 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Perceive "Where": Spatial Pretext Tasks for Robust Self-Supervised Learning
May 11, 2026Existing self-supervised learning (SSL) methods primarily learn object-invariant representations but often neglect the spatial structure and relationships among object parts. To address this limitation, we introduce Spatial Prediction (SP), a spatially aware pretext regression task that predicts the relative position and scale between a pair of disentangled local views from the same image. By modeling part-to-part relationships in a continuous geometric space, SP encourages representations to capture fine-grained spatial dependencies beyond invariant categorical semantics, thereby learning the compositional structure of visual scenes. SP is implemented as a decoupled plug-in and can be seamlessly integrated into diverse SSL frameworks. Extensive experiments show consistent improvements across image recognition, fine-grained classification, semantic segmentation, and depth estimation, as well as substantial gains in out-of-distribution robustness for object recognition. To evaluate spatial reasoning, we introduce (1) a position and scale prediction task on image patch pairs and (2) a jigsaw understanding task requiring patch reordering and recognition after reconstruction. Strong performance on these tasks indicates improved spatial structure and geometric awareness. Overall, explicitly modeling spatial information provides an effective inductive bias for SSL, leading to more structured representations and better generalization. Code and models will be released.
Learning to See Through a Baby's Eyes: Early Visual Diets Enable Robust Visual Intelligence in Humans and Machines
Nov 18, 2025Newborns perceive the world with low-acuity, color-degraded, and temporally continuous vision, which gradually sharpens as infants develop. To explore the ecological advantages of such staged "visual diets", we train self-supervised learning (SSL) models on object-centric videos under constraints that simulate infant vision: grayscale-to-color (C), blur-to-sharp (A), and preserved temporal continuity (T)-collectively termed CATDiet. For evaluation, we establish a comprehensive benchmark across ten datasets, covering clean and corrupted image recognition, texture-shape cue conflict tests, silhouette recognition, depth-order classification, and the visual cliff paradigm. All CATDiet variants demonstrate enhanced robustness in object recognition, despite being trained solely on object-centric videos. Remarkably, models also exhibit biologically aligned developmental patterns, including neural plasticity changes mirroring synaptic density in macaque V1 and behaviors resembling infants' visual cliff responses. Building on these insights, CombDiet initializes SSL with CATDiet before standard training while preserving temporal continuity. Trained on object-centric or head-mounted infant videos, CombDiet outperforms standard SSL on both in-domain and out-of-domain object recognition and depth perception. Together, these results suggest that the developmental progression of early infant visual experience offers a powerful reverse-engineering framework for understanding the emergence of robust visual intelligence in machines. All code, data, and models will be publicly released.
Highly Undersampled MRI Reconstruction via a Single Posterior Sampling of Diffusion Models
May 13, 2025Incoherent k-space under-sampling and deep learning-based reconstruction methods have shown great success in accelerating MRI. However, the performance of most previous methods will degrade dramatically under high acceleration factors, e.g., 8$\times$ or higher. Recently, denoising diffusion models (DM) have demonstrated promising results in solving this issue; however, one major drawback of the DM methods is the long inference time due to a dramatic number of iterative reverse posterior sampling steps. In this work, a Single Step Diffusion Model-based reconstruction framework, namely SSDM-MRI, is proposed for restoring MRI images from highly undersampled k-space. The proposed method achieves one-step reconstruction by first training a conditional DM and then iteratively distilling this model. Comprehensive experiments were conducted on both publicly available fastMRI images and an in-house multi-echo GRE (QSM) subject. Overall, the results showed that SSDM-MRI outperformed other methods in terms of numerical metrics (PSNR and SSIM), qualitative error maps, image fine details, and latent susceptibility information hidden in MRI phase images. In addition, the reconstruction time for a 320*320 brain slice of SSDM-MRI is only 0.45 second, which is only comparable to that of a simple U-net, making it a highly effective solution for MRI reconstruction tasks.
