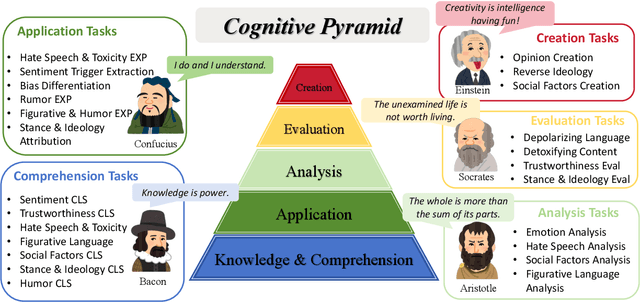

The growth of social media, characterized by its multimodal nature, has led to the emergence of diverse phenomena and challenges, which calls for an effective approach to uniformly solve automated tasks. The powerful Large Vision Language Models make it possible to handle a variety of tasks simultaneously, but even with carefully designed prompting methods, the general domain models often fall short in aligning with the unique speaking style and context of social media tasks. In this paper, we introduce a Large Vision Language Model for Social Media Processing (SoMeLVLM), which is a cognitive framework equipped with five key capabilities including knowledge & comprehension, application, analysis, evaluation, and creation. SoMeLVLM is designed to understand and generate realistic social media behavior. We have developed a 654k multimodal social media instruction-tuning dataset to support our cognitive framework and fine-tune our model. Our experiments demonstrate that SoMeLVLM achieves state-of-the-art performance in multiple social media tasks. Further analysis shows its significant advantages over baselines in terms of cognitive abilities.