 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations
Feb 05, 2026High-quality kernel is critical for scalable AI systems, and enabling LLMs to generate such code would advance AI development. However, training LLMs for this task requires sufficient data, a robust environment, and the process is often vulnerable to reward hacking and lazy optimization. In these cases, models may hack training rewards and prioritize trivial correctness over meaningful speedup. In this paper, we systematically study reinforcement learning (RL) for kernel generation. We first design KernelGYM, a robust distributed GPU environment that supports reward hacking check, data collection from multi-turn interactions and long-term RL training. Building on KernelGYM, we investigate effective multi-turn RL methods and identify a biased policy gradient issue caused by self-inclusion in GRPO. To solve this, we propose Turn-level Reinforce-Leave-One-Out (TRLOO) to provide unbiased advantage estimation for multi-turn RL. To alleviate lazy optimization, we incorporate mismatch correction for training stability and introduce Profiling-based Rewards (PR) and Profiling-based Rejection Sampling (PRS) to overcome the issue. The trained model, Dr.Kernel-14B, reaches performance competitive with Claude-4.5-Sonnet in Kernelbench. Finally, we study sequential test-time scaling for Dr.Kernel-14B. On the KernelBench Level-2 subset, 31.6% of the generated kernels achieve at least a 1.2x speedup over the Torch reference, surpassing Claude-4.5-Sonnet (26.7%) and GPT-5 (28.6%). When selecting the best candidate across all turns, this 1.2x speedup rate further increases to 47.8%. All resources, including environment, training code, models, and dataset, are included in https://www.github.com/hkust-nlp/KernelGYM.
Towards Efficient Online Tuning of VLM Agents via Counterfactual Soft Reinforcement Learning
May 01, 2025Online fine-tuning vision-language model (VLM) agents with reinforcement learning (RL) has shown promise for equipping agents with multi-step, goal-oriented capabilities in dynamic environments. However, their open-ended textual action space and non-end-to-end nature of action generation present significant challenges to effective online exploration in RL, e.g., explosion of the exploration space. We propose a novel online fine-tuning method, Counterfactual Soft Reinforcement Learning (CoSo), better suited to the textual output space of VLM agents. Compared to prior methods that assign uniform uncertainty to all tokens, CoSo leverages counterfactual reasoning to dynamically assess the causal influence of individual tokens on post-processed actions. By prioritizing the exploration of action-critical tokens while reducing the impact of semantically redundant or low-impact tokens, CoSo enables a more targeted and efficient online rollout process. We provide theoretical analysis proving CoSo's convergence and policy improvement guarantees, and extensive empirical evaluations supporting CoSo's effectiveness. Our results across a diverse set of agent tasks, including Android device control, card gaming, and embodied AI, highlight its remarkable ability to enhance exploration efficiency and deliver consistent performance gains. The code is available at https://github.com/langfengQ/CoSo.
MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation
Dec 05, 2024



Recent advances in video diffusion models have unlocked new potential for realistic audio-driven talking video generation. However, achieving seamless audio-lip synchronization, maintaining long-term identity consistency, and producing natural, audio-aligned expressions in generated talking videos remain significant challenges. To address these challenges, we propose Memory-guided EMOtion-aware diffusion (MEMO), an end-to-end audio-driven portrait animation approach to generate identity-consistent and expressive talking videos. Our approach is built around two key modules: (1) a memory-guided temporal module, which enhances long-term identity consistency and motion smoothness by developing memory states to store information from a longer past context to guide temporal modeling via linear attention; and (2) an emotion-aware audio module, which replaces traditional cross attention with multi-modal attention to enhance audio-video interaction, while detecting emotions from audio to refine facial expressions via emotion adaptive layer norm. Extensive quantitative and qualitative results demonstrate that MEMO generates more realistic talking videos across diverse image and audio types, outperforming state-of-the-art methods in overall quality, audio-lip synchronization, identity consistency, and expression-emotion alignment.
AgentStudio: A Toolkit for Building General Virtual Agents
Mar 26, 2024Creating autonomous virtual agents capable of using arbitrary software on any digital device remains a major challenge for artificial intelligence. Two key obstacles hinder progress: insufficient infrastructure for building virtual agents in real-world environments, and the need for in-the-wild evaluation of fundamental agent abilities. To address this, we introduce AgentStudio, an online, realistic, and multimodal toolkit that covers the entire lifecycle of agent development. This includes environment setups, data collection, agent evaluation, and visualization. The observation and action spaces are highly generic, supporting both function calling and human-computer interfaces. This versatility is further enhanced by AgentStudio's graphical user interfaces, which allow efficient development of datasets and benchmarks in real-world settings. To illustrate, we introduce a visual grounding dataset and a real-world benchmark suite, both created with our graphical interfaces. Furthermore, we present several actionable insights derived from AgentStudio, e.g., general visual grounding, open-ended tool creation, learning from videos, etc. We have open-sourced the environments, datasets, benchmarks, and interfaces to promote research towards developing general virtual agents for the future.
Towards General Computer Control: A Multimodal Agent for Red Dead Redemption II as a Case Study
Mar 07, 2024Despite the success in specific tasks and scenarios, existing foundation agents, empowered by large models (LMs) and advanced tools, still cannot generalize to different scenarios, mainly due to dramatic differences in the observations and actions across scenarios. In this work, we propose the General Computer Control (GCC) setting: building foundation agents that can master any computer task by taking only screen images (and possibly audio) of the computer as input, and producing keyboard and mouse operations as output, similar to human-computer interaction. The main challenges of achieving GCC are: 1) the multimodal observations for decision-making, 2) the requirements of accurate control of keyboard and mouse, 3) the need for long-term memory and reasoning, and 4) the abilities of efficient exploration and self-improvement. To target GCC, we introduce Cradle, an agent framework with six main modules, including: 1) information gathering to extract multi-modality information, 2) self-reflection to rethink past experiences, 3) task inference to choose the best next task, 4) skill curation for generating and updating relevant skills for given tasks, 5) action planning to generate specific operations for keyboard and mouse control, and 6) memory for storage and retrieval of past experiences and known skills. To demonstrate the capabilities of generalization and self-improvement of Cradle, we deploy it in the complex AAA game Red Dead Redemption II, serving as a preliminary attempt towards GCC with a challenging target. To our best knowledge, our work is the first to enable LMM-based agents to follow the main storyline and finish real missions in complex AAA games, with minimal reliance on prior knowledge or resources. The project website is at https://baai-agents.github.io/Cradle/.
A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
Feb 29, 2024



