 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacialFlowNet: Advancing Facial Optical Flow Estimation with a Diverse Dataset and a Decomposed Model
Sep 09, 2024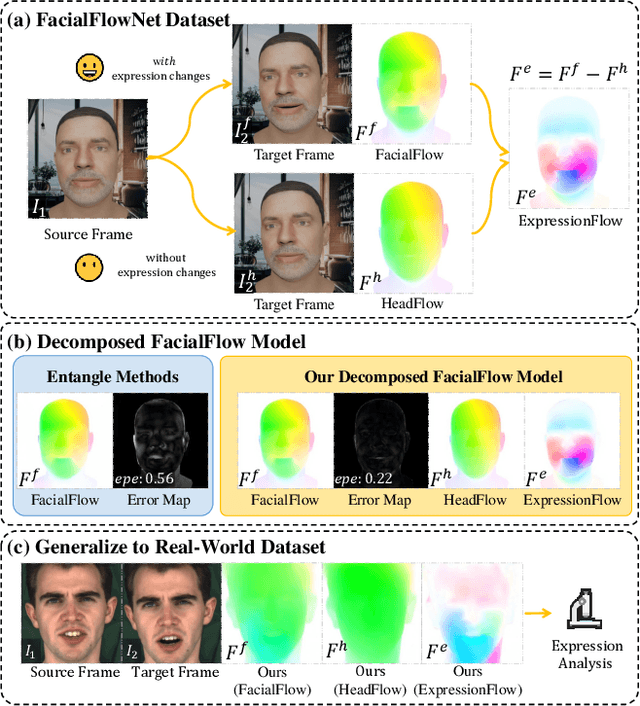


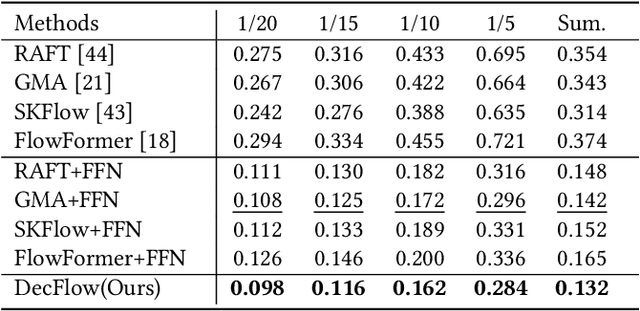
Facial movements play a crucial role in conveying altitude and intentions, and facial optical flow provides a dynamic and detailed representation of it. However, the scarcity of datasets and a modern baseline hinders the progress in facial optical flow research. This paper proposes FacialFlowNet (FFN), a novel large-scale facial optical flow dataset, and the Decomposed Facial Flow Model (DecFlow), the first method capable of decomposing facial flow. FFN comprises 9,635 identities and 105,970 image pairs, offering unprecedented diversity for detailed facial and head motion analysis. DecFlow features a facial semantic-aware encoder and a decomposed flow decoder, excelling in accurately estimating and decomposing facial flow into head and expression components. Comprehensive experiments demonstrate that FFN significantly enhances the accuracy of facial flow estimation across various optical flow methods, achieving up to an 11% reduction in Endpoint Error (EPE) (from 3.91 to 3.48). Moreover, DecFlow, when coupled with FFN, outperforms existing methods in both synthetic and real-world scenarios, enhancing facial expression analysis. The decomposed expression flow achieves a substantial accuracy improvement of 18% (from 69.1% to 82.1%) in micro-expressions recognition. These contributions represent a significant advancement in facial motion analysis and optical flow estimation. Codes and datasets can be found.
Learning to Reconstruct and Understand Indoor Scenes from Sparse Views
Jun 19, 2019
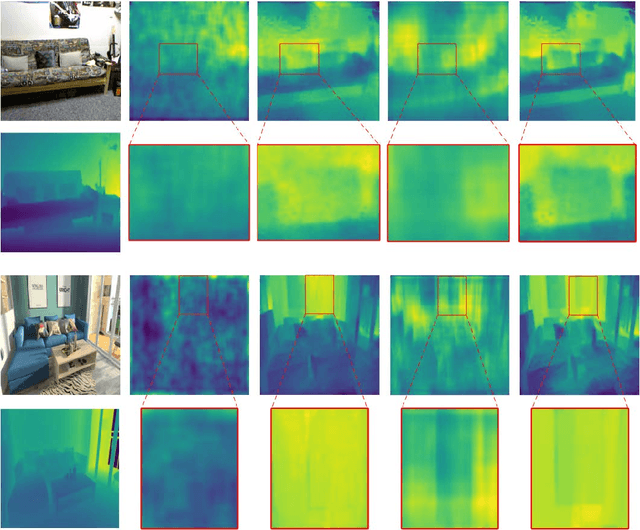
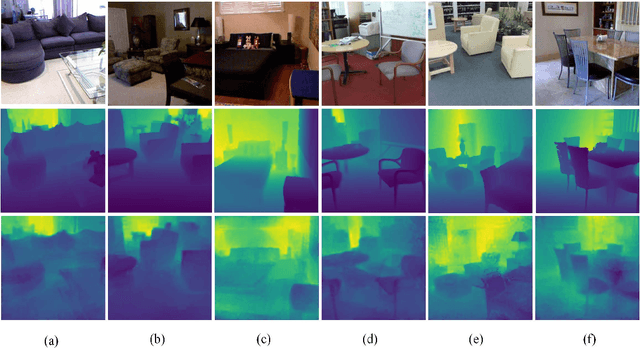

This paper proposes a new method for simultaneous 3D reconstruction and semantic segmentation of indoor scenes. Unlike existing methods that require recording a video using a color camera and/or a depth camera, our method only needs a small number of (e.g., 3-5) color images from uncalibrated sparse views as input, which greatly simplifies data acquisition and extends applicable scenarios. Since different views have limited overlaps, our method allows a single image as input to discern the depth and semantic information of the scene. The key issue is how to recover relatively accurate depth from single images and reconstruct a 3D scene by fusing very few depth maps. To address this problem, we first design an iterative deep architecture, IterNet, that estimates depth and semantic segmentation alternately, so that they benefit each other. To deal with the little overlap and non-rigid transformation between views, we further propose a joint global and local registration method to reconstruct a 3D scene with semantic information from sparse views. We also make available a new indoor synthetic dataset simultaneously providing photorealistic high-resolution RGB images, accurate depth maps and pixel-level semantic labels for thousands of complex layouts, useful for training and evaluation. Experimental results on public datasets and our dataset demonstrate that our method achieves more accurate depth estimation, smaller semantic segmentation errors and better 3D reconstruction results, compared with state-of-the-art methods.