 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Incremental Inference
Jan 27, 2026Tabular data is a fundamental form of data structure. The evolution of table analysis tools reflects humanity's continuous progress in data acquisition, management, and processing. The dynamic changes in table columns arise from technological advancements, changing needs, data integration, etc. However, the standard process of training AI models on tables with fixed columns and then performing inference is not suitable for handling dynamically changed tables. Therefore, new methods are needed for efficiently handling such tables in an unsupervised manner. In this paper, we introduce a new task, Tabular Incremental Inference (TabII), which aims to enable trained models to incorporate new columns during the inference stage, enhancing the practicality of AI models in scenarios where tables are dynamically changed. Furthermore, we demonstrate that this new task can be framed as an optimization problem based on the information bottleneck theory, which emphasizes that the key to an ideal tabular incremental inference approach lies in minimizing mutual information between tabular data and representation while maximizing between representation and task labels. Under this guidance, we design a TabII method with Large Language Model placeholders and Pretrained TabAdapter to provide external knowledge and Incremental Sample Condensation blocks to condense the task-relevant information given by incremental column attributes. Experimental results across eight public datasets show that TabII effectively utilizes incremental attributes, achieving state-of-the-art performance.
MicroVQA++: High-Quality Microscopy Reasoning Dataset with Weakly Supervised Graphs for Multimodal Large Language Model
Nov 14, 2025Multimodal Large Language Models are increasingly applied to biomedical imaging, yet scientific reasoning for microscopy remains limited by the scarcity of large-scale, high-quality training data. We introduce MicroVQA++, a three-stage, large-scale and high-quality microscopy VQA corpus derived from the BIOMEDICA archive. Stage one bootstraps supervision from expert-validated figure-caption pairs sourced from peer-reviewed articles. Stage two applies HiCQA-Graph, a novel heterogeneous graph over images, captions, and QAs that fuses NLI-based textual entailment, CLIP-based vision-language alignment, and agent signals to identify and filter inconsistent samples. Stage three uses a MultiModal Large Language Model (MLLM) agent to generate multiple-choice questions (MCQ) followed by human screening. The resulting release comprises a large training split and a human-checked test split whose Bloom's level hard-sample distribution exceeds the MicroVQA benchmark. Our work delivers (i) a quality-controlled dataset that couples expert literature with graph-based filtering and human refinement; (ii) HiCQA-Graph, the first graph that jointly models (image, caption, QA) for cross-modal consistency filtering; (iii) evidence that careful data construction enables 4B-scale MLLMs to reach competitive microscopy reasoning performance (e.g., GPT-5) and achieve state-of-the-art performance among open-source MLLMs. Code and dataset will be released after the review process concludes.
Unifying Segment Anything in Microscopy with Multimodal Large Language Model
May 16, 2025Accurate segmentation of regions of interest in biomedical images holds substantial value in image analysis. Although several foundation models for biomedical segmentation have currently achieved excellent performance on certain datasets, they typically demonstrate sub-optimal performance on unseen domain data. We owe the deficiency to lack of vision-language knowledge before segmentation. Multimodal Large Language Models (MLLMs) bring outstanding understanding and reasoning capabilities to multimodal tasks, which inspires us to leverage MLLMs to inject Vision-Language Knowledge (VLK), thereby enabling vision models to demonstrate superior generalization capabilities on cross-domain datasets. In this paper, we propose using MLLMs to guide SAM in learning microscopy crose-domain data, unifying Segment Anything in Microscopy, named uLLSAM. Specifically, we propose the Vision-Language Semantic Alignment (VLSA) module, which injects VLK into Segment Anything Model (SAM). We find that after SAM receives global VLK prompts, its performance improves significantly, but there are deficiencies in boundary contour perception. Therefore, we further propose Semantic Boundary Regularization (SBR) to prompt SAM. Our method achieves performance improvements of 7.71% in Dice and 12.10% in SA across 9 in-domain microscopy datasets, achieving state-of-the-art performance. Our method also demonstrates improvements of 6.79% in Dice and 10.08% in SA across 10 out-ofdomain datasets, exhibiting strong generalization capabilities. Code is available at https://github.com/ieellee/uLLSAM.
