 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchoredDream: Zero-Shot 360° Indoor Scene Generation from a Single View via Geometric Grounding
Jan 26, 2026Single-view indoor scene generation plays a crucial role in a range of real-world applications. However, generating a complete 360° scene from a single image remains a highly ill-posed and challenging problem. Recent approaches have made progress by leveraging diffusion models and depth estimation networks, yet they still struggle to maintain appearance consistency and geometric plausibility under large viewpoint changes, limiting their effectiveness in full-scene generation. To address this, we propose AnchoredDream, a novel zero-shot pipeline that anchors 360° scene generation on high-fidelity geometry via an appearance-geometry mutual boosting mechanism. Given a single-view image, our method first performs appearance-guided geometry generation to construct a reliable 3D scene layout. Then, we progressively generate the complete scene through a series of modules: warp-and-inpaint, warp-and-refine, post-optimization, and a novel Grouting Block, which ensures seamless transitions between the input view and generated regions. Extensive experiments demonstrate that AnchoredDream outperforms existing methods by a large margin in both appearance consistency and geometric plausibility--all in a zero-shot manner. Our results highlight the potential of geometric grounding for high-quality, zero-shot single-view scene generation.
SuperPC: A Single Diffusion Model for Point Cloud Completion, Upsampling, Denoising, and Colorization
Mar 21, 2025

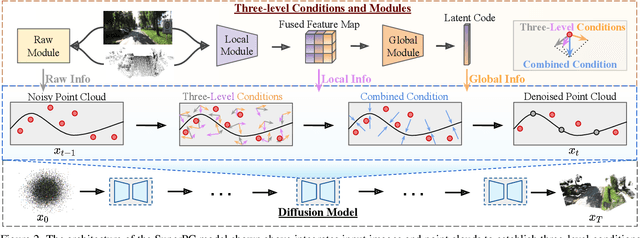

Point cloud (PC) processing tasks-such as completion, upsampling, denoising, and colorization-are crucial in applications like autonomous driving and 3D reconstruction. Despite substantial advancements, prior approaches often address each of these tasks independently, with separate models focused on individual issues. However, this isolated approach fails to account for the fact that defects like incompleteness, low resolution, noise, and lack of color frequently coexist, with each defect influencing and correlating with the others. Simply applying these models sequentially can lead to error accumulation from each model, along with increased computational costs. To address these challenges, we introduce SuperPC, the first unified diffusion model capable of concurrently handling all four tasks. Our approach employs a three-level-conditioned diffusion framework, enhanced by a novel spatial-mix-fusion strategy, to leverage the correlations among these four defects for simultaneous, efficient processing. We show that SuperPC outperforms the state-of-the-art specialized models as well as their combination on all four individual tasks.
AirRoom: Objects Matter in Room Reidentification
Mar 03, 2025Room reidentification (ReID) is a challenging yet essential task with numerous applications in fields such as augmented reality (AR) and homecare robotics. Existing visual place recognition (VPR) methods, which typically rely on global descriptors or aggregate local features, often struggle in cluttered indoor environments densely populated with man-made objects. These methods tend to overlook the crucial role of object-oriented information. To address this, we propose AirRoom, an object-aware pipeline that integrates multi-level object-oriented information-from global context to object patches, object segmentation, and keypoints-utilizing a coarse-to-fine retrieval approach. Extensive experiments on four newly constructed datasets-MPReID, HMReID, GibsonReID, and ReplicaReID-demonstrate that AirRoom outperforms state-of-the-art (SOTA) models across nearly all evaluation metrics, with improvements ranging from 6% to 80%. Moreover, AirRoom exhibits significant flexibility, allowing various modules within the pipeline to be substituted with different alternatives without compromising overall performance. It also shows robust and consistent performance under diverse viewpoint variations.