 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Skill Optimisation for Powder Manipulation in Laboratory Automation
Oct 01, 2025Robotic automation is accelerating scientific discovery by reducing manual effort in laboratory workflows. However, precise manipulation of powders remains challenging, particularly in tasks such as transport that demand accuracy and stability. We propose a trajectory optimisation framework for powder transport in laboratory settings, which integrates differentiable physics simulation for accurate modelling of granular dynamics, low-dimensional skill-space parameterisation to reduce optimisation complexity, and a curriculum-based strategy that progressively refines task competence over long horizons. This formulation enables end-to-end optimisation of contact-rich robot trajectories while maintaining stability and convergence efficiency. Experimental results demonstrate that the proposed method achieves superior task success rates and stability compared to the reinforcement learning baseline.
Differentiable Physics-based System Identification for Robotic Manipulation of Elastoplastic Materials
Nov 01, 2024



Robotic manipulation of volumetric elastoplastic deformable materials, from foods such as dough to construction materials like clay, is in its infancy, largely due to the difficulty of modelling and perception in a high-dimensional space. Simulating the dynamics of such materials is computationally expensive. It tends to suffer from inaccurately estimated physics parameters of the materials and the environment, impeding high-precision manipulation. Estimating such parameters from raw point clouds captured by optical cameras suffers further from heavy occlusions. To address this challenge, this work introduces a novel Differentiable Physics-based System Identification (DPSI) framework that enables a robot arm to infer the physics parameters of elastoplastic materials and the environment using simple manipulation motions and incomplete 3D point clouds, aligning the simulation with the real world. Extensive experiments show that with only a single real-world interaction, the estimated parameters, Young's modulus, Poisson's ratio, yield stress and friction coefficients, can accurately simulate visually and physically realistic deformation behaviours induced by unseen and long-horizon manipulation motions. Additionally, the DPSI framework inherently provides physically intuitive interpretations for the parameters in contrast to black-box approaches such as deep neural networks.
Fusion of Short-term and Long-term Attention for Video Mirror Detection
Jul 10, 2024



Techniques for detecting mirrors from static images have witnessed rapid growth in recent years. However, these methods detect mirrors from single input images. Detecting mirrors from video requires further consideration of temporal consistency between frames. We observe that humans can recognize mirror candidates, from just one or two frames, based on their appearance (e.g. shape, color). However, to ensure that the candidate is indeed a mirror (not a picture or a window), we often need to observe more frames for a global view. This observation motivates us to detect mirrors by fusing appearance features extracted from a short-term attention module and context information extracted from a long-term attention module. To evaluate the performance, we build a challenging benchmark dataset of 19,255 frames from 281 videos. Experimental results demonstrate that our method achieves state-of-the-art performance on the benchmark dataset.
AutomaChef: A Physics-informed Demonstration-guided Learning Framework for Granular Material Manipulation
Jun 13, 2024Due to the complex physical properties of granular materials, research on robot learning for manipulating such materials predominantly either disregards the consideration of their physical characteristics or uses surrogate models to approximate their physical properties. Learning to manipulate granular materials based on physical information obtained through precise modelling remains an unsolved problem. In this paper, we propose to address this challenge by constructing a differentiable physics simulator for granular materials based on the Taichi programming language and developing a learning framework accelerated by imperfect demonstrations that are generated via gradient-based optimisation on non-granular materials through our simulator. Experimental results show that our method trains three policies that, when chained, are capable of executing the task of transporting granular materials in both simulated and real-world scenarios, which existing popular deep reinforcement learning models fail to accomplish.
Learning to bag with a simulation-free reinforcement learning framework for robots
Oct 22, 2023Bagging is an essential skill that humans perform in their daily activities. However, deformable objects, such as bags, are complex for robots to manipulate. This paper presents an efficient learning-based framework that enables robots to learn bagging. The novelty of this framework is its ability to perform bagging without relying on simulations. The learning process is accomplished through a reinforcement learning algorithm introduced in this work, designed to find the best grasping points of the bag based on a set of compact state representations. The framework utilizes a set of primitive actions and represents the task in five states. In our experiments, the framework reaches a 60 % and 80 % of success rate after around three hours of training in the real world when starting the bagging task from folded and unfolded, respectively. Finally, we test the trained model with two more bags of different sizes to evaluate its generalizability.
