 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotEdit: Selective Region Editing in Diffusion Transformers
Dec 26, 2025Diffusion Transformer models have significantly advanced image editing by encoding conditional images and integrating them into transformer layers. However, most edits involve modifying only small regions, while current methods uniformly process and denoise all tokens at every timestep, causing redundant computation and potentially degrading unchanged areas. This raises a fundamental question: Is it truly necessary to regenerate every region during editing? To address this, we propose SpotEdit, a training-free diffusion editing framework that selectively updates only the modified regions. SpotEdit comprises two key components: SpotSelector identifies stable regions via perceptual similarity and skips their computation by reusing conditional image features; SpotFusion adaptively blends these features with edited tokens through a dynamic fusion mechanism, preserving contextual coherence and editing quality. By reducing unnecessary computation and maintaining high fidelity in unmodified areas, SpotEdit achieves efficient and precise image editing.
FreeSwim: Revisiting Sliding-Window Attention Mechanisms for Training-Free Ultra-High-Resolution Video Generation
Nov 18, 2025The quadratic time and memory complexity of the attention mechanism in modern Transformer based video generators makes end-to-end training for ultra high resolution videos prohibitively expensive. Motivated by this limitation, we introduce a training-free approach that leverages video Diffusion Transformers pretrained at their native scale to synthesize higher resolution videos without any additional training or adaptation. At the core of our method lies an inward sliding window attention mechanism, which originates from a key observation: maintaining each query token's training scale receptive field is crucial for preserving visual fidelity and detail. However, naive local window attention, unfortunately, often leads to repetitive content and exhibits a lack of global coherence in the generated results. To overcome this challenge, we devise a dual-path pipeline that backs up window attention with a novel cross-attention override strategy, enabling the semantic content produced by local attention to be guided by another branch with a full receptive field and, therefore, ensuring holistic consistency. Furthermore, to improve efficiency, we incorporate a cross-attention caching strategy for this branch to avoid the frequent computation of full 3D attention. Extensive experiments demonstrate that our method delivers ultra-high-resolution videos with fine-grained visual details and high efficiency in a training-free paradigm. Meanwhile, it achieves superior performance on VBench, even compared to training-based alternatives, with competitive or improved efficiency. Codes are available at: https://github.com/WillWu111/FreeSwim
Image Editing As Programs with Diffusion Models
Jun 04, 2025While diffusion models have achieved remarkable success in text-to-image generation, they encounter significant challenges with instruction-driven image editing. Our research highlights a key challenge: these models particularly struggle with structurally inconsistent edits that involve substantial layout changes. To mitigate this gap, we introduce Image Editing As Programs (IEAP), a unified image editing framework built upon the Diffusion Transformer (DiT) architecture. At its core, IEAP approaches instructional editing through a reductionist lens, decomposing complex editing instructions into sequences of atomic operations. Each operation is implemented via a lightweight adapter sharing the same DiT backbone and is specialized for a specific type of edit. Programmed by a vision-language model (VLM)-based agent, these operations collaboratively support arbitrary and structurally inconsistent transformations. By modularizing and sequencing edits in this way, IEAP generalizes robustly across a wide range of editing tasks, from simple adjustments to substantial structural changes. Extensive experiments demonstrate that IEAP significantly outperforms state-of-the-art methods on standard benchmarks across various editing scenarios. In these evaluations, our framework delivers superior accuracy and semantic fidelity, particularly for complex, multi-step instructions. Codes are available at https://github.com/YujiaHu1109/IEAP.
