 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Decoupling: Diagnosing the Structural Instability of Latent
Apr 20, 2026Latent Diffusion Models (LDMs) achieve high-fidelity synthesis but suffer from latent space brittleness, causing discontinuous semantic jumps during editing. We introduce a Riemannian framework to diagnose this instability by analyzing the generative Jacobian, decomposing geometry into \textit{Local Scaling} (capacity) and \textit{Local Complexity} (curvature). Our study uncovers a \textbf{``Geometric Decoupling"}: while curvature in normal generation functionally encodes image detail, OOD generation exhibits a functional decoupling where extreme curvature is wasted on unstable semantic boundaries rather than perceptible details. This geometric misallocation identifies ``Geometric Hotspots" as the structural root of instability, providing a robust intrinsic metric for diagnosing generative reliability.
Training-Free Object-Background Compositional T2I via Dynamic Spatial Guidance and Multi-Path Pruning
Apr 10, 2026Existing text-to-image diffusion models, while excelling at subject synthesis, exhibit a persistent foreground bias that treats the background as a passive and under-optimized byproduct. This imbalance compromises global scene coherence and constrains compositional control. To address the limitation, we propose a training-free framework that restructures diffusion sampling to explicitly account for foreground-background interactions. Our approach consists of two key components. First, Dynamic Spatial Guidance introduces a soft, time step dependent gating mechanism that modulates foreground and background attention during the diffusion process, enabling spatially balanced generation. Second, Multi-Path Pruning performs multi-path latent exploration and dynamically filters candidate trajectories using both internal attention statistics and external semantic alignment signals, retaining trajectories that better satisfy object-background constraints. We further develop a benchmark specifically designed to evaluate object-background compositionality. Extensive evaluations across multiple diffusion backbones demonstrate consistent improvements in background coherence and object-background compositional alignment.
OAHuman: Occlusion-Aware 3D Human Reconstruction from Monocular Images
Mar 15, 2026Monocular 3D human reconstruction in real-world scenarios remains highly challenging due to frequent occlusions from surrounding objects, people, or image truncation. Such occlusions lead to missing geometry and unreliable appearance cues, severely degrading the completeness and realism of reconstructed human models. Although recent neural implicit methods achieve impressive results on clean inputs, they struggle under occlusion due to entangled modeling of shape and texture. In this paper, we propose OAHuman, an occlusion-aware framework that explicitly decouples geometry reconstruction and texture synthesis for robust 3D human modeling from a single RGB image. The core innovation lies in the decoupling-perception paradigm, which addresses the fundamental issue of geometry-texture cross-contamination in occluded regions. Our framework ensures that geometry reconstruction is perceptually reinforced even in occluded areas, isolating it from texture interference. In parallel, texture synthesis is learned exclusively from visible regions, preventing texture errors from being transferred to the occluded areas. This decoupling approach enables OAHuman to achieve robust and high-fidelity reconstruction under occlusion, which has been a long-standing challenge in the field. Extensive experiments on occlusion-rich benchmarks demonstrate that OAHuman achieves superior performance in terms of structural completeness, surface detail, and texture realism, significantly improving monocular 3D human reconstruction under occlusion conditions.
IM-Animation: An Implicit Motion Representation for Identity-decoupled Character Animation
Feb 07, 2026Recent progress in video diffusion models has markedly advanced character animation, which synthesizes motioned videos by animating a static identity image according to a driving video. Explicit methods represent motion using skeleton, DWPose or other explicit structured signals, but struggle to handle spatial mismatches and varying body scales. %proportions. Implicit methods, on the other hand, capture high-level implicit motion semantics directly from the driving video, but suffer from identity leakage and entanglement between motion and appearance. To address the above challenges, we propose a novel implicit motion representation that compresses per-frame motion into compact 1D motion tokens. This design relaxes strict spatial constraints inherent in 2D representations and effectively prevents identity information leakage from the motion video. Furthermore, we design a temporally consistent mask token-based retargeting module that enforces a temporal training bottleneck, mitigating interference from the source images' motion and improving retargeting consistency. Our methodology employs a three-stage training strategy to enhance the training efficiency and ensure high fidelity. Extensive experiments demonstrate that our implicit motion representation and the propose IM-Animation's generative capabilities are achieve superior or competitive performance compared with state-of-the-art methods.