MM-Skin: Enhancing Dermatology Vision-Language Model with an Image-Text Dataset Derived from Textbooks
May 09, 2025Medical vision-language models (VLMs) have shown promise as clinical assistants across various medical fields. However, specialized dermatology VLM capable of delivering professional and detailed diagnostic analysis remains underdeveloped, primarily due to less specialized text descriptions in current dermatology multimodal datasets. To address this issue, we propose MM-Skin, the first large-scale multimodal dermatology dataset that encompasses 3 imaging modalities, including clinical, dermoscopic, and pathological and nearly 10k high-quality image-text pairs collected from professional textbooks. In addition, we generate over 27k diverse, instruction-following vision question answering (VQA) samples (9 times the size of current largest dermatology VQA dataset). Leveraging public datasets and MM-Skin, we developed SkinVL, a dermatology-specific VLM designed for precise and nuanced skin disease interpretation. Comprehensive benchmark evaluations of SkinVL on VQA, supervised fine-tuning (SFT) and zero-shot classification tasks across 8 datasets, reveal its exceptional performance for skin diseases in comparison to both general and medical VLM models. The introduction of MM-Skin and SkinVL offers a meaningful contribution to advancing the development of clinical dermatology VLM assistants. MM-Skin is available at https://github.com/ZwQ803/MM-Skin
Non-Uniform Class-Wise Coreset Selection: Characterizing Category Difficulty for Data-Efficient Transfer Learning
Apr 17, 2025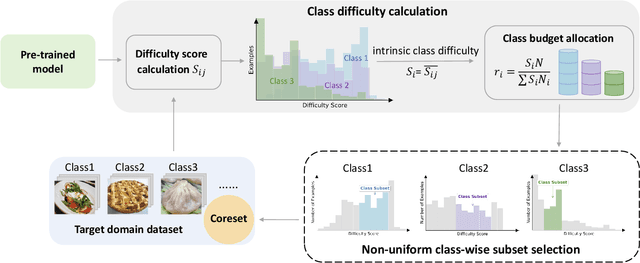
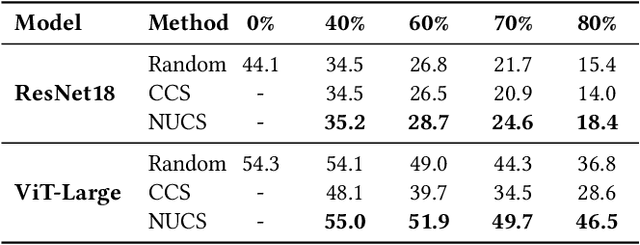
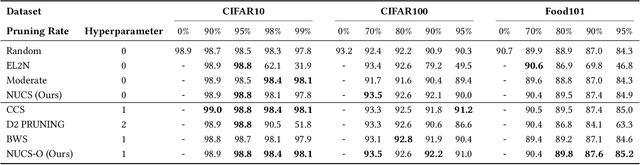
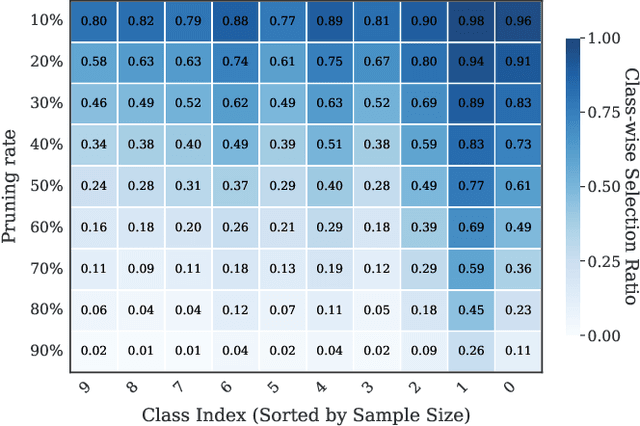
As transfer learning models and datasets grow larger, efficient adaptation and storage optimization have become critical needs. Coreset selection addresses these challenges by identifying and retaining the most informative samples, constructing a compact subset for target domain training. However, current methods primarily rely on instance-level difficulty assessments, overlooking crucial category-level characteristics and consequently under-representing minority classes. To overcome this limitation, we propose Non-Uniform Class-Wise Coreset Selection (NUCS), a novel framework that integrates both class-level and instance-level criteria. NUCS automatically allocates data selection budgets for each class based on intrinsic category difficulty and adaptively selects samples within optimal difficulty ranges. By explicitly incorporating category-specific insights, our approach achieves a more balanced and representative coreset, addressing key shortcomings of prior methods. Comprehensive theoretical analysis validates the rationale behind adaptive budget allocation and sample selection, while extensive experiments across 14 diverse datasets and model architectures demonstrate NUCS's consistent improvements over state-of-the-art methods, achieving superior accuracy and computational efficiency. Notably, on CIFAR100 and Food101, NUCS matches full-data training accuracy while retaining just 30% of samples and reducing computation time by 60%. Our work highlights the importance of characterizing category difficulty in coreset selection, offering a robust and data-efficient solution for transfer learning.
