 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartFI: Benchmarking Faithfulness and Insightfulness of Chart Descriptions from Multimodal Large Language Models
May 22, 2026Chart descriptions are essential for accessibility, cross-modal retrieval, and assisting readers in extracting insights from complex visualizations. As multimodal large language models (MLLMs) are increasingly adopted for automated chart description generation, a critical question arises: how faithfully and insightfully do these models actually describe charts? Current benchmarks fall short on two fronts: existing datasets consist of simple, homogeneous charts paired with shallow, fact-enumerating descriptions; and prevailing metrics fail to capture the multi-faceted nature of description quality. To address these gaps, we present the Chart Faithfulness and Insightfulness Benchmark (ChartFI-Bench). We first summarize four dimensions that characterize high-quality chart descriptions: factual accuracy, salient feature emphasis, domain-informed guidance, and chart-text complementarity. Guided by these dimensions, we construct a high-quality benchmark comprising 896 chart-description pairs, which feature visually complex charts and semantically rich descriptions. Furthermore, we design four aligned evaluation metrics -- Faithfulness, Coverage, Informativeness, and Acuity -- to systematically assess the quality of descriptions across these dimensions. Experiments conducted on mainstream MLLMs demonstrate the effectiveness of the proposed framework and reveal common weaknesses among existing models.
Viewpoint Recommendation for Point Cloud Labeling through Interaction Cost Modeling
Feb 11, 2026Semantic segmentation of 3D point clouds is important for many applications, such as autonomous driving. To train semantic segmentation models, labeled point cloud segmentation datasets are essential. Meanwhile, point cloud labeling is time-consuming for annotators, which typically involves tuning the camera viewpoint and selecting points by lasso. To reduce the time cost of point cloud labeling, we propose a viewpoint recommendation approach to reduce annotators' labeling time costs. We adapt Fitts' law to model the time cost of lasso selection in point clouds. Using the modeled time cost, the viewpoint that minimizes the lasso selection time cost is recommended to the annotator. We build a data labeling system for semantic segmentation of 3D point clouds that integrates our viewpoint recommendation approach. The system enables users to navigate to recommended viewpoints for efficient annotation. Through an ablation study, we observed that our approach effectively reduced the data labeling time cost. We also qualitatively compare our approach with previous viewpoint selection approaches on different datasets.
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025


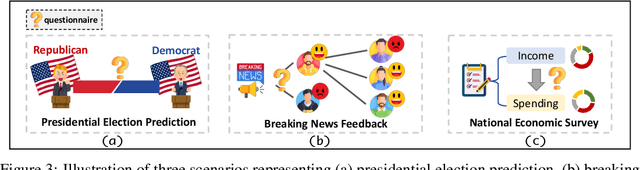
Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
SpecEE: Accelerating Large Language Model Inference with Speculative Early Exiting
Apr 11, 2025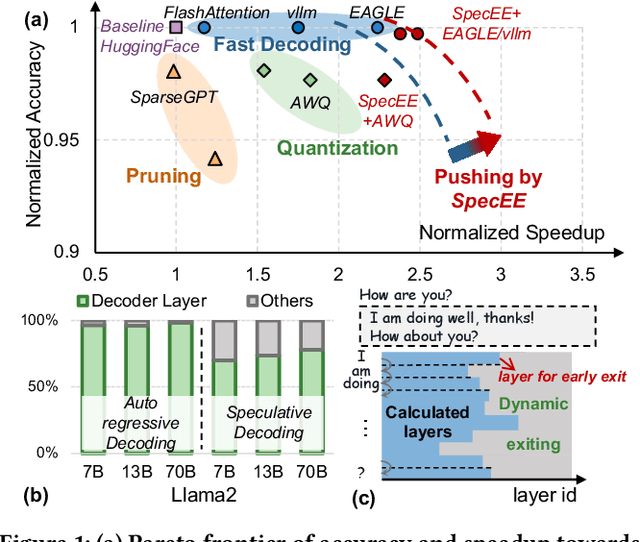
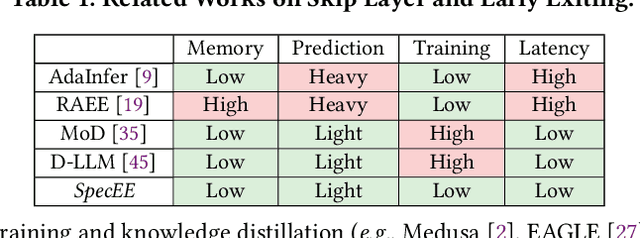
