 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Paper-to-Paper: Structured Profiling and Rubric Scoring for Paper-Reviewer Matching
Apr 07, 2026As conference submission volumes continue to grow, accurately recommending suitable reviewers has become a challenge. Most existing methods follow a ``Paper-to-Paper'' matching paradigm, implicitly representing a reviewer by their publication history. However, effective reviewer matching requires capturing multi-dimensional expertise, and textual similarity to past papers alone is often insufficient. To address this gap, we propose P2R, a training-free framework that shifts from implicit paper-to-paper matching to explicit profile-based matching. P2R uses general-purpose LLMs to construct structured profiles for both submissions and reviewers, disentangling them into Topics, Methodologies, and Applications. Building on these profiles, P2R adopts a coarse-to-fine pipeline to balance efficiency and depth. It first performs hybrid retrieval that combines semantic and aspect-level signals to form a high-recall candidate pool, and then applies an LLM-based committee to evaluate candidates under strict rubrics, integrating both multi-dimensional expert views and a holistic Area Chair perspective. Experiments on NeurIPS, SIGIR, and SciRepEval show that P2R consistently outperforms state-of-the-art baselines. Ablation studies further verify the necessity of each component. Overall, P2R highlights the value of explicit, structured expertise modeling and offers practical guidance for applying LLMs to reviewer matching.
GSMem: 3D Gaussian Splatting as Persistent Spatial Memory for Zero-Shot Embodied Exploration and Reasoning
Mar 19, 2026Effective embodied exploration requires agents to accumulate and retain spatial knowledge over time. However, existing scene representations, such as discrete scene graphs or static view-based snapshots, lack \textit{post-hoc re-observability}. If an initial observation misses a target, the resulting memory omission is often irrecoverable. To bridge this gap, we propose \textbf{GSMem}, a zero-shot embodied exploration and reasoning framework built upon 3D Gaussian Splatting (3DGS). By explicitly parameterizing continuous geometry and dense appearance, 3DGS serves as a persistent spatial memory that endows the agent with \textit{Spatial Recollection}: the ability to render photorealistic novel views from optimal, previously unoccupied viewpoints. To operationalize this, GSMem employs a retrieval mechanism that simultaneously leverages parallel object-level scene graphs and semantic-level language fields. This complementary design robustly localizes target regions, enabling the agent to ``hallucinate'' optimal views for high-fidelity Vision-Language Model (VLM) reasoning. Furthermore, we introduce a hybrid exploration strategy that combines VLM-driven semantic scoring with a 3DGS-based coverage objective, balancing task-aware exploration with geometric coverage. Extensive experiments on embodied question answering and lifelong navigation demonstrate the robustness and effectiveness of our framework
Distilling Closed-Source LLM's Knowledge for Locally Stable and Economic Biomedical Entity Linking
May 26, 2025Biomedical entity linking aims to map nonstandard entities to standard entities in a knowledge base. Traditional supervised methods perform well but require extensive annotated data to transfer, limiting their usage in low-resource scenarios. Large language models (LLMs), especially closed-source LLMs, can address these but risk stability issues and high economic costs: using these models is restricted by commercial companies and brings significant economic costs when dealing with large amounts of data. To address this, we propose ``RPDR'', a framework combining closed-source LLMs and open-source LLMs for re-ranking candidates retrieved by a retriever fine-tuned with a small amount of data. By prompting a closed-source LLM to generate training data from unannotated data and fine-tuning an open-source LLM for re-ranking, we effectively distill the knowledge to the open-source LLM that can be deployed locally, thus avoiding the stability issues and the problem of high economic costs. We evaluate RPDR on two datasets, including one real-world dataset and one publicly available dataset involving two languages: Chinese and English. RPDR achieves 0.019 Acc@1 improvement and 0.036 Acc@1 improvement on the Aier dataset and the Ask A Patient dataset when the amount of training data is not enough. The results demonstrate the superiority and generalizability of the proposed framework.
Disentangled Multi-span Evolutionary Network against Temporal Knowledge Graph Reasoning
May 20, 2025Temporal Knowledge Graphs (TKGs), as an extension of static Knowledge Graphs (KGs), incorporate the temporal feature to express the transience of knowledge by describing when facts occur. TKG extrapolation aims to infer possible future facts based on known history, which has garnered significant attention in recent years. Some existing methods treat TKG as a sequence of independent subgraphs to model temporal evolution patterns, demonstrating impressive reasoning performance. However, they still have limitations: 1) In modeling subgraph semantic evolution, they usually neglect the internal structural interactions between subgraphs, which are actually crucial for encoding TKGs. 2) They overlook the potential smooth features that do not lead to semantic changes, which should be distinguished from the semantic evolution process. Therefore, we propose a novel Disentangled Multi-span Evolutionary Network (DiMNet) for TKG reasoning. Specifically, we design a multi-span evolution strategy that captures local neighbor features while perceiving historical neighbor semantic information, thus enabling internal interactions between subgraphs during the evolution process. To maximize the capture of semantic change patterns, we design a disentangle component that adaptively separates nodes' active and stable features, used to dynamically control the influence of historical semantics on future evolution. Extensive experiments conducted on four real-world TKG datasets show that DiMNet demonstrates substantial performance in TKG reasoning, and outperforms the state-of-the-art up to 22.7% in MRR.
Collaborative Multi-Agent Reinforcement Learning for Automated Feature Transformation with Graph-Driven Path Optimization
Apr 24, 2025