Scaling Laws for Data-Efficient Visual Transfer Learning
Apr 17, 2025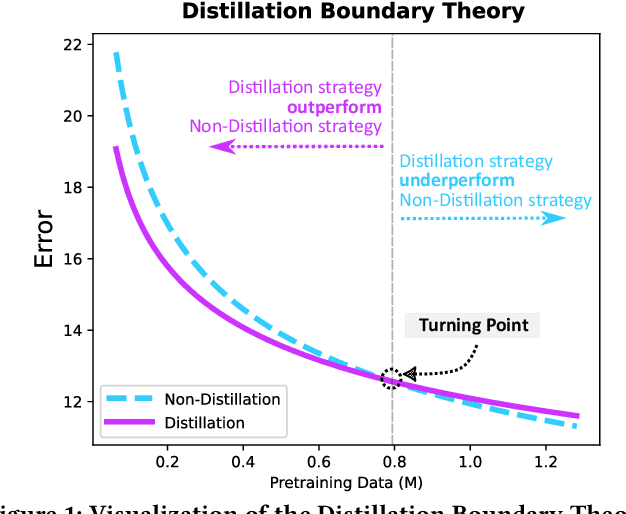
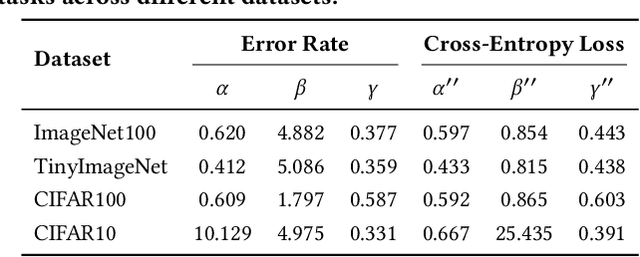
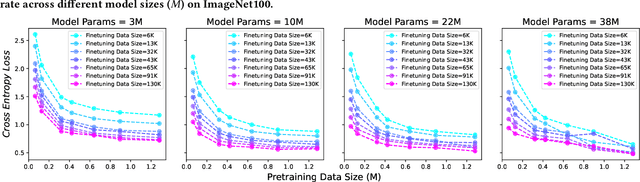
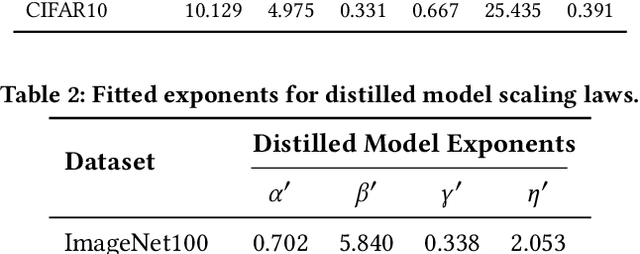
Current scaling laws for visual AI models focus predominantly on large-scale pretraining, leaving a critical gap in understanding how performance scales for data-constrained downstream tasks. To address this limitation, this paper establishes the first practical framework for data-efficient scaling laws in visual transfer learning, addressing two fundamental questions: 1) How do scaling behaviors shift when downstream tasks operate with limited data? 2) What governs the efficacy of knowledge distillation under such constraints? Through systematic analysis of vision tasks across data regimes (1K-1M samples), we propose the distillation boundary theory, revealing a critical turning point in distillation efficiency: 1) Distillation superiority: In data-scarce conditions, distilled models significantly outperform their non-distillation counterparts, efficiently leveraging inherited knowledge to compensate for limited training samples. 2) Pre-training dominance: As pre-training data increases beyond a critical threshold, non-distilled models gradually surpass distilled versions, suggesting diminishing returns from knowledge inheritance when sufficient task-specific data becomes available. Empirical validation across various model scales (2.5M to 38M parameters) and data volumes demonstrate these performance inflection points, with error difference curves transitioning from positive to negative values at critical data thresholds, confirming our theoretical predictions. This work redefines scaling laws for data-limited regimes, bridging the knowledge gap between large-scale pretraining and practical downstream adaptation, addressing a critical barrier to understanding vision model scaling behaviors and optimizing computational resource allocation.