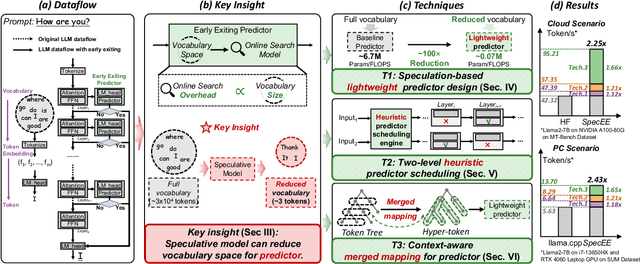
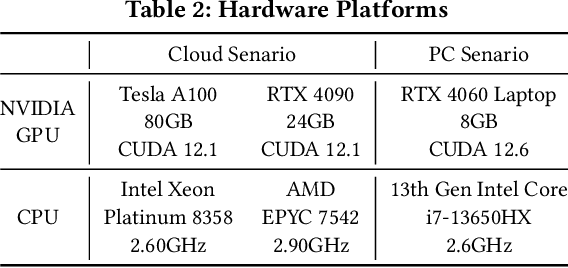
Early exiting has recently emerged as a promising technique for accelerating large language models (LLMs) by effectively reducing the hardware computation and memory access. In this paper, we present SpecEE, a fast LLM inference engine with speculative early exiting. (1) At the algorithm level, we propose the speculation-based lightweight predictor design by exploiting the probabilistic correlation between the speculative tokens and the correct results and high parallelism of GPUs. (2) At the system level, we point out that not all layers need a predictor and design the two-level heuristic predictor scheduling engine based on skewed distribution and contextual similarity. (3) At the mapping level, we point out that different decoding methods share the same essential characteristics, and propose the context-aware merged mapping for predictor with efficient GPU implementations to support speculative decoding, and form a framework for various existing orthogonal acceleration techniques (e.g., quantization and sparse activation) on cloud and personal computer (PC) scenarios, successfully pushing the Pareto frontier of accuracy and speedup. It is worth noting that SpecEE can be applied to any LLM by negligible training overhead in advance without affecting the model original parameters. Extensive experiments show that SpecEE achieves 2.25x and 2.43x speedup with Llama2-7B on cloud and PC scenarios respectively.
ChartInsighter: An Approach for Mitigating Hallucination in Time-series Chart Summary Generation with A Benchmark Dataset
Jan 16, 2025



Effective chart summary can significantly reduce the time and effort decision makers spend interpreting charts, enabling precise and efficient communication of data insights. Previous studies have faced challenges in generating accurate and semantically rich summaries of time-series data charts. In this paper, we identify summary elements and common hallucination types in the generation of time-series chart summaries, which serve as our guidelines for automatic generation. We introduce ChartInsighter, which automatically generates chart summaries of time-series data, effectively reducing hallucinations in chart summary generation. Specifically, we assign multiple agents to generate the initial chart summary and collaborate iteratively, during which they invoke external data analysis modules to extract insights and compile them into a coherent summary. Additionally, we implement a self-consistency test method to validate and correct our summary. We create a high-quality benchmark of charts and summaries, with hallucination types annotated on a sentence-by-sentence basis, facilitating the evaluation of the effectiveness of reducing hallucinations. Our evaluations using our benchmark show that our method surpasses state-of-the-art models, and that our summary hallucination rate is the lowest, which effectively reduces various hallucinations and improves summary quality. The benchmark is available at https://github.com/wangfen01/ChartInsighter.
