 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Jump for Off-road Navigation
Jan 31, 2026Low speed does not always guarantee safety in off-road driving. For instance, crossing a ditch may be risky at a low speed due to the risk of getting stuck, yet safe at a higher speed with a controlled, accelerated jump. Achieving such behavior requires path planning that explicitly models complex motion dynamics, whereas existing methods often neglect this aspect and plan solely based on positions or a fixed velocity. To address this gap, we introduce Motion-aware Traversability (MAT) representation to explicitly model terrain cost conditioned on actual robot motion. Instead of assigning a single scalar score for traversability, MAT models each terrain region as a Gaussian function of velocity. During online planning, we decompose the terrain cost computation into two stages: (1) predict terrain-dependent Gaussian parameters from perception in a single forward pass, (2) efficiently update terrain costs for new velocities inferred from current dynamics by evaluating these functions without repeated inference. We develop a system that integrates MAT to enable agile off-road navigation and evaluate it in both simulated and real-world environments with various obstacles. Results show that MAT achieves real-time efficiency and enhances the performance of off-road navigation, reducing path detours by 75% while maintaining safety across challenging terrains.
SuperPC: A Single Diffusion Model for Point Cloud Completion, Upsampling, Denoising, and Colorization
Mar 21, 2025

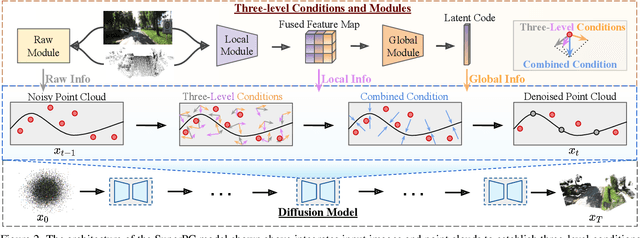

Point cloud (PC) processing tasks-such as completion, upsampling, denoising, and colorization-are crucial in applications like autonomous driving and 3D reconstruction. Despite substantial advancements, prior approaches often address each of these tasks independently, with separate models focused on individual issues. However, this isolated approach fails to account for the fact that defects like incompleteness, low resolution, noise, and lack of color frequently coexist, with each defect influencing and correlating with the others. Simply applying these models sequentially can lead to error accumulation from each model, along with increased computational costs. To address these challenges, we introduce SuperPC, the first unified diffusion model capable of concurrently handling all four tasks. Our approach employs a three-level-conditioned diffusion framework, enhanced by a novel spatial-mix-fusion strategy, to leverage the correlations among these four defects for simultaneous, efficient processing. We show that SuperPC outperforms the state-of-the-art specialized models as well as their combination on all four individual tasks.
VL-Nav: Real-time Vision-Language Navigation with Spatial Reasoning
Feb 02, 2025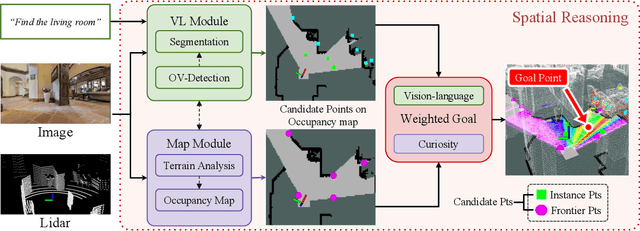



Vision-language navigation in unknown environments is crucial for mobile robots. In scenarios such as household assistance and rescue, mobile robots need to understand a human command, such as "find a person wearing black". We present a novel vision-language navigation (VL-Nav) system that integrates efficient spatial reasoning on low-power robots. Unlike prior methods that rely on a single image-level feature similarity to guide a robot, we introduce the heuristic-vision-language (HVL) spatial reasoning for goal point selection. It combines pixel-wise vision-language features and heuristic exploration to enable efficient navigation to human-instructed instances in various environments robustly. We deploy VL-Nav on a four-wheel mobile robot and conduct comprehensive navigation tasks in various environments of different scales and semantic complexities, indoors and outdoors. Remarkably, VL-Nav operates at a real-time frequency of 30 Hz with a Jetson Orin NX, highlighting its ability to conduct efficient vision-language navigation. Experimental results show that VL-Nav achieves an overall success rate of 86.3%, outperforming previous methods by 44.15%.
Imperative Learning: A Self-supervised Neural-Symbolic Learning Framework for Robot Autonomy
Jun 23, 2024