Unforgettable Lessons from Forgettable Images: Intra-Class Memorability Matters in Computer Vision Tasks
Dec 30, 2024



We introduce intra-class memorability, where certain images within the same class are more memorable than others despite shared category characteristics. To investigate what features make one object instance more memorable than others, we design and conduct human behavior experiments, where participants are shown a series of images one at a time, and they must identify when the current item matches the item presented a few steps back in the sequence. To quantify memorability, we propose the Intra-Class Memorability score (ICMscore), a novel metric that incorporates the temporal intervals between repeated image presentations into its calculation. Our contributions open new pathways in understanding intra-class memorability by scrutinizing fine-grained visual features that result in the least and most memorable images and laying the groundwork for real-world applications in cognitive science and computer vision.
Make Me Happier: Evoking Emotions Through Image Diffusion Models
Mar 13, 2024Despite the rapid progress in image generation, emotional image editing remains under-explored. The semantics, context, and structure of an image can evoke emotional responses, making emotional image editing techniques valuable for various real-world applications, including treatment of psychological disorders, commercialization of products, and artistic design. For the first time, we present a novel challenge of emotion-evoked image generation, aiming to synthesize images that evoke target emotions while retaining the semantics and structures of the original scenes. To address this challenge, we propose a diffusion model capable of effectively understanding and editing source images to convey desired emotions and sentiments. Moreover, due to the lack of emotion editing datasets, we provide a unique dataset consisting of 340,000 pairs of images and their emotion annotations. Furthermore, we conduct human psychophysics experiments and introduce four new evaluation metrics to systematically benchmark all the methods. Experimental results demonstrate that our method surpasses all competitive baselines. Our diffusion model is capable of identifying emotional cues from original images, editing images that elicit desired emotions, and meanwhile, preserving the semantic structure of the original images. All code, model, and data will be made public.
Multi-Modality Deep Network for JPEG Artifacts Reduction
May 04, 2023



In recent years, many convolutional neural network-based models are designed for JPEG artifacts reduction, and have achieved notable progress. However, few methods are suitable for extreme low-bitrate image compression artifacts reduction. The main challenge is that the highly compressed image loses too much information, resulting in reconstructing high-quality image difficultly. To address this issue, we propose a multimodal fusion learning method for text-guided JPEG artifacts reduction, in which the corresponding text description not only provides the potential prior information of the highly compressed image, but also serves as supplementary information to assist in image deblocking. We fuse image features and text semantic features from the global and local perspectives respectively, and design a contrastive loss built upon contrastive learning to produce visually pleasing results. Extensive experiments, including a user study, prove that our method can obtain better deblocking results compared to the state-of-the-art methods.
Rethinking Super-Resolution as Text-Guided Details Generation
Jul 14, 2022

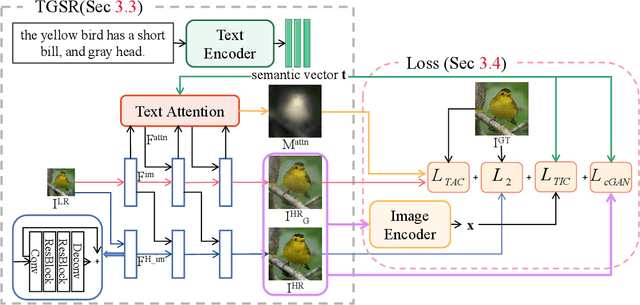
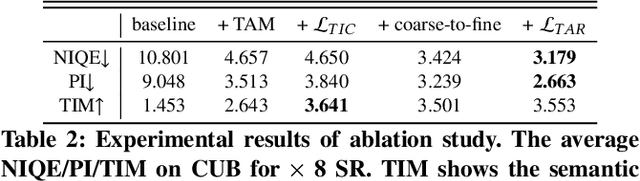
Deep neural networks have greatly promoted the performance of single image super-resolution (SISR). Conventional methods still resort to restoring the single high-resolution (HR) solution only based on the input of image modality. However, the image-level information is insufficient to predict adequate details and photo-realistic visual quality facing large upscaling factors (x8, x16). In this paper, we propose a new perspective that regards the SISR as a semantic image detail enhancement problem to generate semantically reasonable HR image that are faithful to the ground truth. To enhance the semantic accuracy and the visual quality of the reconstructed image, we explore the multi-modal fusion learning in SISR by proposing a Text-Guided Super-Resolution (TGSR) framework, which can effectively utilize the information from the text and image modalities. Different from existing methods, the proposed TGSR could generate HR image details that match the text descriptions through a coarse-to-fine process. Extensive experiments and ablation studies demonstrate the effect of the TGSR, which exploits the text reference to recover realistic images.
