 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Super-Resolution as Text-Guided Details Generation
Paper and Code
Jul 14, 2022

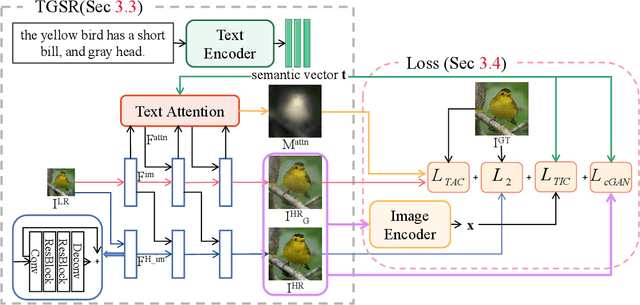
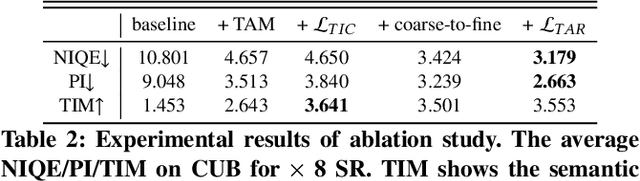
Deep neural networks have greatly promoted the performance of single image super-resolution (SISR). Conventional methods still resort to restoring the single high-resolution (HR) solution only based on the input of image modality. However, the image-level information is insufficient to predict adequate details and photo-realistic visual quality facing large upscaling factors (x8, x16). In this paper, we propose a new perspective that regards the SISR as a semantic image detail enhancement problem to generate semantically reasonable HR image that are faithful to the ground truth. To enhance the semantic accuracy and the visual quality of the reconstructed image, we explore the multi-modal fusion learning in SISR by proposing a Text-Guided Super-Resolution (TGSR) framework, which can effectively utilize the information from the text and image modalities. Different from existing methods, the proposed TGSR could generate HR image details that match the text descriptions through a coarse-to-fine process. Extensive experiments and ablation studies demonstrate the effect of the TGSR, which exploits the text reference to recover realistic images.