FacialFlowNet: Advancing Facial Optical Flow Estimation with a Diverse Dataset and a Decomposed Model
Sep 09, 2024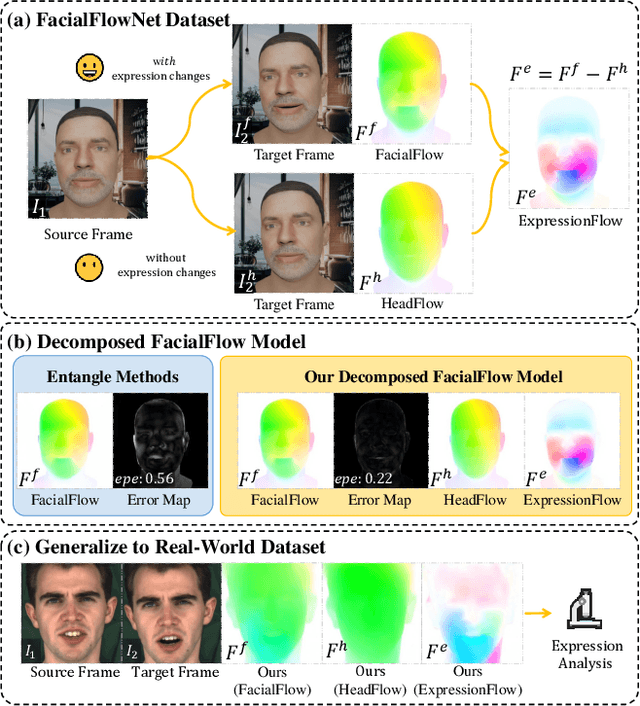


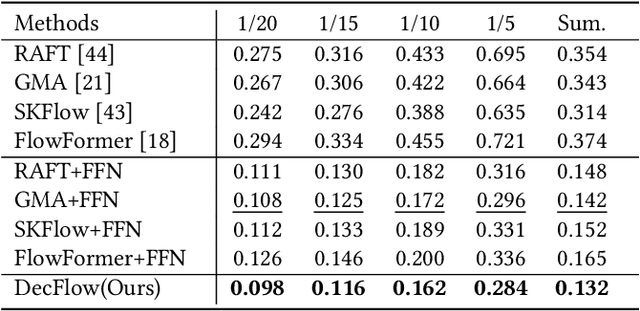
Facial movements play a crucial role in conveying altitude and intentions, and facial optical flow provides a dynamic and detailed representation of it. However, the scarcity of datasets and a modern baseline hinders the progress in facial optical flow research. This paper proposes FacialFlowNet (FFN), a novel large-scale facial optical flow dataset, and the Decomposed Facial Flow Model (DecFlow), the first method capable of decomposing facial flow. FFN comprises 9,635 identities and 105,970 image pairs, offering unprecedented diversity for detailed facial and head motion analysis. DecFlow features a facial semantic-aware encoder and a decomposed flow decoder, excelling in accurately estimating and decomposing facial flow into head and expression components. Comprehensive experiments demonstrate that FFN significantly enhances the accuracy of facial flow estimation across various optical flow methods, achieving up to an 11% reduction in Endpoint Error (EPE) (from 3.91 to 3.48). Moreover, DecFlow, when coupled with FFN, outperforms existing methods in both synthetic and real-world scenarios, enhancing facial expression analysis. The decomposed expression flow achieves a substantial accuracy improvement of 18% (from 69.1% to 82.1%) in micro-expressions recognition. These contributions represent a significant advancement in facial motion analysis and optical flow estimation. Codes and datasets can be found.