Ensemble Making Few-Shot Learning Stronger
May 12, 2021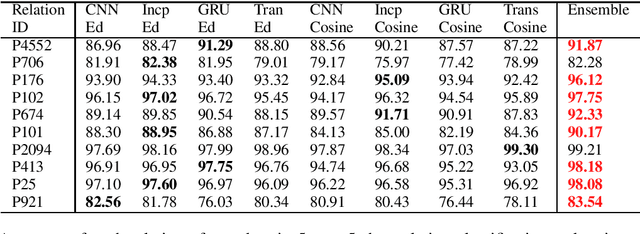
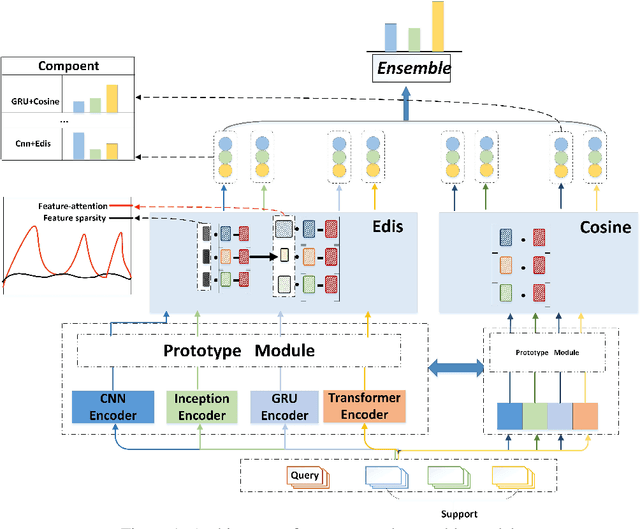
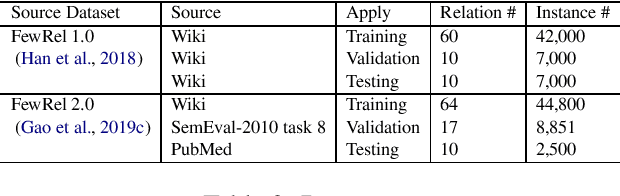
Few-shot learning has been proposed and rapidly emerging as a viable means for completing various tasks. Many few-shot models have been widely used for relation learning tasks. However, each of these models has a shortage of capturing a certain aspect of semantic features, for example, CNN on long-range dependencies part, Transformer on local features. It is difficult for a single model to adapt to various relation learning, which results in the high variance problem. Ensemble strategy could be competitive on improving the accuracy of few-shot relation extraction and mitigating high variance risks. This paper explores an ensemble approach to reduce the variance and introduces fine-tuning and feature attention strategies to calibrate relation-level features. Results on several few-shot relation learning tasks show that our model significantly outperforms the previous state-of-the-art models.
