 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSponge Tool Attack: Stealthy Denial-of-Efficiency against Tool-Augmented Agentic Reasoning
Jan 24, 2026Enabling large language models (LLMs) to solve complex reasoning tasks is a key step toward artificial general intelligence. Recent work augments LLMs with external tools to enable agentic reasoning, achieving high utility and efficiency in a plug-and-play manner. However, the inherent vulnerabilities of such methods to malicious manipulation of the tool-calling process remain largely unexplored. In this work, we identify a tool-specific attack surface and propose Sponge Tool Attack (STA), which disrupts agentic reasoning solely by rewriting the input prompt under a strict query-only access assumption. Without any modification on the underlying model or the external tools, STA converts originally concise and efficient reasoning trajectories into unnecessarily verbose and convoluted ones before arriving at the final answer. This results in substantial computational overhead while remaining stealthy by preserving the original task semantics and user intent. To achieve this, we design STA as an iterative, multi-agent collaborative framework with explicit rewritten policy control, and generates benign-looking prompt rewrites from the original one with high semantic fidelity. Extensive experiments across 6 models (including both open-source models and closed-source APIs), 12 tools, 4 agentic frameworks, and 13 datasets spanning 5 domains validate the effectiveness of STA.
Refinement Provenance Inference: Detecting LLM-Refined Training Prompts from Model Behavior
Jan 05, 2026Instruction tuning increasingly relies on LLM-based prompt refinement, where prompts in the training corpus are selectively rewritten by an external refiner to improve clarity and instruction alignment. This motivates an instance-level audit problem: for a fine-tuned model and a training prompt-response pair, can we infer whether the model was trained on the original prompt or its LLM-refined version within a mixed corpus? This matters for dataset governance and dispute resolution when training data are contested. However, it is non-trivial in practice: refined and raw instances are interleaved in the training corpus with unknown, source-dependent mixture ratios, making it harder to develop provenance methods that generalize across models and training setups. In this paper, we formalize this audit task as Refinement Provenance Inference (RPI) and show that prompt refinement yields stable, detectable shifts in teacher-forced token distributions, even when semantic differences are not obvious. Building on this phenomenon, we propose RePro, a logit-based provenance framework that fuses teacher-forced likelihood features with logit-ranking signals. During training, RePro learns a transferable representation via shadow fine-tuning, and uses a lightweight linear head to infer provenance on unseen victims without training-data access. Empirically, RePro consistently attains strong performance and transfers well across refiners, suggesting that it exploits refiner-agnostic distribution shifts rather than rewrite-style artifacts.
SpotEdit: Selective Region Editing in Diffusion Transformers
Dec 26, 2025Diffusion Transformer models have significantly advanced image editing by encoding conditional images and integrating them into transformer layers. However, most edits involve modifying only small regions, while current methods uniformly process and denoise all tokens at every timestep, causing redundant computation and potentially degrading unchanged areas. This raises a fundamental question: Is it truly necessary to regenerate every region during editing? To address this, we propose SpotEdit, a training-free diffusion editing framework that selectively updates only the modified regions. SpotEdit comprises two key components: SpotSelector identifies stable regions via perceptual similarity and skips their computation by reusing conditional image features; SpotFusion adaptively blends these features with edited tokens through a dynamic fusion mechanism, preserving contextual coherence and editing quality. By reducing unnecessary computation and maintaining high fidelity in unmodified areas, SpotEdit achieves efficient and precise image editing.
WorldWarp: Propagating 3D Geometry with Asynchronous Video Diffusion
Dec 22, 2025Generating long-range, geometrically consistent video presents a fundamental dilemma: while consistency demands strict adherence to 3D geometry in pixel space, state-of-the-art generative models operate most effectively in a camera-conditioned latent space. This disconnect causes current methods to struggle with occluded areas and complex camera trajectories. To bridge this gap, we propose WorldWarp, a framework that couples a 3D structural anchor with a 2D generative refiner. To establish geometric grounding, WorldWarp maintains an online 3D geometric cache built via Gaussian Splatting (3DGS). By explicitly warping historical content into novel views, this cache acts as a structural scaffold, ensuring each new frame respects prior geometry. However, static warping inevitably leaves holes and artifacts due to occlusions. We address this using a Spatio-Temporal Diffusion (ST-Diff) model designed for a "fill-and-revise" objective. Our key innovation is a spatio-temporal varying noise schedule: blank regions receive full noise to trigger generation, while warped regions receive partial noise to enable refinement. By dynamically updating the 3D cache at every step, WorldWarp maintains consistency across video chunks. Consequently, it achieves state-of-the-art fidelity by ensuring that 3D logic guides structure while diffusion logic perfects texture. Project page: \href{https://hyokong.github.io/worldwarp-page/}{https://hyokong.github.io/worldwarp-page/}.