Differentiable Skill Optimisation for Powder Manipulation in Laboratory Automation
Oct 01, 2025Robotic automation is accelerating scientific discovery by reducing manual effort in laboratory workflows. However, precise manipulation of powders remains challenging, particularly in tasks such as transport that demand accuracy and stability. We propose a trajectory optimisation framework for powder transport in laboratory settings, which integrates differentiable physics simulation for accurate modelling of granular dynamics, low-dimensional skill-space parameterisation to reduce optimisation complexity, and a curriculum-based strategy that progressively refines task competence over long horizons. This formulation enables end-to-end optimisation of contact-rich robot trajectories while maintaining stability and convergence efficiency. Experimental results demonstrate that the proposed method achieves superior task success rates and stability compared to the reinforcement learning baseline.
DyCrowd: Towards Dynamic Crowd Reconstruction from a Large-scene Video
Aug 18, 20253D reconstruction of dynamic crowds in large scenes has become increasingly important for applications such as city surveillance and crowd analysis. However, current works attempt to reconstruct 3D crowds from a static image, causing a lack of temporal consistency and inability to alleviate the typical impact caused by occlusions. In this paper, we propose DyCrowd, the first framework for spatio-temporally consistent 3D reconstruction of hundreds of individuals' poses, positions and shapes from a large-scene video. We design a coarse-to-fine group-guided motion optimization strategy for occlusion-robust crowd reconstruction in large scenes. To address temporal instability and severe occlusions, we further incorporate a VAE (Variational Autoencoder)-based human motion prior along with a segment-level group-guided optimization. The core of our strategy leverages collective crowd behavior to address long-term dynamic occlusions. By jointly optimizing the motion sequences of individuals with similar motion segments and combining this with the proposed Asynchronous Motion Consistency (AMC) loss, we enable high-quality unoccluded motion segments to guide the motion recovery of occluded ones, ensuring robust and plausible motion recovery even in the presence of temporal desynchronization and rhythmic inconsistencies. Additionally, in order to fill the gap of no existing well-annotated large-scene video dataset, we contribute a virtual benchmark dataset, VirtualCrowd, for evaluating dynamic crowd reconstruction from large-scene videos. Experimental results demonstrate that the proposed method achieves state-of-the-art performance in the large-scene dynamic crowd reconstruction task. The code and dataset will be available for research purposes.
RESCUE: Crowd Evacuation Simulation via Controlling SDM-United Characters
Jul 27, 2025



Crowd evacuation simulation is critical for enhancing public safety, and demanded for realistic virtual environments. Current mainstream evacuation models overlook the complex human behaviors that occur during evacuation, such as pedestrian collisions, interpersonal interactions, and variations in behavior influenced by terrain types or individual body shapes. This results in the failure to accurately simulate the escape of people in the real world. In this paper, aligned with the sensory-decision-motor (SDM) flow of the human brain, we propose a real-time 3D crowd evacuation simulation framework that integrates a 3D-adaptive SFM (Social Force Model) Decision Mechanism and a Personalized Gait Control Motor. This framework allows multiple agents to move in parallel and is suitable for various scenarios, with dynamic crowd awareness. Additionally, we introduce Part-level Force Visualization to assist in evacuation analysis. Experimental results demonstrate that our framework supports dynamic trajectory planning and personalized behavior for each agent throughout the evacuation process, and is compatible with uneven terrain. Visually, our method generates evacuation results that are more realistic and plausible, providing enhanced insights for crowd simulation. The code is available at http://cic.tju.edu.cn/faculty/likun/projects/RESCUE.