Point Proposal Network for Reconstructing 3D Particle Endpoints with Sub-Pixel Precision in Liquid Argon Time Projection Chambers
Jul 10, 2020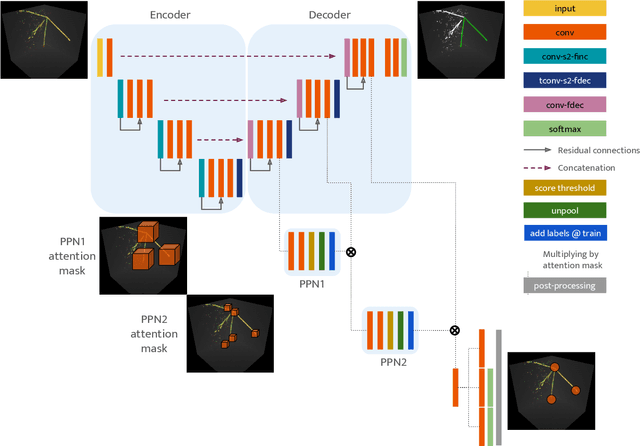

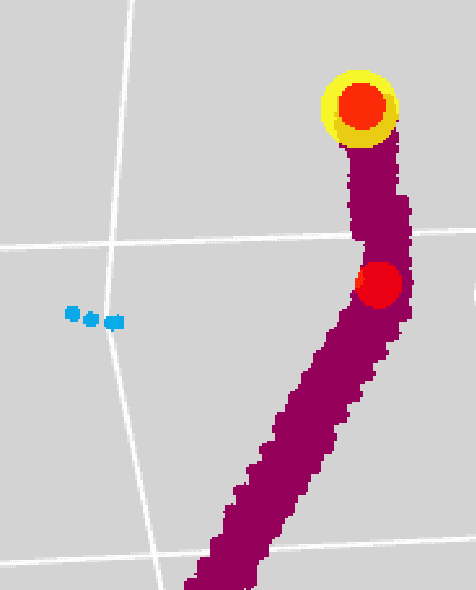
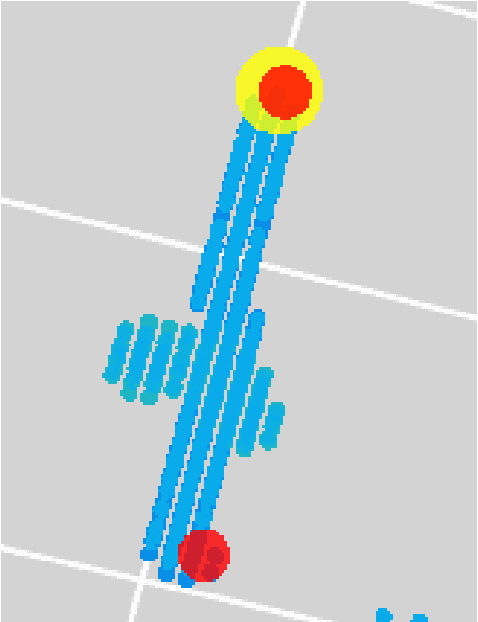
Liquid Argon Time Projection Chambers (LArTPC) are particle imaging detectors recording 2D or 3D images of trajectories of charged particles. Identifying points of interest in these images, namely the initial and terminal points of track-like particle trajectories such as muons and protons, and the initial points of electromagnetic shower-like particle trajectories such as electrons and gamma rays, is a crucial step of identifying and analyzing these particles and impacts the inference of physics signals such as neutrino interaction. The Point Proposal Network is designed to discover these specific points of interest. The algorithm predicts with a sub-voxel precision their spatial location, and also determines the category of the identified points of interest. Using as a benchmark the PILArNet public LArTPC data sample in which the voxel resolution is 3mm/voxel, our algorithm successfully predicted 96.8% and 97.8% of 3D points within a distance of 3 and 10~voxels from the provided true point locations respectively. For the predicted 3D points within 3 voxels of the closest true point locations, the median distance is found to be 0.25 voxels, achieving the sub-voxel level precision. In addition, we report our analysis of the mistakes where our algorithm prediction differs from the provided true point positions by more than 10~voxels. Among 50 mistakes visually scanned, 25 were due to the definition of true position location, 15 were legitimate mistakes where a physicist cannot visually disagree with the algorithm's prediction, and 10 were genuine mistakes that we wish to improve in the future. Further, using these predicted points, we demonstrate a simple algorithm to cluster 3D voxels into individual track-like particle trajectories with a clustering efficiency, purity, and Adjusted Rand Index of 96%, 93%, and 91% respectively.