C4D: 4D Made from 3D through Dual Correspondences
Oct 16, 2025Recovering 4D from monocular video, which jointly estimates dynamic geometry and camera poses, is an inevitably challenging problem. While recent pointmap-based 3D reconstruction methods (e.g., DUSt3R) have made great progress in reconstructing static scenes, directly applying them to dynamic scenes leads to inaccurate results. This discrepancy arises because moving objects violate multi-view geometric constraints, disrupting the reconstruction. To address this, we introduce C4D, a framework that leverages temporal Correspondences to extend existing 3D reconstruction formulation to 4D. Specifically, apart from predicting pointmaps, C4D captures two types of correspondences: short-term optical flow and long-term point tracking. We train a dynamic-aware point tracker that provides additional mobility information, facilitating the estimation of motion masks to separate moving elements from the static background, thus offering more reliable guidance for dynamic scenes. Furthermore, we introduce a set of dynamic scene optimization objectives to recover per-frame 3D geometry and camera parameters. Simultaneously, the correspondences lift 2D trajectories into smooth 3D trajectories, enabling fully integrated 4D reconstruction. Experiments show that our framework achieves complete 4D recovery and demonstrates strong performance across multiple downstream tasks, including depth estimation, camera pose estimation, and point tracking. Project Page: https://littlepure2333.github.io/C4D
dParallel: Learnable Parallel Decoding for dLLMs
Sep 30, 2025
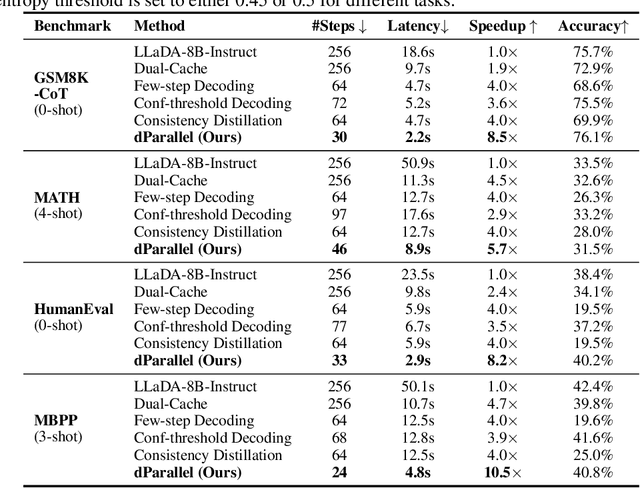
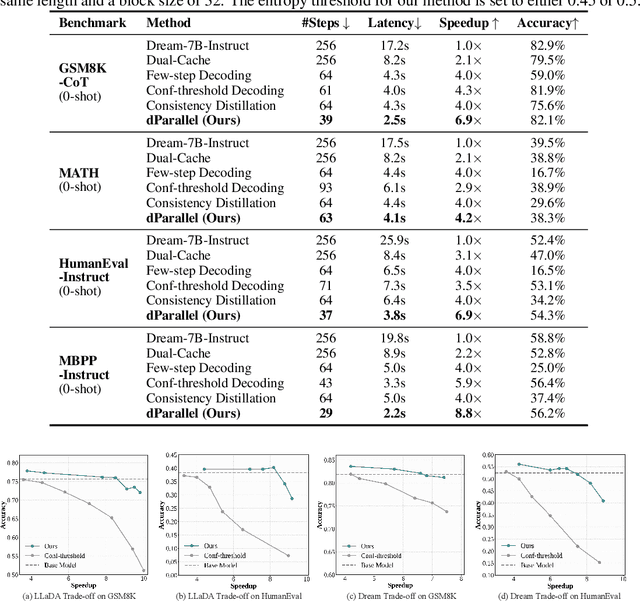
Diffusion large language models (dLLMs) have recently drawn considerable attention within the research community as a promising alternative to autoregressive generation, offering parallel token prediction and lower inference latency. Yet, their parallel decoding potential remains largely underexplored, as existing open-source models still require nearly token-length decoding steps to ensure performance. To address this, we introduce dParallel, a simple and effective method that unlocks the inherent parallelism of dLLMs for fast sampling. We identify that the key bottleneck to parallel decoding arises from the sequential certainty convergence for masked tokens. Building on this insight, we introduce the core of our approach: certainty-forcing distillation, a novel training strategy that distills the model to follow its original sampling trajectories while enforcing it to achieve high certainty on masked tokens more rapidly and in parallel. Extensive experiments across various benchmarks demonstrate that our method can dramatically reduce the number of decoding steps while maintaining performance. When applied to the LLaDA-8B-Instruct model, dParallel reduces decoding steps from 256 to 30 on GSM8K, achieving an 8.5x speedup without performance degradation. On the MBPP benchmark, it cuts decoding steps from 256 to 24, resulting in a 10.5x speedup while maintaining accuracy. Our code is available at https://github.com/czg1225/dParallel
Don't Forget the Nonlinearity: Unlocking Activation Functions in Efficient Fine-Tuning
Sep 16, 2025Existing parameter-efficient fine-tuning (PEFT) methods primarily adapt weight matrices while keeping activation functions fixed. We introduce \textbf{NoRA}, the first PEFT framework that directly adapts nonlinear activation functions in pretrained transformer-based models. NoRA replaces fixed activations with learnable rational functions and applies structured low-rank updates to numerator and denominator coefficients, with a group-wise design that localizes adaptation and improves stability at minimal cost. On vision transformers trained on CIFAR-10 and CIFAR-100, NoRA matches or exceeds full fine-tuning while updating only 0.4\% of parameters (0.02M), achieving accuracy gains of +0.17\% and +0.27\%. When combined with LoRA (\textbf{NoRA++}), it outperforms LoRA and DoRA under matched training budgets by adding fewer trainable parameters. On LLaMA3-8B instruction tuning, NoRA++ consistently improves generation quality, yielding average MMLU gains of +0.3\%--0.8\%, including +1.6\% on STEM (Alpaca) and +1.3\% on OpenOrca. We further show that NoRA constrains adaptation to a low-dimensional functional subspace, implicitly regularizing update magnitude and direction. These results establish activation-space tuning as a complementary and highly parameter-efficient alternative to weight-based PEFT, positioning activation functions as first-class objects for model adaptation.