In-situ Self-optimization of Quantum Dot Emission for Lasers by Machine-Learning Assisted Epitaxy
Nov 01, 2024Traditional methods for optimizing light source emissions rely on a time-consuming trial-and-error approach. While in-situ optimization of light source gain media emission during growth is ideal, it has yet to be realized. In this work, we integrate in-situ reflection high-energy electron diffraction (RHEED) with machine learning (ML) to correlate the surface reconstruction with the photoluminescence (PL) of InAs/GaAs quantum dots (QDs), which serve as the active region of lasers. A lightweight ResNet-GLAM model is employed for the real-time processing of RHEED data as input, enabling effective identification of optical performance. This approach guides the dynamic optimization of growth parameters, allowing real-time feedback control to adjust the QDs emission for lasers. We successfully optimized InAs QDs on GaAs substrates, with a 3.2-fold increase in PL intensity and a reduction in full width at half maximum (FWHM) from 36.69 meV to 28.17 meV under initially suboptimal growth conditions. Our automated, in-situ self-optimized lasers with 5-layer InAs QDs achieved electrically pumped continuous-wave operation at 1240 nm with a low threshold current of 150 A/cm2 at room temperature, an excellent performance comparable to samples grown through traditional manual multi-parameter optimization methods. These results mark a significant step toward intelligent, low-cost, and reproductive light emitters production.
ElectionSim: Massive Population Election Simulation Powered by Large Language Model Driven Agents
Oct 28, 2024



The massive population election simulation aims to model the preferences of specific groups in particular election scenarios. It has garnered significant attention for its potential to forecast real-world social trends. Traditional agent-based modeling (ABM) methods are constrained by their ability to incorporate complex individual background information and provide interactive prediction results. In this paper, we introduce ElectionSim, an innovative election simulation framework based on large language models, designed to support accurate voter simulations and customized distributions, together with an interactive platform to dialogue with simulated voters. We present a million-level voter pool sampled from social media platforms to support accurate individual simulation. We also introduce PPE, a poll-based presidential election benchmark to assess the performance of our framework under the U.S. presidential election scenario. Through extensive experiments and analyses, we demonstrate the effectiveness and robustness of our framework in U.S. presidential election simulations.
