 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoWebWorld: Synthesizing Infinite Verifiable Web Environments via Finite State Machines
Feb 15, 2026The performance of autonomous Web GUI agents heavily relies on the quality and quantity of their training data. However, a fundamental bottleneck persists: collecting interaction trajectories from real-world websites is expensive and difficult to verify. The underlying state transitions are hidden, leading to reliance on inconsistent and costly external verifiers to evaluate step-level correctness. To address this, we propose AutoWebWorld, a novel framework for synthesizing controllable and verifiable web environments by modeling them as Finite State Machines (FSMs) and use coding agents to translate FSMs into interactive websites. Unlike real websites, where state transitions are implicit, AutoWebWorld explicitly defines all states, actions, and transition rules. This enables programmatic verification: action correctness is checked against predefined rules, and task success is confirmed by reaching a goal state in the FSM graph. AutoWebWorld enables a fully automated search-and-verify pipeline, generating over 11,663 verified trajectories from 29 diverse web environments at only $0.04 per trajectory. Training on this synthetic data significantly boosts real-world performance. Our 7B Web GUI agent outperforms all baselines within 15 steps on WebVoyager. Furthermore, we observe a clear scaling law: as the synthetic data volume increases, performance on WebVoyager and Online-Mind2Web consistently improves.
ChartMark: A Structured Grammar for Chart Annotation
Jul 29, 2025Chart annotations enhance visualization accessibility but suffer from fragmented, non-standardized representations that limit cross-platform reuse. We propose ChartMark, a structured grammar that separates annotation semantics from visualization implementations. ChartMark features a hierarchical framework mapping onto annotation dimensions (e.g., task, chart context), supporting both abstract intents and precise visual details. Our toolkit demonstrates converting ChartMark specifications into Vega-Lite visualizations, highlighting its flexibility, expressiveness, and practical applicability.
CA-Jaccard: Camera-aware Jaccard Distance for Person Re-identification
Nov 17, 2023



Person re-identification (re-ID) is a challenging task that aims to learn discriminative features for person retrieval. In person re-ID, Jaccard distance is a widely used distance metric, especially in re-ranking and clustering scenarios. However, we discover that camera variation has a significant negative impact on the reliability of Jaccard distance. In particular, Jaccard distance calculates the distance based on the overlap of relevant neighbors. Due to camera variation, intra-camera samples dominate the relevant neighbors, which reduces the reliability of the neighbors by introducing intra-camera negative samples and excluding inter-camera positive samples. To overcome this problem, we propose a novel camera-aware Jaccard (CA-Jaccard) distance that leverages camera information to enhance the reliability of Jaccard distance. Specifically, we introduce camera-aware k-reciprocal nearest neighbors (CKRNNs) to find k-reciprocal nearest neighbors on the intra-camera and inter-camera ranking lists, which improves the reliability of relevant neighbors and guarantees the contribution of inter-camera samples in the overlap. Moreover, we propose a camera-aware local query expansion (CLQE) to exploit camera variation as a strong constraint to mine reliable samples in relevant neighbors and assign these samples higher weights in overlap to further improve the reliability. Our CA-Jaccard distance is simple yet effective and can serve as a general distance metric for person re-ID methods with high reliability and low computational cost. Extensive experiments demonstrate the effectiveness of our method.
Learning Agile Locomotion and Adaptive Behaviors via RL-augmented MPC
Oct 13, 2023



In the context of legged robots, adaptive behavior involves adaptive balancing and adaptive swing foot reflection. While adaptive balancing counteracts perturbations to the robot, adaptive swing foot reflection helps the robot to navigate intricate terrains without foot entrapment. In this paper, we manage to bring both aspects of adaptive behavior to quadruped locomotion by combining RL and MPC while improving the robustness and agility of blind legged locomotion. This integration leverages MPC's strength in predictive capabilities and RL's adeptness in drawing from past experiences. Unlike traditional locomotion controls that separate stance foot control and swing foot trajectory, our innovative approach unifies them, addressing their lack of synchronization. At the heart of our contribution is the synthesis of stance foot control with swing foot reflection, improving agility and robustness in locomotion with adaptive behavior. A hallmark of our approach is robust blind stair climbing through swing foot reflection. Moreover, we intentionally designed the learning module as a general plugin for different robot platforms. We trained the policy and implemented our approach on the Unitree A1 robot, achieving impressive results: a peak turn rate of 8.5 rad/s, a peak running speed of 3 m/s, and steering at a speed of 2.5 m/s. Remarkably, this framework also allows the robot to maintain stable locomotion while bearing an unexpected load of 10 kg, or 83\% of its body mass. We further demonstrate the generalizability and robustness of the same policy where it realizes zero-shot transfer to different robot platforms like Go1 and AlienGo robots for load carrying. Code is made available for the use of the research community at https://github.com/DRCL-USC/RL_augmented_MPC.git
Generalized Animal Imitator: Agile Locomotion with Versatile Motion Prior
Oct 02, 2023The agility of animals, particularly in complex activities such as running, turning, jumping, and backflipping, stands as an exemplar for robotic system design. Transferring this suite of behaviors to legged robotic systems introduces essential inquiries: How can a robot be trained to learn multiple locomotion behaviors simultaneously? How can the robot execute these tasks with a smooth transition? And what strategies allow for the integrated application of these skills? This paper introduces the Versatile Instructable Motion prior (VIM) - a Reinforcement Learning framework designed to incorporate a range of agile locomotion tasks suitable for advanced robotic applications. Our framework enables legged robots to learn diverse agile low-level skills by imitating animal motions and manually designed motions with Functionality reward and Stylization reward. While the Functionality reward guides the robot's ability to adopt varied skills, the Stylization reward ensures performance alignment with reference motions. Our evaluations of the VIM framework span both simulation environments and real-world deployment. To our understanding, this is the first work that allows a robot to concurrently learn diverse agile locomotion tasks using a singular controller. Further details and supportive media can be found at our project site: https://rchalyang.github.io/VIM .