ConciseHint: Boosting Efficient Reasoning via Continuous Concise Hints during Generation
Jun 24, 2025Recent advancements in large reasoning models (LRMs) like DeepSeek-R1 and OpenAI o1 series have achieved notable performance enhancements on complex reasoning tasks by scaling up the generation length by Chain-of-Thought (CoT). However, an emerging issue is their inclination to produce excessively verbose reasoning processes, leading to the inefficiency problem. Existing literature on improving efficiency mainly adheres to the before-reasoning paradigms such as prompting and reasoning or fine-tuning and reasoning, but ignores the promising direction of directly encouraging the model to speak concisely by intervening during the generation of reasoning. In order to fill the blank, we propose a framework dubbed ConciseHint, which continuously encourages the reasoning model to speak concisely by injecting the textual hint (manually designed or trained on the concise data) during the token generation of the reasoning process. Besides, ConciseHint is adaptive to the complexity of the query by adaptively adjusting the hint intensity, which ensures it will not undermine model performance. Experiments on the state-of-the-art LRMs, including DeepSeek-R1 and Qwen-3 series, demonstrate that our method can effectively produce concise reasoning processes while maintaining performance well. For instance, we achieve a reduction ratio of 65\% for the reasoning length on GSM8K benchmark with Qwen-3 4B with nearly no accuracy loss.
Control and Realism: Best of Both Worlds in Layout-to-Image without Training
Jun 18, 2025Layout-to-Image generation aims to create complex scenes with precise control over the placement and arrangement of subjects. Existing works have demonstrated that pre-trained Text-to-Image diffusion models can achieve this goal without training on any specific data; however, they often face challenges with imprecise localization and unrealistic artifacts. Focusing on these drawbacks, we propose a novel training-free method, WinWinLay. At its core, WinWinLay presents two key strategies, Non-local Attention Energy Function and Adaptive Update, that collaboratively enhance control precision and realism. On one hand, we theoretically demonstrate that the commonly used attention energy function introduces inherent spatial distribution biases, hindering objects from being uniformly aligned with layout instructions. To overcome this issue, non-local attention prior is explored to redistribute attention scores, facilitating objects to better conform to the specified spatial conditions. On the other hand, we identify that the vanilla backpropagation update rule can cause deviations from the pre-trained domain, leading to out-of-distribution artifacts. We accordingly introduce a Langevin dynamics-based adaptive update scheme as a remedy that promotes in-domain updating while respecting layout constraints. Extensive experiments demonstrate that WinWinLay excels in controlling element placement and achieving photorealistic visual fidelity, outperforming the current state-of-the-art methods.
Discrete Diffusion in Large Language and Multimodal Models: A Survey
Jun 16, 2025In this work, we provide a systematic survey of Discrete Diffusion Language Models (dLLMs) and Discrete Diffusion Multimodal Language Models (dMLLMs). Unlike autoregressive (AR) models, dLLMs and dMLLMs adopt a multi-token, parallel decoding paradigm using full attention and a denoising-based generation strategy. This paradigm naturally enables parallel generation, fine-grained output controllability, and dynamic, response-aware perception. These capabilities are previously difficult to achieve with AR models. Recently, a growing number of industrial-scale proprietary d(M)LLMs, as well as a large number of open-source academic d(M)LLMs, have demonstrated performance comparable to their autoregressive counterparts, while achieving up to 10x acceleration in inference speed. The advancement of discrete diffusion LLMs and MLLMs has been largely driven by progress in two domains. The first is the development of autoregressive LLMs and MLLMs, which has accumulated vast amounts of data, benchmarks, and foundational infrastructure for training and inference. The second contributing domain is the evolution of the mathematical models underlying discrete diffusion. Together, these advancements have catalyzed a surge in dLLMs and dMLLMs research in early 2025. In this work, we present a comprehensive overview of the research in the dLLM and dMLLM domains. We trace the historical development of dLLMs and dMLLMs, formalize the underlying mathematical frameworks, and categorize representative models. We further analyze key techniques for training and inference, and summarize emerging applications across language, vision-language, and biological domains. We conclude by discussing future directions for research and deployment. Paper collection: https://github.com/LiQiiiii/DLLM-Survey