Scalable, Proposal-free Instance Segmentation Network for 3D Pixel Clustering and Particle Trajectory Reconstruction in Liquid Argon Time Projection Chambers
Jul 06, 2020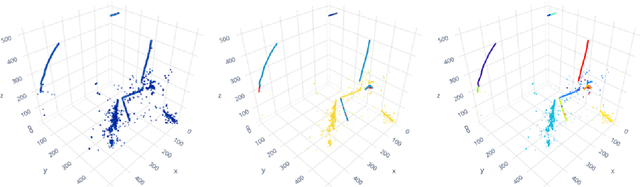
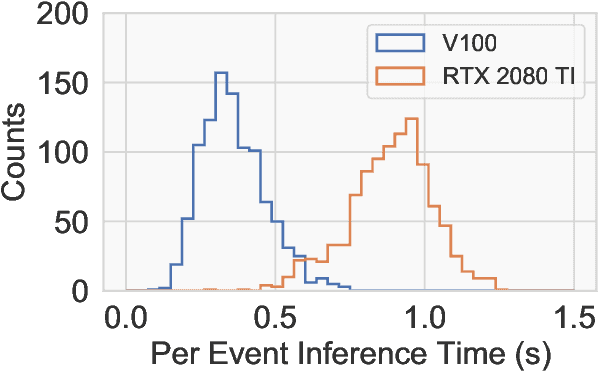
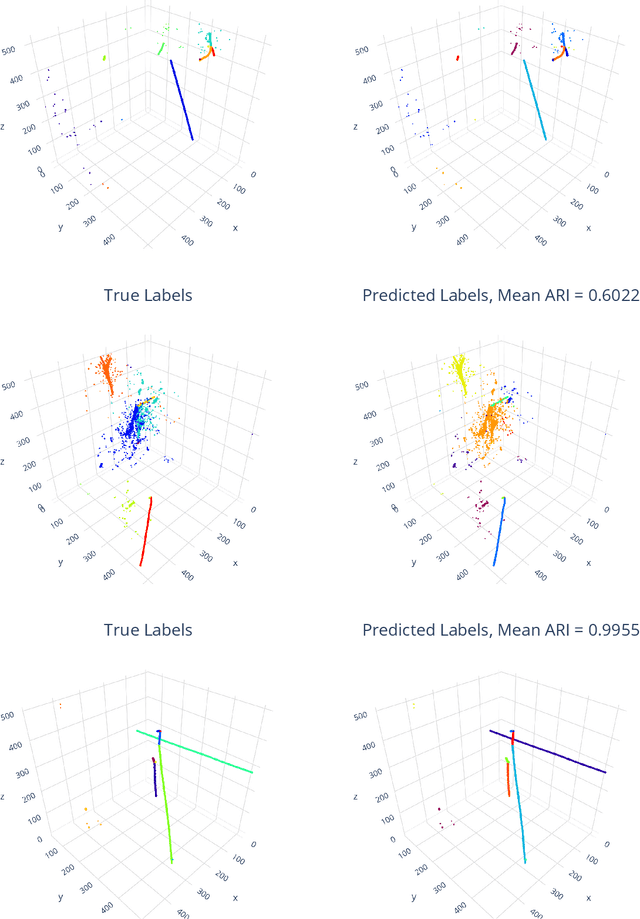
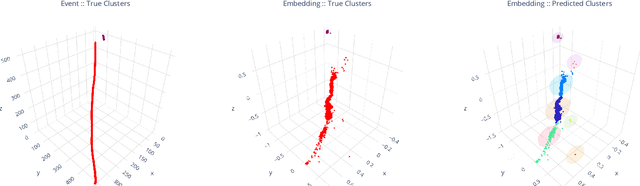
Liquid Argon Time Projection Chambers (LArTPCs) are high resolution particle imaging detectors, employed by accelerator-based neutrino oscillation experiments for high precision physics measurements. While images of particle trajectories are intuitive to analyze for physicists, the development of a high quality, automated data reconstruction chain remains challenging. One of the most critical reconstruction steps is particle clustering: the task of grouping 3D image pixels into different particle instances that share the same particle type. In this paper, we propose the first scalable deep learning algorithm for particle clustering in LArTPC data using sparse convolutional neural networks (SCNN). Building on previous works on SCNNs and proposal free instance segmentation, we build an end-to-end trainable instance segmentation network that learns an embedding of the image pixels to perform point cloud clustering in a transformed space. We benchmark the performance of our algorithm on PILArNet, a public 3D particle imaging dataset, with respect to common clustering evaluation metrics. 3D pixels were successfully clustered into individual particle trajectories with 90% of them having an adjusted Rand index score greater than 92% with a mean pixel clustering efficiency and purity above 96%. This work contributes to the development of an end-to-end optimizable full data reconstruction chain for LArTPCs, in particular pixel-based 3D imaging detectors including the near detector of the Deep Underground Neutrino Experiment. Our algorithm is made available in the open access repository, and we share our Singularity software container, which can be used to reproduce our work on the dataset.