CasIL: Cognizing and Imitating Skills via a Dual Cognition-Action Architecture
Sep 28, 2023Enabling robots to effectively imitate expert skills in longhorizon tasks such as locomotion, manipulation, and more, poses a long-standing challenge. Existing imitation learning (IL) approaches for robots still grapple with sub-optimal performance in complex tasks. In this paper, we consider how this challenge can be addressed within the human cognitive priors. Heuristically, we extend the usual notion of action to a dual Cognition (high-level)-Action (low-level) architecture by introducing intuitive human cognitive priors, and propose a novel skill IL framework through human-robot interaction, called Cognition-Action-based Skill Imitation Learning (CasIL), for the robotic agent to effectively cognize and imitate the critical skills from raw visual demonstrations. CasIL enables both cognition and action imitation, while high-level skill cognition explicitly guides low-level primitive actions, providing robustness and reliability to the entire skill IL process. We evaluated our method on MuJoCo and RLBench benchmarks, as well as on the obstacle avoidance and point-goal navigation tasks for quadrupedal robot locomotion. Experimental results show that our CasIL consistently achieves competitive and robust skill imitation capability compared to other counterparts in a variety of long-horizon robotic tasks.
Hamilton-Jacobi Reachability Analysis for Hybrid Systems with Controlled and Forced Transitions
Sep 19, 2023Hybrid dynamical systems with non-linear dynamics are one of the most general modeling tools for representing robotic systems, especially contact-rich systems. However, providing guarantees regarding the safety or performance of such hybrid systems can still prove to be a challenging problem because it requires simultaneous reasoning about continuous state evolution and discrete mode switching. In this work, we address this problem by extending classical Hamilton-Jacobi (HJ) reachability analysis, a formal verification method for continuous non-linear dynamics in the presence of bounded inputs and disturbances, to hybrid dynamical systems. Our framework can compute reachable sets for hybrid systems consisting of multiple discrete modes, each with its own set of non-linear continuous dynamics, discrete transitions that can be directly commanded or forced by a discrete control input, while still accounting for control