Feature transformation methods aim to find an optimal mathematical feature-feature crossing process that generates high-value features and improves the performance of downstream machine learning tasks. Existing frameworks, though designed to mitigate manual costs, often treat feature transformations as isolated operations, ignoring dynamic dependencies between transformation steps. To address the limitations, we propose TCTO, a collaborative multi-agent reinforcement learning framework that automates feature engineering through graph-driven path optimization. The framework's core innovation lies in an evolving interaction graph that models features as nodes and transformations as edges. Through graph pruning and backtracking, it dynamically eliminates low-impact edges, reduces redundant operations, and enhances exploration stability. This graph also provides full traceability to empower TCTO to reuse high-utility subgraphs from historical transformations. To demonstrate the efficacy and adaptability of our approach, we conduct comprehensive experiments and case studies, which show superior performance across a range of datasets.
Comprehend, Divide, and Conquer: Feature Subspace Exploration via Multi-Agent Hierarchical Reinforcement Learning
Apr 24, 2025



Feature selection aims to preprocess the target dataset, find an optimal and most streamlined feature subset, and enhance the downstream machine learning task. Among filter, wrapper, and embedded-based approaches, the reinforcement learning (RL)-based subspace exploration strategy provides a novel objective optimization-directed perspective and promising performance. Nevertheless, even with improved performance, current reinforcement learning approaches face challenges similar to conventional methods when dealing with complex datasets. These challenges stem from the inefficient paradigm of using one agent per feature and the inherent complexities present in the datasets. This observation motivates us to investigate and address the above issue and propose a novel approach, namely HRLFS. Our methodology initially employs a Large Language Model (LLM)-based hybrid state extractor to capture each feature's mathematical and semantic characteristics. Based on this information, features are clustered, facilitating the construction of hierarchical agents for each cluster and sub-cluster. Extensive experiments demonstrate the efficiency, scalability, and robustness of our approach. Compared to contemporary or the one-feature-one-agent RL-based approaches, HRLFS improves the downstream ML performance with iterative feature subspace exploration while accelerating total run time by reducing the number of agents involved.
Parasite: A Steganography-based Backdoor Attack Framework for Diffusion Models
Apr 08, 2025



Recently, the diffusion model has gained significant attention as one of the most successful image generation models, which can generate high-quality images by iteratively sampling noise. However, recent studies have shown that diffusion models are vulnerable to backdoor attacks, allowing attackers to enter input data containing triggers to activate the backdoor and generate their desired output. Existing backdoor attack methods primarily focused on target noise-to-image and text-to-image tasks, with limited work on backdoor attacks in image-to-image tasks. Furthermore, traditional backdoor attacks often rely on a single, conspicuous trigger to generate a fixed target image, lacking concealability and flexibility. To address these limitations, we propose a novel backdoor attack method called "Parasite" for image-to-image tasks in diffusion models, which not only is the first to leverage steganography for triggers hiding, but also allows attackers to embed the target content as a backdoor trigger to achieve a more flexible attack. "Parasite" as a novel attack method effectively bypasses existing detection frameworks to execute backdoor attacks. In our experiments, "Parasite" achieved a 0 percent backdoor detection rate against the mainstream defense frameworks. In addition, in the ablation study, we discuss the influence of different hiding coefficients on the attack results. You can find our code at https://anonymous.4open.science/r/Parasite-1715/.
FastFT: Accelerating Reinforced Feature Transformation via Advanced Exploration Strategies
Mar 26, 2025