Canonical Pose Reconstruction from Single Depth Image for 3D Non-rigid Pose Recovery on Limited Datasets
May 23, 2025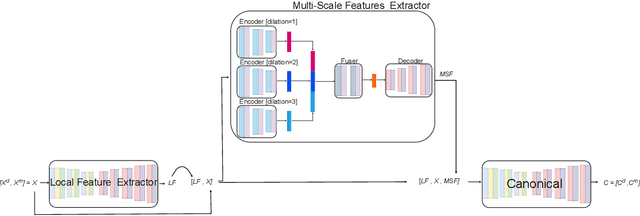
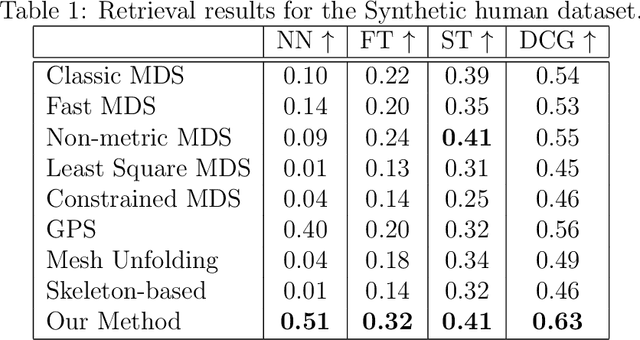
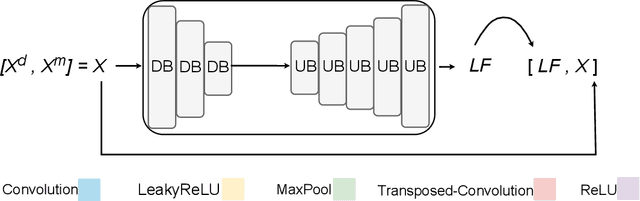

3D reconstruction from 2D inputs, especially for non-rigid objects like humans, presents unique challenges due to the significant range of possible deformations. Traditional methods often struggle with non-rigid shapes, which require extensive training data to cover the entire deformation space. This study addresses these limitations by proposing a canonical pose reconstruction model that transforms single-view depth images of deformable shapes into a canonical form. This alignment facilitates shape reconstruction by enabling the application of rigid object reconstruction techniques, and supports recovering the input pose in voxel representation as part of the reconstruction task, utilizing both the original and deformed depth images. Notably, our model achieves effective results with only a small dataset of approximately 300 samples. Experimental results on animal and human datasets demonstrate that our model outperforms other state-of-the-art methods.
NeRF-Texture: Synthesizing Neural Radiance Field Textures
Dec 13, 2024



Texture synthesis is a fundamental problem in computer graphics that would benefit various applications. Existing methods are effective in handling 2D image textures. In contrast, many real-world textures contain meso-structure in the 3D geometry space, such as grass, leaves, and fabrics, which cannot be effectively modeled using only 2D image textures. We propose a novel texture synthesis method with Neural Radiance Fields (NeRF) to capture and synthesize textures from given multi-view images. In the proposed NeRF texture representation, a scene with fine geometric details is disentangled into the meso-structure textures and the underlying base shape. This allows textures with meso-structure to be effectively learned as latent features situated on the base shape, which are fed into a NeRF decoder trained simultaneously to represent the rich view-dependent appearance. Using this implicit representation, we can synthesize NeRF-based textures through patch matching of latent features. However, inconsistencies between the metrics of the reconstructed content space and the latent feature space may compromise the synthesis quality. To enhance matching performance, we further regularize the distribution of latent features by incorporating a clustering constraint. In addition to generating NeRF textures over a planar domain, our method can also synthesize NeRF textures over curved surfaces, which are practically useful. Experimental results and evaluations demonstrate the effectiveness of our approach.
FOF-X: Towards Real-time Detailed Human Reconstruction from a Single Image
Dec 08, 2024We introduce FOF-X for real-time reconstruction of detailed human geometry from a single image. Balancing real-time speed against high-quality results is a persistent challenge, mainly due to the high computational demands of existing 3D representations. To address this, we propose Fourier Occupancy Field (FOF), an efficient 3D representation by learning the Fourier series. The core of FOF is to factorize a 3D occupancy field into a 2D vector field, retaining topology and spatial relationships within the 3D domain while facilitating compatibility with 2D convolutional neural networks. Such a representation bridges the gap between 3D and 2D domains, enabling the integration of human parametric models as priors and enhancing the reconstruction robustness. Based on FOF, we design a new reconstruction framework, FOF-X, to avoid the performance degradation caused by texture and lighting. This enables our real-time reconstruction system to better handle the domain gap between training images and real images. Additionally, in FOF-X, we enhance the inter-conversion algorithms between FOF and mesh representations with a Laplacian constraint and an automaton-based discontinuity matcher, improving both quality and robustness. We validate the strengths of our approach on different datasets and real-captured data, where FOF-X achieves new state-of-the-art results. The code will be released for research purposes.