bounds and adversarial disturbances in the state evolution. Along with the reachable set, the proposed framework also provides an optimal continuous and discrete controller to ensure system safety. We demonstrate our framework in simulation on an aircraft collision avoidance problem, as well as on a real-world testbed to solve the optimal mode planning problem for a quadruped with multiple gaits.
Contact Optimization for Non-Prehensile Loco-Manipulation via Hierarchical Model Predictive Control
Oct 07, 2022
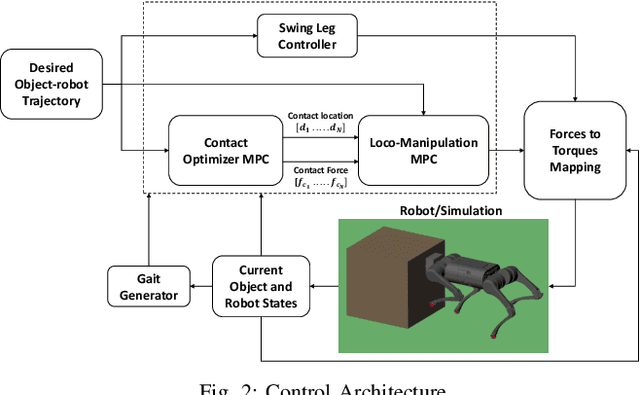
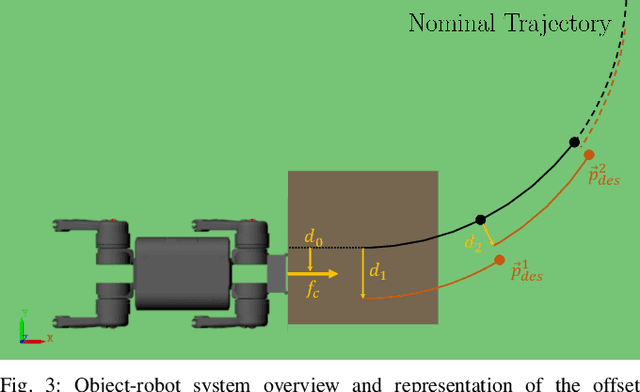
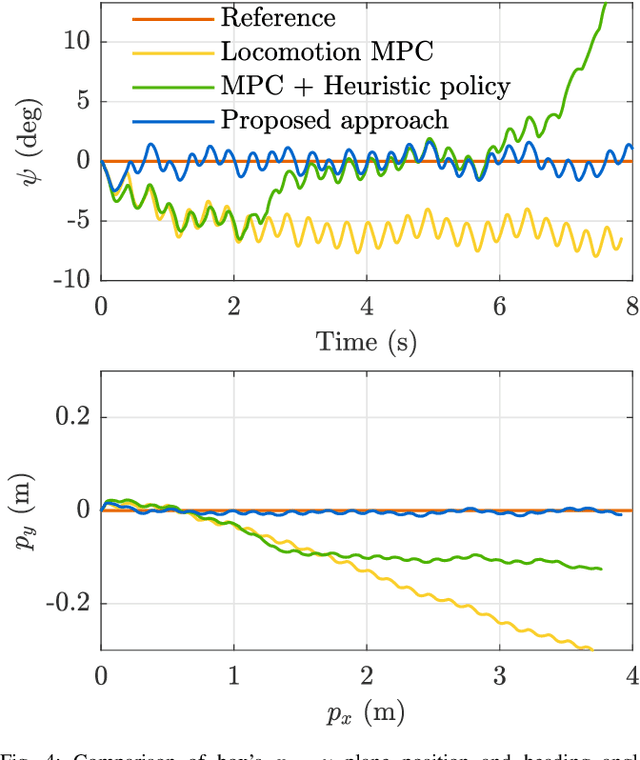
Recent studies on quadruped robots have focused on either locomotion or mobile manipulation using a robotic arm. Legged robots can manipulate heavier and larger objects using non-prehensile manipulation primitives, such as planar pushing, to drive the object to the desired location. In this paper, we present a novel hierarchical model predictive control (MPC) for contact optimization of the manipulation task. Using two cascading MPCs, we split the loco-manipulation problem into two parts: the first to optimize both contact force and contact location between the robot and the object, and the second to regulate the desired interaction force through the robot locomotion. Our method is successfully validated in both simulation and hardware experiments. While the baseline locomotion MPC fails to follow the desired trajectory of the object, our proposed approach can effectively control both object's position and orientation with minimal tracking error. This capability also allows us to perform obstacle avoidance for both the robot and the object during the loco-manipulation task.
Adaptive Force-based Control for Legged Robots
Nov 12, 2020
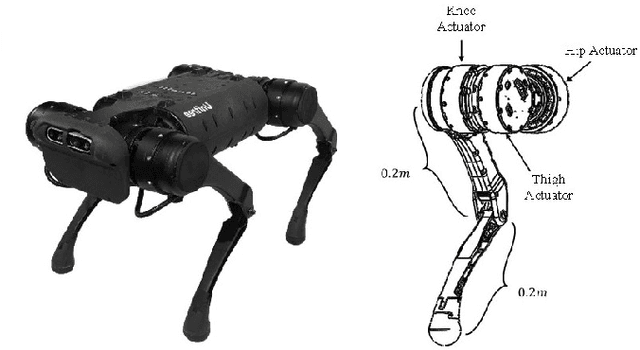
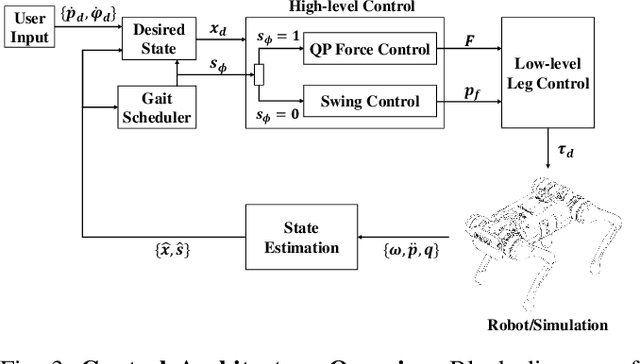
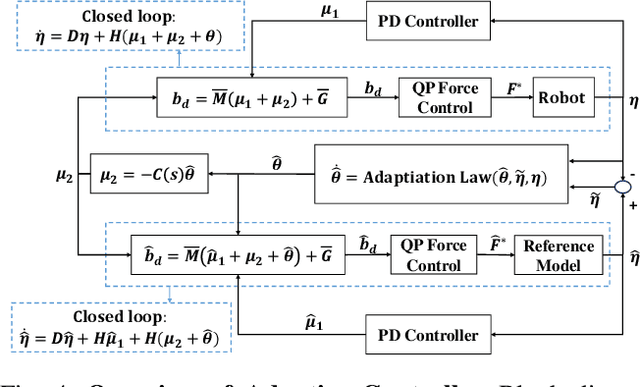
In this paper, we present a novel methodology to introduce adaptive control for force-based control systems, with application to legged robots. In our approach, the reference model is based on the quadratic program force control. We evaluate our proposed control design on a high-fidelity physical simulation of LASER, a dynamic quadruped robot. Our proposed method guarantees input-to-state stability and is successfully validated for the problem of quadruped robots walking on rough terrain while carrying unknown and time-varying loads.