AI-Press: A Multi-Agent News Generating and Feedback Simulation System Powered by Large Language Models
Oct 10, 2024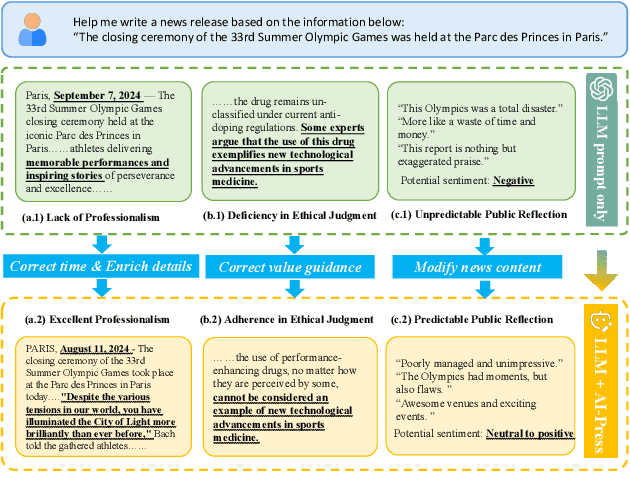
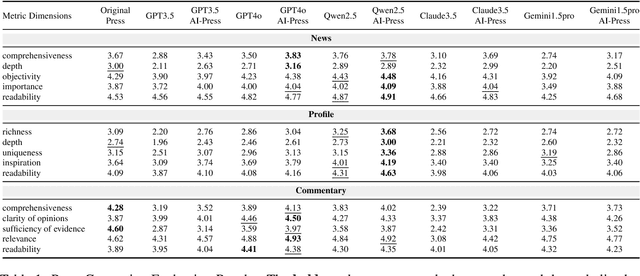
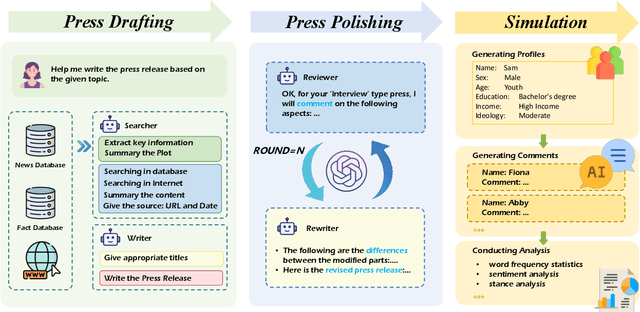
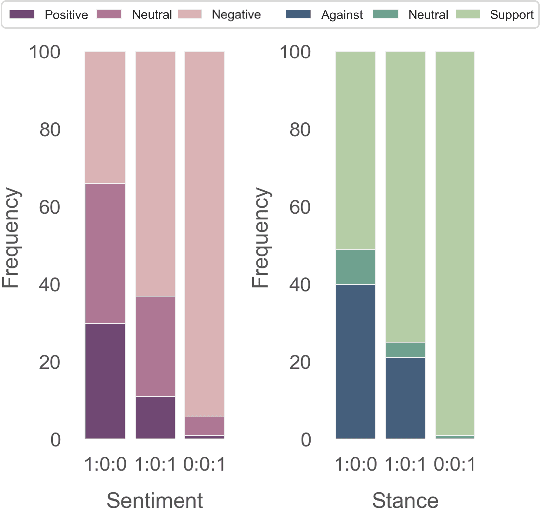
The rise of various social platforms has transformed journalism. The growing demand for news content has led to the increased use of large language models (LLMs) in news production due to their speed and cost-effectiveness. However, LLMs still encounter limitations in professionalism and ethical judgment in news generation. Additionally, predicting public feedback is usually difficult before news is released. To tackle these challenges, we introduce AI-Press, an automated news drafting and polishing system based on multi-agent collaboration and Retrieval-Augmented Generation. We develop a feedback simulation system that generates public feedback considering demographic distributions. Through extensive quantitative and qualitative evaluations, our system shows significant improvements in news-generating capabilities and verifies the effectiveness of public feedback simulation.
SoMeLVLM: A Large Vision Language Model for Social Media Processing
Feb 20, 2024

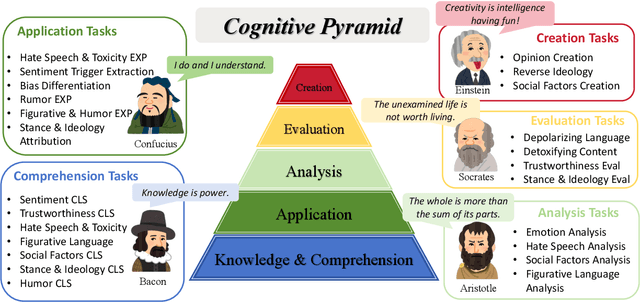

The growth of social media, characterized by its multimodal nature, has led to the emergence of diverse phenomena and challenges, which calls for an effective approach to uniformly solve automated tasks. The powerful Large Vision Language Models make it possible to handle a variety of tasks simultaneously, but even with carefully designed prompting methods, the general domain models often fall short in aligning with the unique speaking style and context of social media tasks. In this paper, we introduce a Large Vision Language Model for Social Media Processing (SoMeLVLM), which is a cognitive framework equipped with five key capabilities including knowledge & comprehension, application, analysis, evaluation, and creation. SoMeLVLM is designed to understand and generate realistic social media behavior. We have developed a 654k multimodal social media instruction-tuning dataset to support our cognitive framework and fine-tune our model. Our experiments demonstrate that SoMeLVLM achieves state-of-the-art performance in multiple social media tasks. Further analysis shows its significant advantages over baselines in terms of cognitive abilities.