Maximizing V-information for Pre-training Superior Foundation Models
Aug 13, 2024Pre-training foundation models on large-scale datasets demonstrates exceptional performance. However, recent research questions this traditional notion, exploring whether an increase in pre-training data always leads to enhanced model performance. To address this issue, data-effective learning approaches have been introduced. However, current methods in this area lack a clear standard for sample selection. Our experiments reveal that by maximizing V-information, sample selection can be framed as an optimization problem, enabling effective improvement in model performance even with fewer samples. Under this guidance, we develop an optimal data-effective learning method (OptiDEL) to maximize V-information. The OptiDEL method generates hard samples to achieve or even exceed the performance of models trained on the full dataset while using substantially less data. We compare the OptiDEL method with state-of-the-art approaches finding that OptiDEL consistently outperforms existing approaches across different datasets, with foundation models trained on only 5% of the pre-training data surpassing the performance of those trained on the full dataset.
Addressing Imbalance for Class Incremental Learning in Medical Image Classification
Jul 18, 2024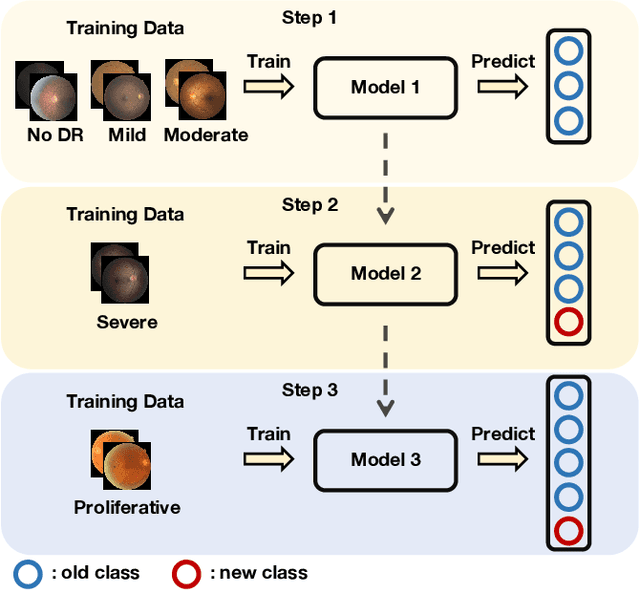
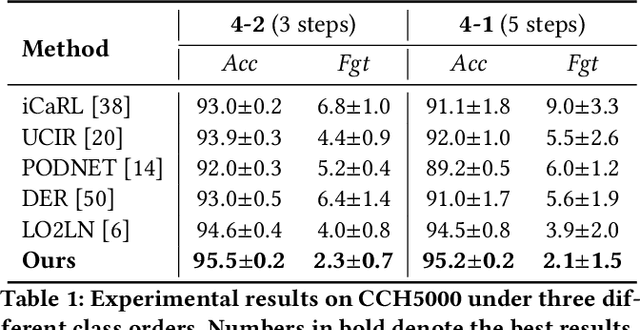
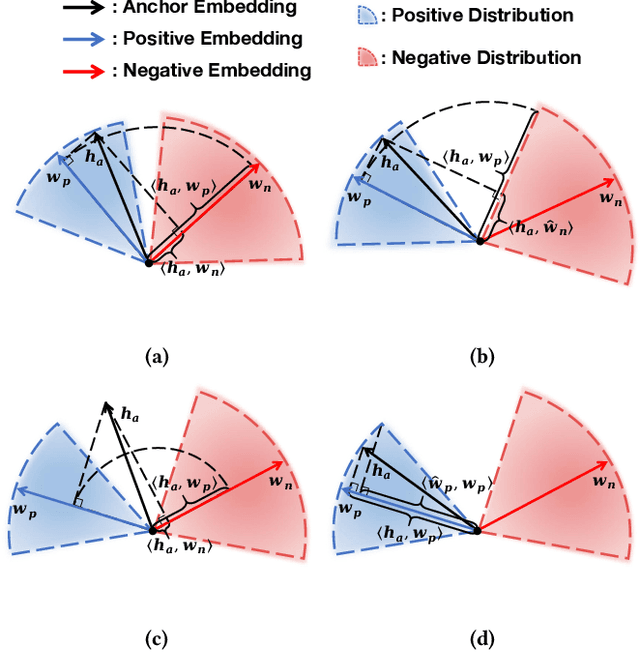
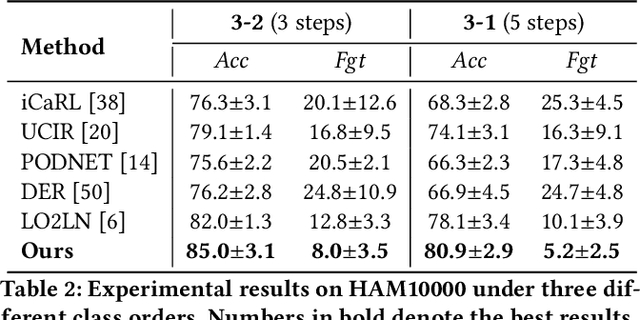
Deep convolutional neural networks have made significant breakthroughs in medical image classification, under the assumption that training samples from all classes are simultaneously available. However, in real-world medical scenarios, there's a common need to continuously learn about new diseases, leading to the emerging field of class incremental learning (CIL) in the medical domain. Typically, CIL suffers from catastrophic forgetting when trained on new classes. This phenomenon is mainly caused by the imbalance between old and new classes, and it becomes even more challenging with imbalanced medical datasets. In this work, we introduce two simple yet effective plug-in