Deep Reinforcement Learning with Explicit Context Representation
Oct 15, 2023Reinforcement learning (RL) has shown an outstanding capability for solving complex computational problems. However, most RL algorithms lack an explicit method that would allow learning from contextual information. Humans use context to identify patterns and relations among elements in the environment, along with how to avoid making wrong actions. On the other hand, what may seem like an obviously wrong decision from a human perspective could take hundreds of steps for an RL agent to learn to avoid. This paper proposes a framework for discrete environments called Iota explicit context representation (IECR). The framework involves representing each state using contextual key frames (CKFs), which can then be used to extract a function that represents the affordances of the state; in addition, two loss functions are introduced with respect to the affordances of the state. The novelty of the IECR framework lies in its capacity to extract contextual information from the environment and learn from the CKFs' representation. We validate the framework by developing four new algorithms that learn using context: Iota deep Q-network (IDQN), Iota double deep Q-network (IDDQN), Iota dueling deep Q-network (IDuDQN), and Iota dueling double deep Q-network (IDDDQN). Furthermore, we evaluate the framework and the new algorithms in five discrete environments. We show that all the algorithms, which use contextual information, converge in around 40,000 training steps of the neural networks, significantly outperforming their state-of-the-art equivalents.
Rethink Baseline of Integrated Gradients from the Perspective of Shapley Value
Oct 10, 2023Numerous approaches have attempted to interpret deep neural networks (DNNs) by attributing the prediction of DNN to its input features. One of the well-studied attribution methods is Integrated Gradients (IG). Specifically, the choice of baselines for IG is a critical consideration for generating meaningful and unbiased explanations for model predictions in different scenarios. However, current practice of exploiting a single baseline fails to fulfill this ambition, thus demanding multiple baselines. Fortunately, the inherent connection between IG and Aumann-Shapley Value forms a unique perspective to rethink the design of baselines. Under certain hypothesis, we theoretically analyse that a set of baseline aligns with the coalitions in Shapley Value. Thus, we propose a novel baseline construction method called Shapley Integrated Gradients (SIG) that searches for a set of baselines by proportional sampling to partly simulate the computation path of Shapley Value. Simulations on GridWorld show that SIG approximates the proportion of Shapley Values. Furthermore, experiments conducted on various image tasks demonstrate that compared to IG using other baseline methods, SIG exhibits an improved estimation of feature's contribution, offers more consistent explanations across diverse applications, and is generic to distinct data types or instances with insignificant computational overhead.
CasIL: Cognizing and Imitating Skills via a Dual Cognition-Action Architecture
Sep 28, 2023Enabling robots to effectively imitate expert skills in longhorizon tasks such as locomotion, manipulation, and more, poses a long-standing challenge. Existing imitation learning (IL) approaches for robots still grapple with sub-optimal performance in complex tasks. In this paper, we consider how this challenge can be addressed within the human cognitive priors. Heuristically, we extend the usual notion of action to a dual Cognition (high-level)-Action (low-level) architecture by introducing intuitive human cognitive priors, and propose a novel skill IL framework through human-robot interaction, called Cognition-Action-based Skill Imitation Learning (CasIL), for the robotic agent to effectively cognize and imitate the critical skills from raw visual demonstrations. CasIL enables both cognition and action imitation, while high-level skill cognition explicitly guides low-level primitive actions, providing robustness and reliability to the entire skill IL process. We evaluated our method on MuJoCo and RLBench benchmarks, as well as on the obstacle avoidance and point-goal navigation tasks for quadrupedal robot locomotion. Experimental results show that our CasIL consistently achieves competitive and robust skill imitation capability compared to other counterparts in a variety of long-horizon robotic tasks.