A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models
Mar 18, 2023
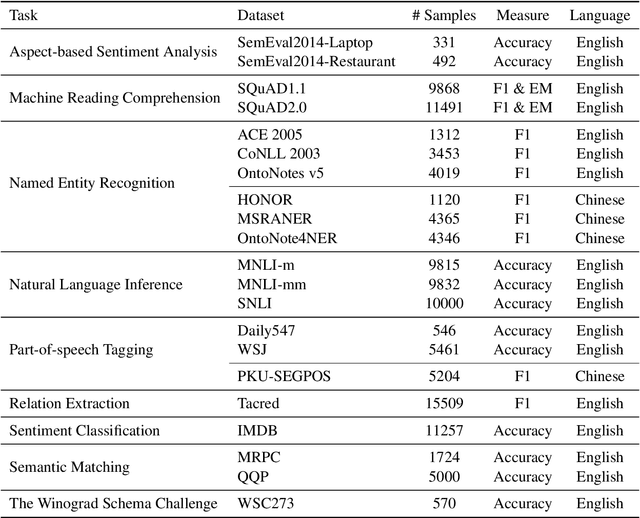
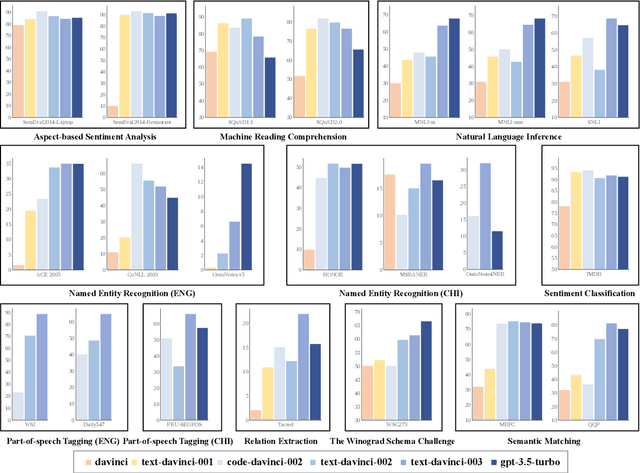
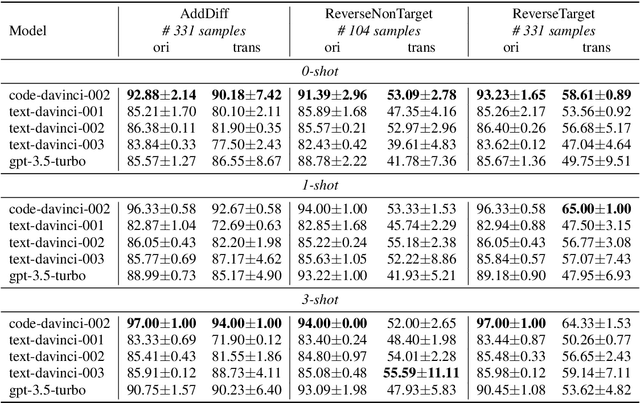
GPT series models, such as GPT-3, CodeX, InstructGPT, ChatGPT, and so on, have gained considerable attention due to their exceptional natural language processing capabilities. However, despite the abundance of research on the difference in capabilities between GPT series models and fine-tuned models, there has been limited attention given to the evolution of GPT series models' capabilities over time. To conduct a comprehensive analysis of the capabilities of GPT series models, we select six representative models, comprising two GPT-3 series models (i.e., davinci and text-davinci-001) and four GPT-3.5 series models (i.e., code-davinci-002, text-davinci-002, text-davinci-003, and gpt-3.5-turbo). We evaluate their performance on nine natural language understanding (NLU) tasks using 21 datasets. In particular, we compare the performance and robustness of different models for each task under zero-shot and few-shot scenarios. Our extensive experiments reveal that the overall ability of GPT series models on NLU tasks does not increase gradually as the models evolve, especially with the introduction of the RLHF training strategy. While this strategy enhances the models' ability to generate human-like responses, it also compromises their ability to solve some tasks. Furthermore, our findings indicate that there is still room for improvement in areas such as model robustness.