methods to mitigate the adverse effects of the imbalance. First, we propose a CIL-balanced classification loss to mitigate the classifier bias toward majority classes via logit adjustment. Second, we propose a distribution margin loss that not only alleviates the inter-class overlap in embedding space but also enforces the intra-class compactness. We evaluate the effectiveness of our method with extensive experiments on three benchmark datasets (CCH5000, HAM10000, and EyePACS). The results demonstrate that our approach outperforms state-of-the-art methods.
Data-Effective Learning: A Comprehensive Medical Benchmark
Jan 31, 2024



Data-effective learning aims to use data in the most impactful way to train AI models, which involves strategies that focus on data quality rather than quantity, ensuring the data used for training has high informational value. Data-effective learning plays a profound role in accelerating AI training, reducing computational costs, and saving data storage, which is very important as the volume of medical data in recent years has grown beyond many people's expectations. However, due to the lack of standards and comprehensive benchmark, research on medical data-effective learning is poorly studied. To address this gap, our paper introduces a comprehensive benchmark specifically for evaluating data-effective learning in the medical field. This benchmark includes a dataset with millions of data samples from 31 medical centers (DataDEL), a baseline method for comparison (MedDEL), and a new evaluation metric (NormDEL) to objectively measure data-effective learning performance. Our extensive experimental results show the baseline MedDEL can achieve performance comparable to the original large dataset with only 5% of the data. Establishing such an open data-effective learning benchmark is crucial for the medical AI research community because it facilitates efficient data use, promotes collaborative breakthroughs, and fosters the development of cost-effective, scalable, and impactful healthcare solutions. The project can be accessed at https://github.com/shadow2469/Data-Effective-Learning-A-Comprehensive-Medical-Benchmark.git.