Data-driven methods such as reinforcement and imitation learning have achieved remarkable success in robot autonomy. However, their data-centric nature still hinders them from generalizing well to ever-changing environments. Moreover, collecting large datasets for robotic tasks is often impractical and expensive. To overcome these challenges, we introduce a new self-supervised neural-symbolic (NeSy) computational framework, imperative learning (IL), for robot autonomy, leveraging the generalization abilities of symbolic reasoning. The framework of IL consists of three primary components: a neural module, a reasoning engine, and a memory system. We formulate IL as a special bilevel optimization (BLO), which enables reciprocal learning over the three modules. This overcomes the label-intensive obstacles associated with data-driven approaches and takes advantage of symbolic reasoning concerning logical reasoning, physical principles, geometric analysis, etc. We discuss several optimization techniques for IL and verify their effectiveness in five distinct robot autonomy tasks including path planning, rule induction, optimal control, visual odometry, and multi-robot routing. Through various experiments, we show that IL can significantly enhance robot autonomy capabilities and we anticipate that it will catalyze further research across diverse domains.
PhysORD: A Neuro-Symbolic Approach for Physics-infused Motion Prediction in Off-road Driving
Apr 02, 2024Motion prediction is critical for autonomous off-road driving, however, it presents significantly more challenges than on-road driving because of the complex interaction between the vehicle and the terrain. Traditional physics-based approaches encounter difficulties in accurately modeling dynamic systems and external disturbance. In contrast, data-driven neural networks require extensive datasets and struggle with explicitly capturing the fundamental physical laws, which can easily lead to poor generalization. By merging the advantages of both methods, neuro-symbolic approaches present a promising direction. These methods embed physical laws into neural models, potentially significantly improving generalization capabilities. However, no prior works were evaluated in real-world settings for off-road driving. To bridge this gap, we present PhysORD, a neural-symbolic approach integrating the conservation law, i.e., the Euler-Lagrange equation, into data-driven neural models for motion prediction in off-road driving. Our experiments showed that PhysORD can accurately predict vehicle motion and tolerate external disturbance by modeling uncertainties. It outperforms existing methods both in accuracy and efficiency and demonstrates data-efficient learning and generalization ability in long-term prediction.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023
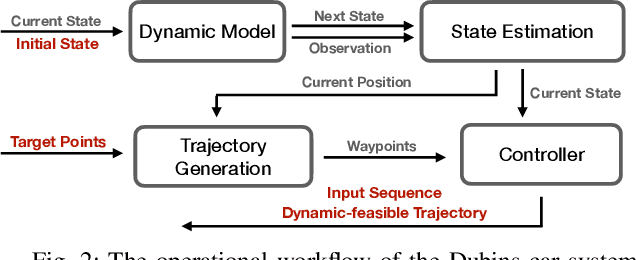
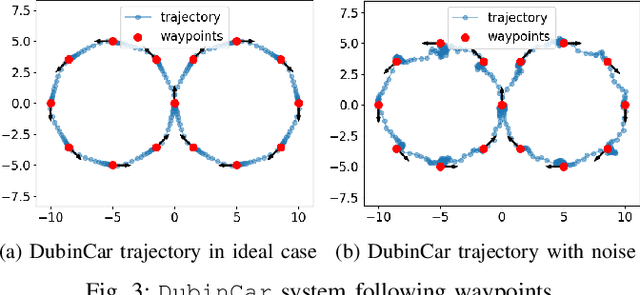
PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.
Dynamic Domain Discrepancy Adjustment for Active Multi-Domain Adaptation
Jul 26, 2023Multi-source unsupervised domain adaptation (MUDA) aims to transfer knowledge from related source domains to an unlabeled target domain. While recent MUDA methods have shown promising results, most focus on aligning the overall feature distributions across source domains, which can lead to negative effects due to redundant features within each domain. Moreover, there is a significant performance gap between MUDA and supervised methods. To address these challenges, we propose a novel approach called Dynamic Domain Discrepancy Adjustment for Active Multi-Domain Adaptation (D3AAMDA). Firstly, we establish a multi-source dynamic modulation mechanism during the training process based on the degree of distribution differences between source and target domains. This mechanism controls the alignment level of features between each source domain and the target domain, effectively leveraging the local advantageous feature information within the source domains. Additionally, we propose a Multi-source Active Boundary Sample Selection (MABS) strategy, which utilizes a guided dynamic boundary loss to design an efficient query function for selecting important samples. This strategy achieves improved generalization to the target domain with minimal sampling costs. We extensively evaluate our proposed method on commonly used domain adaptation datasets, comparing it against existing UDA and ADA methods. The experimental results unequivocally demonstrate the superiority of our approach.
Alleviating the Long-Tail Problem in Conversational Recommender Systems
Jul 21, 2023Conversational recommender systems (CRS) aim to provide the recommendation service via natural language conversations. To develop an effective CRS, high-quality CRS datasets are very crucial. However, existing CRS datasets suffer from the long-tail issue, \ie a large proportion of items are rarely (or even never) mentioned in the conversations, which are called long-tail items. As a result, the CRSs trained on these datasets tend to recommend frequent items, and the diversity of the recommended items would be largely reduced, making users easier to get bored. To address this issue, this paper presents \textbf{LOT-CRS}, a novel framework that focuses on simulating and utilizing a balanced CRS dataset (\ie covering all the items evenly) for improving \textbf{LO}ng-\textbf{T}ail recommendation performance of CRSs. In our approach, we design two pre-training tasks to enhance the understanding of simulated conversation for long-tail items, and adopt retrieval-augmented fine-tuning with label smoothness strategy to further improve the recommendation of long-tail items. Extensive experiments on two public CRS datasets have demonstrated the effectiveness and extensibility of our approach, especially on long-tail recommendation.
Multi-Granularity Detector for Vulnerability Fixes
May 23, 2023