Recent Advances of Deep Robotic Affordance Learning: A Reinforcement Learning Perspective
Mar 10, 2023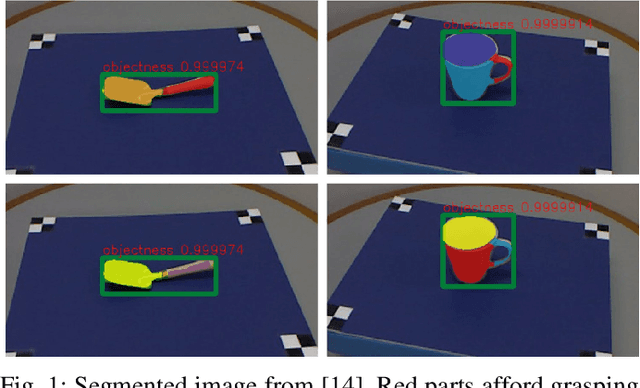
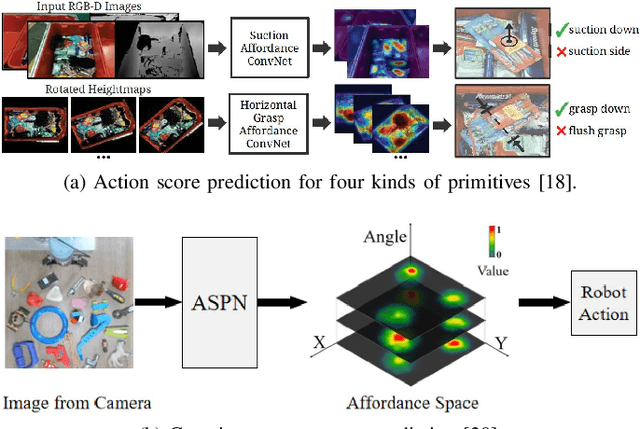
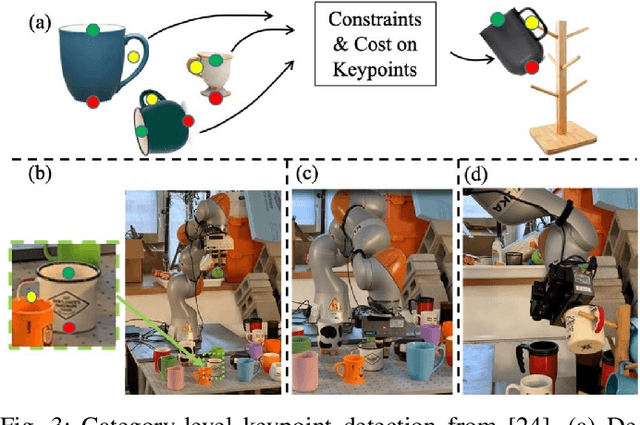
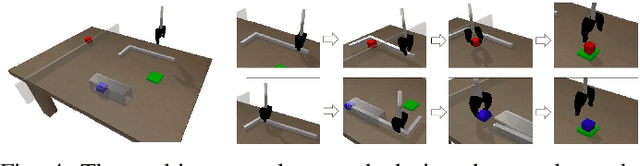
As a popular concept proposed in the field of psychology, affordance has been regarded as one of the important abilities that enable humans to understand and interact with the environment. Briefly, it captures the possibilities and effects of the actions of an agent applied to a specific object or, more generally, a part of the environment. This paper provides a short review of the recent developments of deep robotic affordance learning (DRAL), which aims to develop data-driven methods that use the concept of affordance to aid in robotic tasks. We first classify these papers from a reinforcement learning (RL) perspective, and draw connections between RL and affordances. The technical details of each category are discussed and their limitations identified. We further summarise them and identify future challenges from the aspects of observations, actions, affordance representation, data-collection and real-world deployment. A final remark is given at the end to propose a promising future direction of the RL-based affordance definition to include the predictions of arbitrary action consequences.
