 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDAPose: Unsupervised Domain Adaptation for Low-Light Human Pose Estimation
Apr 12, 2026Low-visibility scenarios, such as low-light conditions, pose significant challenges to human pose estimation due to the scarcity of annotated low-light datasets and the loss of visual information under poor illumination. Recent domain adaptation techniques attempt to utilize well-lit labels by augmenting well-lit images to mimic low-light conditions. But handcrafted augmentations oversimplify noise patterns, while learning-based methods often fail to preserve high-frequency low-light characteristics, producing unrealistic images that lead pose models to generalize poorly to real low-light scenes. Moreover, recent pose estimators rely on image cues through image-to-keypoint cross-attention, but these cues become unreliable under low-light conditions. To address these issues, we propose Unsupervised Domain Adaptation for Pose Estimation (UDAPose), a novel framework that synthesizes low-light images and dynamically fuses visual cues with pose priors for improved pose estimation. Specifically, our synthesis method incorporates a Direct-Current-based High-Pass Filter (DHF) and a Low-light Characteristics Injection Module (LCIM) to inject high-frequency details from input low-light images, overcoming rigidity or the detail loss in existing approaches. Furthermore, we introduce a Dynamic Control of Attention (DCA) module that adaptively balances image cues with learned pose priors in the Transformer architecture. Experiments show that UDAPose outperforms state-of-the-art methods, with notable AP gains of 10.1 (56.4%) on the ExLPose-test hard set (LL-H) and 7.4 (31.4%) in cross-dataset validation on EHPT-XC. Code: https://github.com/Vision-and-Multimodal-Intelligence-Lab/UDAPose
Distilling Closed-Source LLM's Knowledge for Locally Stable and Economic Biomedical Entity Linking
May 26, 2025Biomedical entity linking aims to map nonstandard entities to standard entities in a knowledge base. Traditional supervised methods perform well but require extensive annotated data to transfer, limiting their usage in low-resource scenarios. Large language models (LLMs), especially closed-source LLMs, can address these but risk stability issues and high economic costs: using these models is restricted by commercial companies and brings significant economic costs when dealing with large amounts of data. To address this, we propose ``RPDR'', a framework combining closed-source LLMs and open-source LLMs for re-ranking candidates retrieved by a retriever fine-tuned with a small amount of data. By prompting a closed-source LLM to generate training data from unannotated data and fine-tuning an open-source LLM for re-ranking, we effectively distill the knowledge to the open-source LLM that can be deployed locally, thus avoiding the stability issues and the problem of high economic costs. We evaluate RPDR on two datasets, including one real-world dataset and one publicly available dataset involving two languages: Chinese and English. RPDR achieves 0.019 Acc@1 improvement and 0.036 Acc@1 improvement on the Aier dataset and the Ask A Patient dataset when the amount of training data is not enough. The results demonstrate the superiority and generalizability of the proposed framework.
Domain-Adaptive 2D Human Pose Estimation via Dual Teachers in Extremely Low-Light Conditions
Jul 23, 2024



Existing 2D human pose estimation research predominantly concentrates on well-lit scenarios, with limited exploration of poor lighting conditions, which are a prevalent aspect of daily life. Recent studies on low-light pose estimation require the use of paired well-lit and low-light images with ground truths for training, which are impractical due to the inherent challenges associated with annotation on low-light images. To this end, we introduce a novel approach that eliminates the need for low-light ground truths. Our primary novelty lies in leveraging two complementary-teacher networks to generate more reliable pseudo labels, enabling our model achieves competitive performance on extremely low-light images without the need for training with low-light ground truths. Our framework consists of two stages. In the first stage, our model is trained on well-lit data with low-light augmentations. In the second stage, we propose a dual-teacher framework to utilize the unlabeled low-light data, where a center-based main teacher produces the pseudo labels for relatively visible cases, while a keypoints-based complementary teacher focuses on producing the pseudo labels for the missed persons of the main teacher. With the pseudo labels from both teachers, we propose a person-specific low-light augmentation to challenge a student model in training to outperform the teachers. Experimental results on real low-light dataset (ExLPose-OCN) show, our method achieves 6.8% (2.4 AP) improvement over the state-of-the-art (SOTA) method, despite no low-light ground-truth data is used in our approach, in contrast to the SOTA method. Our code will be available at:https://github.com/ayh015-dev/DA-LLPose.
Bottom-Up 2D Pose Estimation via Dual Anatomical Centers for Small-Scale Persons
Aug 25, 2022

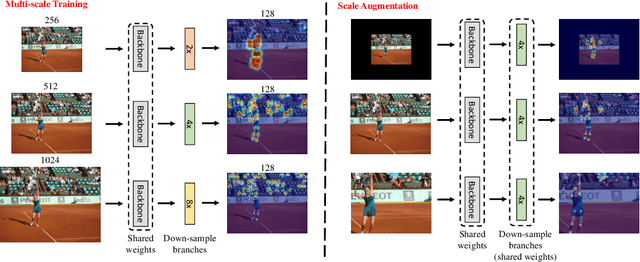

In multi-person 2D pose estimation, the bottom-up methods simultaneously predict poses for all persons, and unlike the top-down methods, do not rely on human detection. However, the SOTA bottom-up methods' accuracy is still inferior compared to the existing top-down methods. This is due to the predicted human poses being regressed based on the inconsistent human bounding box center and the lack of human-scale normalization, leading to the predicted human poses being inaccurate and small-scale persons being missed. To push the envelope of the bottom-up pose estimation, we firstly propose multi-scale training to enhance the network to handle scale variation with single-scale testing, particularly for small-scale persons. Secondly, we introduce dual anatomical centers (i.e., head and body), where we can predict the human poses more accurately and reliably, especially for small-scale persons. Moreover, existing bottom-up methods use multi-scale testing to boost the accuracy of pose estimation at the price of multiple additional forward passes, which weakens the efficiency of bottom-up methods, the core strength compared to top-down methods. By contrast, our multi-scale training enables the model to predict high-quality poses in a single forward pass (i.e., single-scale testing). Our method achieves 38.4\% improvement on bounding box precision and 39.1\% improvement on bounding box recall over the state of the art (SOTA) on the challenging small-scale persons subset of COCO. For the human pose AP evaluation, we achieve a new SOTA (71.0 AP) on the COCO test-dev set with the single-scale testing. We also achieve the top performance (40.3 AP) on OCHuman dataset in cross-dataset evaluation.