With the increasing reliance on Open Source Software, users are exposed to third-party library vulnerabilities. Software Composition Analysis (SCA) tools have been created to alert users of such vulnerabilities. SCA requires the identification of vulnerability-fixing commits. Prior works have proposed methods that can automatically identify such vulnerability-fixing commits. However, identifying such commits is highly challenging, as only a very small minority of commits are vulnerability fixing. Moreover, code changes can be noisy and difficult to analyze. We observe that noise can occur at different levels of detail, making it challenging to detect vulnerability fixes accurately. To address these challenges and boost the effectiveness of prior works, we propose MiDas (Multi-Granularity Detector for Vulnerability Fixes). Unique from prior works, Midas constructs different neural networks for each level of code change granularity, corresponding to commit-level, file-level, hunk-level, and line-level, following their natural organization. It then utilizes an ensemble model that combines all base models to generate the final prediction. This design allows MiDas to better handle the noisy and highly imbalanced nature of vulnerability-fixing commit data. Additionally, to reduce the human effort required to inspect code changes, we have designed an effort-aware adjustment for Midas's outputs based on commit length. The evaluation results demonstrate that MiDas outperforms the current state-of-the-art baseline in terms of AUC by 4.9% and 13.7% on Java and Python-based datasets, respectively. Furthermore, in terms of two effort-aware metrics, EffortCost@L and Popt@L, MiDas also outperforms the state-of-the-art baseline, achieving improvements of up to 28.2% and 15.9% on Java, and 60% and 51.4% on Python, respectively.
Attention-Enhanced Cross-modal Localization Between 360 Images and Point Clouds
Dec 06, 2022
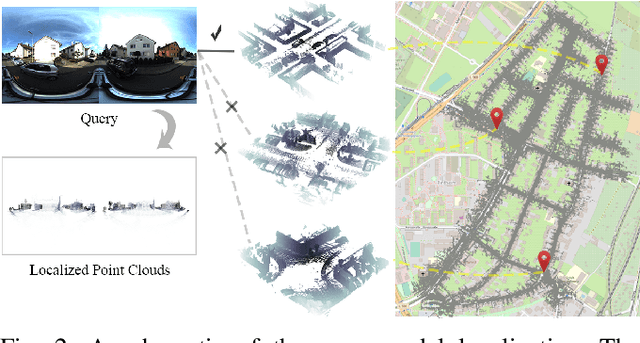


Visual localization plays an important role for intelligent robots and autonomous driving, especially when the accuracy of GNSS is unreliable. Recently, camera localization in LiDAR maps has attracted more and more attention for its low cost and potential robustness to illumination and weather changes. However, the commonly used pinhole camera has a narrow Field-of-View, thus leading to limited information compared with the omni-directional LiDAR data. To overcome this limitation, we focus on correlating the information of 360 equirectangular images to point clouds, proposing an end-to-end learnable network to conduct cross-modal visual localization by establishing similarity in high-dimensional feature space. Inspired by the attention mechanism, we optimize the network to capture the salient feature for comparing images and point clouds. We construct several sequences containing 360 equirectangular images and corresponding point clouds based on the KITTI-360 dataset and conduct extensive experiments. The results demonstrate the effectiveness of our approach.