Abstract Demonstrations and Adaptive Exploration for Efficient and Stable Multi-step Sparse Reward Reinforcement Learning
Jul 19, 2022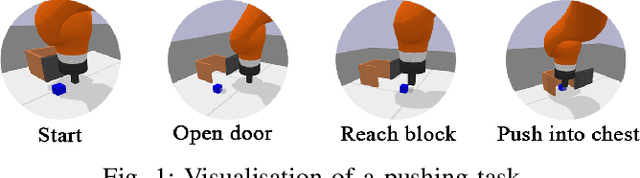
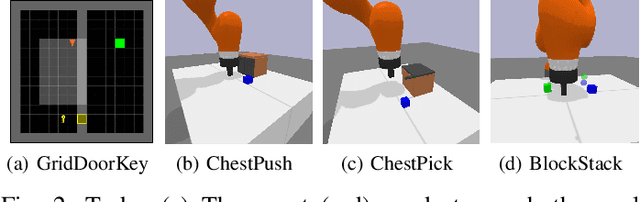
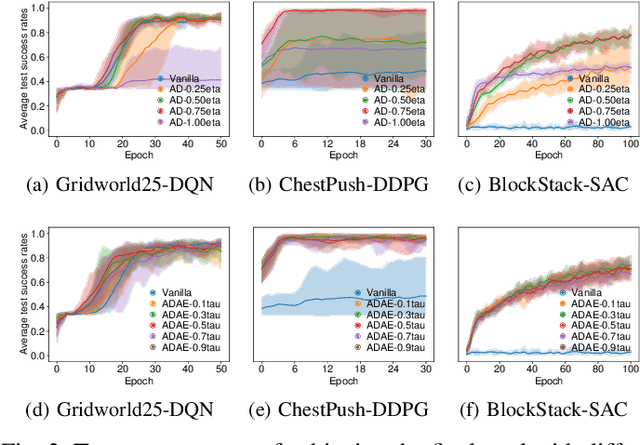
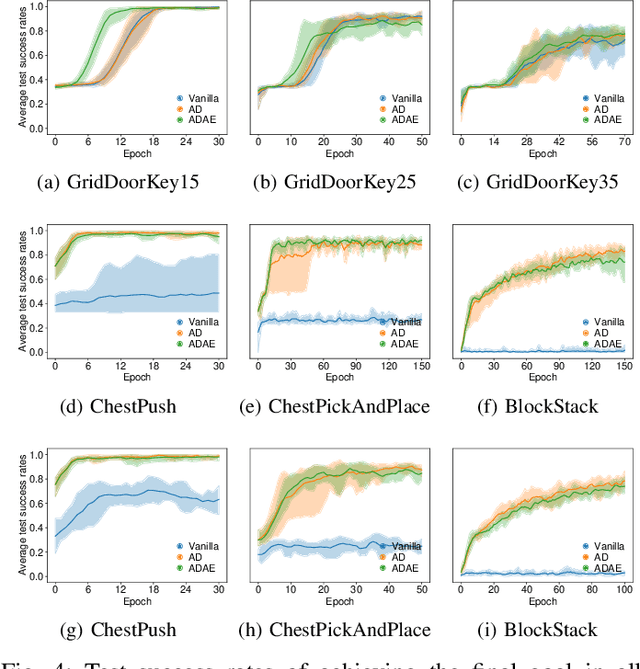
Although Deep Reinforcement Learning (DRL) has been popular in many disciplines including robotics, state-of-the-art DRL algorithms still struggle to learn long-horizon, multi-step and sparse reward tasks, such as stacking several blocks given only a task-completion reward signal. To improve learning efficiency for such tasks, this paper proposes a DRL exploration technique, termed A^2, which integrates two components inspired by human experiences: Abstract demonstrations and Adaptive exploration. A^2 starts by decomposing a complex task into subtasks, and then provides the correct orders of subtasks to learn. During training, the agent explores the environment adaptively, acting more deterministically for well-mastered subtasks and more stochastically for ill-learnt subtasks. Ablation and comparative experiments are conducted on several grid-world tasks and three robotic manipulation tasks. We demonstrate that A^2 can aid popular DRL algorithms (DQN, DDPG, and SAC) to learn more efficiently and stably in these environments.