 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperPC: A Single Diffusion Model for Point Cloud Completion, Upsampling, Denoising, and Colorization
Mar 21, 2025

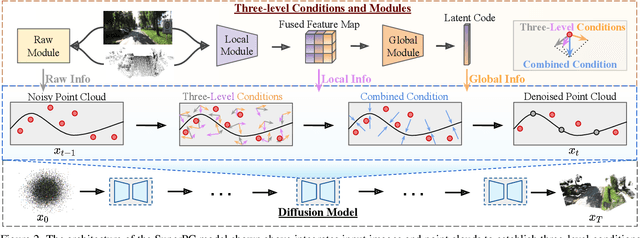

Point cloud (PC) processing tasks-such as completion, upsampling, denoising, and colorization-are crucial in applications like autonomous driving and 3D reconstruction. Despite substantial advancements, prior approaches often address each of these tasks independently, with separate models focused on individual issues. However, this isolated approach fails to account for the fact that defects like incompleteness, low resolution, noise, and lack of color frequently coexist, with each defect influencing and correlating with the others. Simply applying these models sequentially can lead to error accumulation from each model, along with increased computational costs. To address these challenges, we introduce SuperPC, the first unified diffusion model capable of concurrently handling all four tasks. Our approach employs a three-level-conditioned diffusion framework, enhanced by a novel spatial-mix-fusion strategy, to leverage the correlations among these four defects for simultaneous, efficient processing. We show that SuperPC outperforms the state-of-the-art specialized models as well as their combination on all four individual tasks.
LightGen: Efficient Image Generation through Knowledge Distillation and Direct Preference Optimization
Mar 11, 2025



Recent advances in text-to-image generation have primarily relied on extensive datasets and parameter-heavy architectures. These requirements severely limit accessibility for researchers and practitioners who lack substantial computational resources. In this paper, we introduce \model, an efficient training paradigm for image generation models that uses knowledge distillation (KD) and Direct Preference Optimization (DPO). Drawing inspiration from the success of data KD techniques widely adopted in Multi-Modal Large Language Models (MLLMs), LightGen distills knowledge from state-of-the-art (SOTA) text-to-image models into a compact Masked Autoregressive (MAR) architecture with only $0.7B$ parameters. Using a compact synthetic dataset of just $2M$ high-quality images generated from varied captions, we demonstrate that data diversity significantly outweighs data volume in determining model performance. This strategy dramatically reduces computational demands and reduces pre-training time from potentially thousands of GPU-days to merely 88 GPU-days. Furthermore, to address the inherent shortcomings of synthetic data, particularly poor high-frequency details and spatial inaccuracies, we integrate the DPO technique that refines image fidelity and positional accuracy. Comprehensive experiments confirm that LightGen achieves image generation quality comparable to SOTA models while significantly reducing computational resources and expanding accessibility for resource-constrained environments. Code is available at https://github.com/XianfengWu01/LightGen
AirRoom: Objects Matter in Room Reidentification
Mar 03, 2025Room reidentification (ReID) is a challenging yet essential task with numerous applications in fields such as augmented reality (AR) and homecare robotics. Existing visual place recognition (VPR) methods, which typically rely on global descriptors or aggregate local features, often struggle in cluttered indoor environments densely populated with man-made objects. These methods tend to overlook the crucial role of object-oriented information. To address this, we propose AirRoom, an object-aware pipeline that integrates multi-level object-oriented information-from global context to object patches, object segmentation, and keypoints-utilizing a coarse-to-fine retrieval approach. Extensive experiments on four newly constructed datasets-MPReID, HMReID, GibsonReID, and ReplicaReID-demonstrate that AirRoom outperforms state-of-the-art (SOTA) models across nearly all evaluation metrics, with improvements ranging from 6% to 80%. Moreover, AirRoom exhibits significant flexibility, allowing various modules within the pipeline to be substituted with different alternatives without compromising overall performance. It also shows robust and consistent performance under diverse viewpoint variations.
iKap: Kinematics-aware Planning with Imperative Learning
Dec 12, 2024Trajectory planning in robotics aims to generate collision-free pose sequences that can be reliably executed. Recently, vision-to-planning systems have garnered increasing attention for their efficiency and ability to interpret and adapt to surrounding environments. However, traditional modular systems suffer from increased latency and error propagation, while purely data-driven approaches often overlook the robot's kinematic constraints. This oversight leads to discrepancies between planned trajectories and those that are executable. To address these challenges, we propose iKap, a novel vision-to-planning system that integrates the robot's kinematic model directly into the learning pipeline. iKap employs a self-supervised learning approach and incorporates the state transition model within a differentiable bi-level optimization framework. This integration ensures the network learns collision-free waypoints while satisfying kinematic constraints, enabling gradient back-propagation for end-to-end training. Our experimental results demonstrate that iKap achieves higher success rates and reduced latency compared to the state-of-the-art methods. Besides the complete system, iKap offers a visual-to-planning network that seamlessly integrates kinematics into various controllers, providing a robust solution for robots navigating complex and dynamic environments.