 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirRoom: Objects Matter in Room Reidentification
Mar 03, 2025



Room reidentification (ReID) is a challenging yet essential task with numerous applications in fields such as augmented reality (AR) and homecare robotics. Existing visual place recognition (VPR) methods, which typically rely on global descriptors or aggregate local features, often struggle in cluttered indoor environments densely populated with man-made objects. These methods tend to overlook the crucial role of object-oriented information. To address this, we propose AirRoom, an object-aware pipeline that integrates multi-level object-oriented information-from global context to object patches, object segmentation, and keypoints-utilizing a coarse-to-fine retrieval approach. Extensive experiments on four newly constructed datasets-MPReID, HMReID, GibsonReID, and ReplicaReID-demonstrate that AirRoom outperforms state-of-the-art (SOTA) models across nearly all evaluation metrics, with improvements ranging from 6% to 80%. Moreover, AirRoom exhibits significant flexibility, allowing various modules within the pipeline to be substituted with different alternatives without compromising overall performance. It also shows robust and consistent performance under diverse viewpoint variations.
Responsive Noise-Relaying Diffusion Policy: Responsive and Efficient Visuomotor Control
Feb 18, 2025



Imitation learning is an efficient method for teaching robots a variety of tasks. Diffusion Policy, which uses a conditional denoising diffusion process to generate actions, has demonstrated superior performance, particularly in learning from multi-modal demonstrates. However, it relies on executing multiple actions to retain performance and prevent mode bouncing, which limits its responsiveness, as actions are not conditioned on the most recent observations. To address this, we introduce Responsive Noise-Relaying Diffusion Policy (RNR-DP), which maintains a noise-relaying buffer with progressively increasing noise levels and employs a sequential denoising mechanism that generates immediate, noise-free actions at the head of the sequence, while appending noisy actions at the tail. This ensures that actions are responsive and conditioned on the latest observations, while maintaining motion consistency through the noise-relaying buffer. This design enables the handling of tasks requiring responsive control, and accelerates action generation by reusing denoising steps. Experiments on response-sensitive tasks demonstrate that, compared to Diffusion Policy, ours achieves 18% improvement in success rate. Further evaluation on regular tasks demonstrates that RNR-DP also exceeds the best acceleration method by 6.9%, highlighting its computational efficiency advantage in scenarios where responsiveness is less critical.
VL-Nav: Real-time Vision-Language Navigation with Spatial Reasoning
Feb 02, 2025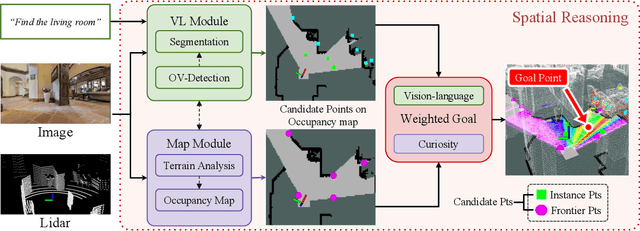



Vision-language navigation in unknown environments is crucial for mobile robots. In scenarios such as household assistance and rescue, mobile robots need to understand a human command, such as "find a person wearing black". We present a novel vision-language navigation (VL-Nav) system that integrates efficient spatial reasoning on low-power robots. Unlike prior methods that rely on a single image-level feature similarity to guide a robot, we introduce the heuristic-vision-language (HVL) spatial reasoning for goal point selection. It combines pixel-wise vision-language features and heuristic exploration to enable efficient navigation to human-instructed instances in various environments robustly. We deploy VL-Nav on a four-wheel mobile robot and conduct comprehensive navigation tasks in various environments of different scales and semantic complexities, indoors and outdoors. Remarkably, VL-Nav operates at a real-time frequency of 30 Hz with a Jetson Orin NX, highlighting its ability to conduct efficient vision-language navigation. Experimental results show that VL-Nav achieves an overall success rate of 86.3%, outperforming previous methods by 44.15%.
iKap: Kinematics-aware Planning with Imperative Learning
Dec 12, 2024
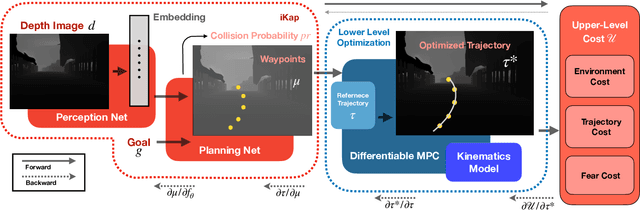


Trajectory planning in robotics aims to generate collision-free pose sequences that can be reliably executed. Recently, vision-to-planning systems have garnered increasing attention for their efficiency and ability to interpret and adapt to surrounding environments. However, traditional modular systems suffer from increased latency and error propagation, while purely data-driven approaches often overlook the robot's kinematic constraints. This oversight leads to discrepancies between planned trajectories and those that are executable. To address these challenges, we propose iKap, a novel vision-to-planning system that integrates the robot's kinematic model directly into the learning pipeline. iKap employs a self-supervised learning approach and incorporates the state transition model within a differentiable bi-level optimization framework. This integration ensures the network learns collision-free waypoints while satisfying kinematic constraints, enabling gradient back-propagation for end-to-end training. Our experimental results demonstrate that iKap achieves higher success rates and reduced latency compared to the state-of-the-art methods. Besides the complete system, iKap offers a visual-to-planning network that seamlessly integrates kinematics into various controllers, providing a robust solution for robots navigating complex and dynamic environments.
Generalized Animal Imitator: Agile Locomotion with Versatile Motion Prior
Oct 02, 2023The agility of animals, particularly in complex activities such as running, turning, jumping, and backflipping, stands as an exemplar for robotic system design. Transferring this suite of behaviors to legged robotic systems introduces essential inquiries: How can a robot be trained to learn multiple locomotion behaviors simultaneously? How can the robot execute these tasks with a smooth transition? And what strategies allow for the integrated application of these skills? This paper introduces the Versatile Instructable Motion prior (VIM) - a Reinforcement Learning framework designed to incorporate a range of agile locomotion tasks suitable for advanced robotic applications. Our framework enables legged robots to learn diverse agile low-level skills by imitating animal motions and manually designed motions with Functionality reward and Stylization reward. While the Functionality reward guides the robot's ability to adopt varied skills, the Stylization reward ensures performance alignment with reference motions. Our evaluations of the VIM framework span both simulation environments and real-world deployment. To our understanding, this is the first work that allows a robot to concurrently learn diverse agile locomotion tasks using a singular controller. Further details and supportive media can be found at our project site: https://rchalyang.github.io/VIM .