Feature Transformation is crucial for classic machine learning that aims to generate feature combinations to enhance the performance of downstream tasks from a data-centric perspective. Current methodologies, such as manual expert-driven processes, iterative-feedback techniques, and exploration-generative tactics, have shown promise in automating such data engineering workflow by minimizing human involvement. However, three challenges remain in those frameworks: (1) It predominantly depends on downstream task performance metrics, as assessment is time-consuming, especially for large datasets. (2) The diversity of feature combinations will hardly be guaranteed after random exploration ends. (3) Rare significant transformations lead to sparse valuable feedback that hinders the learning processes or leads to less effective results. In response to these challenges, we introduce FastFT, an innovative framework that leverages a trio of advanced strategies.We first decouple the feature transformation evaluation from the outcomes of the generated datasets via the performance predictor. To address the issue of reward sparsity, we developed a method to evaluate the novelty of generated transformation sequences. Incorporating this novelty into the reward function accelerates the model's exploration of effective transformations, thereby improving the search productivity. Additionally, we combine novelty and performance to create a prioritized memory buffer, ensuring that essential experiences are effectively revisited during exploration. Our extensive experimental evaluations validate the performance, efficiency, and traceability of our proposed framework, showcasing its superiority in handling complex feature transformation tasks.
SuperPC: A Single Diffusion Model for Point Cloud Completion, Upsampling, Denoising, and Colorization
Mar 21, 2025

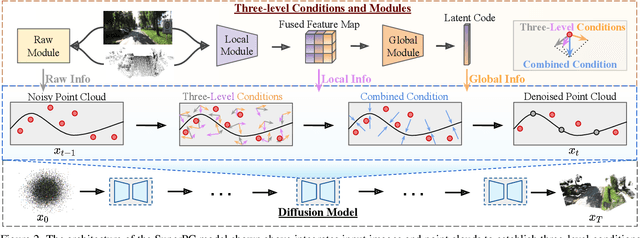

Point cloud (PC) processing tasks-such as completion, upsampling, denoising, and colorization-are crucial in applications like autonomous driving and 3D reconstruction. Despite substantial advancements, prior approaches often address each of these tasks independently, with separate models focused on individual issues. However, this isolated approach fails to account for the fact that defects like incompleteness, low resolution, noise, and lack of color frequently coexist, with each defect influencing and correlating with the others. Simply applying these models sequentially can lead to error accumulation from each model, along with increased computational costs. To address these challenges, we introduce SuperPC, the first unified diffusion model capable of concurrently handling all four tasks. Our approach employs a three-level-conditioned diffusion framework, enhanced by a novel spatial-mix-fusion strategy, to leverage the correlations among these four defects for simultaneous, efficient processing. We show that SuperPC outperforms the state-of-the-art specialized models as well as their combination on all four individual tasks.
AirRoom: Objects Matter in Room Reidentification
Mar 03, 2025



Room reidentification (ReID) is a challenging yet essential task with numerous applications in fields such as augmented reality (AR) and homecare robotics. Existing visual place recognition (VPR) methods, which typically rely on global descriptors or aggregate local features, often struggle in cluttered indoor environments densely populated with man-made objects. These methods tend to overlook the crucial role of object-oriented information. To address this, we propose AirRoom, an object-aware pipeline that integrates multi-level object-oriented information-from global context to object patches, object segmentation, and keypoints-utilizing a coarse-to-fine retrieval approach. Extensive experiments on four newly constructed datasets-MPReID, HMReID, GibsonReID, and ReplicaReID-demonstrate that AirRoom outperforms state-of-the-art (SOTA) models across nearly all evaluation metrics, with improvements ranging from 6% to 80%. Moreover, AirRoom exhibits significant flexibility, allowing various modules within the pipeline to be substituted with different alternatives without compromising overall performance. It also shows robust and consistent performance under diverse viewpoint variations.