Minute-Long Videos with Dual Parallelisms
May 29, 2025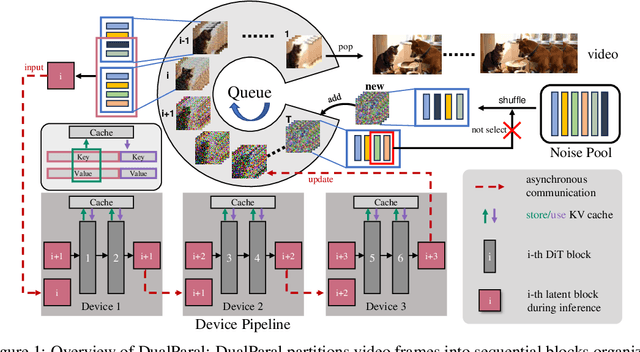



Diffusion Transformer (DiT)-based video diffusion models generate high-quality videos at scale but incur prohibitive processing latency and memory costs for long videos. To address this, we propose a novel distributed inference strategy, termed DualParal. The core idea is that, instead of generating an entire video on a single GPU, we parallelize both temporal frames and model layers across GPUs. However, a naive implementation of this division faces a key limitation: since diffusion models require synchronized noise levels across frames, this implementation leads to the serialization of original parallelisms. We leverage a block-wise denoising scheme to handle this. Namely, we process a sequence of frame blocks through the pipeline with progressively decreasing noise levels. Each GPU handles a specific block and layer subset while passing previous results to the next GPU, enabling asynchronous computation and communication. To further optimize performance, we incorporate two key enhancements. Firstly, a feature cache is implemented on each GPU to store and reuse features from the prior block as context, minimizing inter-GPU communication and redundant computation. Secondly, we employ a coordinated noise initialization strategy, ensuring globally consistent temporal dynamics by sharing initial noise patterns across GPUs without extra resource costs. Together, these enable fast, artifact-free, and infinitely long video generation. Applied to the latest diffusion transformer video generator, our method efficiently produces 1,025-frame videos with up to 6.54$\times$ lower latency and 1.48$\times$ lower memory cost on 8$\times$RTX 4090 GPUs.
Ultra-Resolution Adaptation with Ease
Mar 20, 2025Text-to-image diffusion models have achieved remarkable progress in recent years. However, training models for high-resolution image generation remains challenging, particularly when training data and computational resources are limited. In this paper, we explore this practical problem from two key perspectives: data and parameter efficiency, and propose a set of key guidelines for ultra-resolution adaptation termed \emph{URAE}. For data efficiency, we theoretically and empirically demonstrate that synthetic data generated by some teacher models can significantly promote training convergence. For parameter efficiency, we find that tuning minor components of the weight matrices outperforms widely-used low-rank adapters when synthetic data are unavailable, offering substantial performance gains while maintaining efficiency. Additionally, for models leveraging guidance distillation, such as FLUX, we show that disabling classifier-free guidance, \textit{i.e.}, setting the guidance scale to 1 during adaptation, is crucial for satisfactory performance. Extensive experiments validate that URAE achieves comparable 2K-generation performance to state-of-the-art closed-source models like FLUX1.1 [Pro] Ultra with only 3K samples and 2K iterations, while setting new benchmarks for 4K-resolution generation. Codes are available \href{https://github.com/Huage001/URAE}{here}.
OminiControl2: Efficient Conditioning for Diffusion Transformers
Mar 11, 2025Fine-grained control of text-to-image diffusion transformer models (DiT) remains a critical challenge for practical deployment. While recent advances such as OminiControl and others have enabled a controllable generation of diverse control signals, these methods face significant computational inefficiency when handling long conditional inputs. We present OminiControl2, an efficient framework that achieves efficient image-conditional image generation. OminiControl2 introduces two key innovations: (1) a dynamic compression strategy that streamlines conditional inputs by preserving only the most semantically relevant tokens during generation, and (2) a conditional feature reuse mechanism that computes condition token features only once and reuses them across denoising steps. These architectural improvements preserve the original framework's parameter efficiency and multi-modal versatility while dramatically reducing computational costs. Our experiments demonstrate that OminiControl2 reduces conditional processing overhead by over 90% compared to its predecessor, achieving an overall 5.9$\times$ speedup in multi-conditional generation scenarios. This efficiency enables the practical implementation of complex, multi-modal control for high-quality image synthesis with DiT models.
CLEAR: Conv-Like Linearization Revs Pre-Trained Diffusion Transformers Up
Dec 20, 2024Diffusion Transformers (DiT) have become a leading architecture in image generation. However, the quadratic complexity of attention mechanisms, which are responsible for modeling token-wise relationships, results in significant latency when generating high-resolution images. To address this issue, we aim at a linear attention mechanism in this paper that reduces the complexity of pre-trained DiTs to linear. We begin our exploration with a comprehensive summary of existing efficient attention mechanisms and identify four key factors crucial for successful linearization of pre-trained DiTs: locality, formulation consistency, high-rank attention maps, and feature integrity. Based on these insights, we introduce a convolution-like local attention strategy termed CLEAR, which limits feature interactions to a local window around each query token, and thus achieves linear complexity. Our experiments indicate that, by fine-tuning the attention layer on merely 10K self-generated samples for 10K iterations, we can effectively transfer knowledge from a pre-trained DiT to a student model with linear complexity, yielding results comparable to the teacher model. Simultaneously, it reduces attention computations by 99.5% and accelerates generation by 6.3 times for generating 8K-resolution images. Furthermore, we investigate favorable properties in the distilled attention layers, such as zero-shot generalization cross various models and plugins, and improved support for multi-GPU parallel inference. Models and codes are available here: https://github.com/Huage001/CLEAR.
MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation
Dec 05, 2024



Recent advances in video diffusion models have unlocked new potential for realistic audio-driven talking video generation. However, achieving seamless audio-lip synchronization, maintaining long-term identity consistency, and producing natural, audio-aligned expressions in generated talking videos remain significant challenges. To address these challenges, we propose Memory-guided EMOtion-aware diffusion (MEMO), an end-to-end audio-driven portrait animation approach to generate identity-consistent and expressive talking videos. Our approach is built around two key modules: (1) a memory-guided temporal module, which enhances long-term identity consistency and motion smoothness by developing memory states to store information from a longer past context to guide temporal modeling via linear attention; and (2) an emotion-aware audio module, which replaces traditional cross attention with multi-modal attention to enhance audio-video interaction, while detecting emotions from audio to refine facial expressions via emotion adaptive layer norm. Extensive quantitative and qualitative results demonstrate that MEMO generates more realistic talking videos across diverse image and audio types, outperforming state-of-the-art methods in overall quality, audio-lip synchronization, identity consistency, and expression-emotion alignment.
OminiControl: Minimal and Universal Control for Diffusion Transformer
Nov 25, 2024



In this paper, we introduce OminiControl, a highly versatile and parameter-efficient framework that integrates image conditions into pre-trained Diffusion Transformer (DiT) models. At its core, OminiControl leverages a parameter reuse mechanism, enabling the DiT to encode image conditions using itself as a powerful backbone and process them with its flexible multi-modal attention processors. Unlike existing methods, which rely heavily on additional encoder modules with complex architectures, OminiControl (1) effectively and efficiently incorporates injected image conditions with only ~0.1% additional parameters, and (2) addresses a wide range of image conditioning tasks in a unified manner, including subject-driven generation and spatially-aligned conditions such as edges, depth, and more. Remarkably, these capabilities are achieved by training on images generated by the DiT itself, which is particularly beneficial for subject-driven generation. Extensive evaluations demonstrate that OminiControl outperforms existing UNet-based and DiT-adapted models in both subject-driven and spatially-aligned conditional generation. Additionally, we release our training dataset, Subjects200K, a diverse collection of over 200,000 identity-consistent images, along with an efficient data synthesis pipeline to advance research in subject-consistent generation.
LinFusion: 1 GPU, 1 Minute, 16K Image
Sep 03, 2024
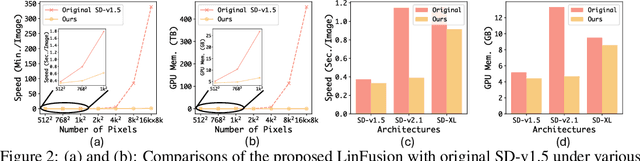


Modern diffusion models, particularly those utilizing a Transformer-based UNet for denoising, rely heavily on self-attention operations to manage complex spatial relationships, thus achieving impressive generation performance. However, this existing paradigm faces significant challenges in generating high-resolution visual content due to its quadratic time and memory complexity with respect to the number of spatial tokens. To address this limitation, we aim at a novel linear attention mechanism as an alternative in this paper. Specifically, we begin our exploration from recently introduced models with linear complexity, e.g., Mamba, Mamba2, and Gated Linear Attention, and identify two key features-attention normalization and non-causal inference-that enhance high-resolution visual generation performance. Building on these insights, we introduce a generalized linear attention paradigm, which serves as a low-rank approximation of a wide spectrum of popular linear token mixers. To save the training cost and better leverage pre-trained models, we initialize our models and distill the knowledge from pre-trained StableDiffusion (SD). We find that the distilled model, termed LinFusion, achieves performance on par with or superior to the original SD after only modest training, while significantly reducing time and memory complexity. Extensive experiments on SD-v1.5, SD-v2.1, and SD-XL demonstrate that LinFusion delivers satisfactory zero-shot cross-resolution generation performance, generating high-resolution images like 16K resolution. Moreover, it is highly compatible with pre-trained SD components, such as ControlNet and IP-Adapter, requiring no adaptation efforts. Codes are available at https://github.com/Huage001/LinFusion.