Financial trading is a crucial component of the markets, informed by a multimodal information landscape encompassing news, prices, and Kline charts, and encompasses diverse tasks such as quantitative trading and high-frequency trading with various assets. While advanced AI techniques like deep learning and reinforcement learning are extensively utilized in finance, their application in financial trading tasks often faces challenges due to inadequate handling of multimodal data and limited generalizability across various tasks. To address these challenges, we present FinAgent, a multimodal foundational agent with tool augmentation for financial trading. FinAgent's market intelligence module processes a diverse range of data-numerical, textual, and visual-to accurately analyze the financial market. Its unique dual-level reflection module not only enables rapid adaptation to market dynamics but also incorporates a diversified memory retrieval system, enhancing the agent's ability to learn from historical data and improve decision-making processes. The agent's emphasis on reasoning for actions fosters trust in its financial decisions. Moreover, FinAgent integrates established trading strategies and expert insights, ensuring that its trading approaches are both data-driven and rooted in sound financial principles. With comprehensive experiments on 6 financial datasets, including stocks and Crypto, FinAgent significantly outperforms 9 state-of-the-art baselines in terms of 6 financial metrics with over 36% average improvement on profit. Specifically, a 92.27% return (a 84.39% relative improvement) is achieved on one dataset. Notably, FinAgent is the first advanced multimodal foundation agent designed for financial trading tasks.
True Knowledge Comes from Practice: Aligning LLMs with Embodied Environments via Reinforcement Learning
Jan 25, 2024

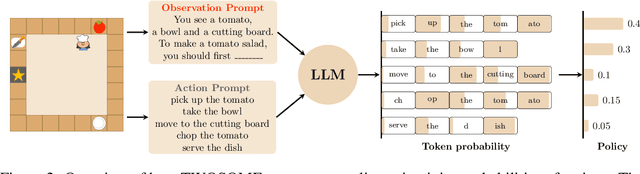

Despite the impressive performance across numerous tasks, large language models (LLMs) often fail in solving simple decision-making tasks due to the misalignment of the knowledge in LLMs with environments. On the contrary, reinforcement learning (RL) agents learn policies from scratch, which makes them always align with environments but difficult to incorporate prior knowledge for efficient explorations. To narrow the gap, we propose TWOSOME, a novel general online framework that deploys LLMs as decision-making agents to efficiently interact and align with embodied environments via RL without requiring any prepared datasets or prior knowledge of the environments. Firstly, we query the joint probabilities of each valid action with LLMs to form behavior policies. Then, to enhance the stability and robustness of the policies, we propose two normalization methods and summarize four prompt design principles. Finally, we design a novel parameter-efficient training architecture where the actor and critic share one frozen LLM equipped with low-rank adapters (LoRA) updated by PPO. We conduct extensive experiments to evaluate TWOSOME. i) TWOSOME exhibits significantly better sample efficiency and performance compared to the conventional RL method, PPO, and prompt tuning method, SayCan, in both classical decision-making environment, Overcooked, and simulated household environment, VirtualHome. ii) Benefiting from LLMs' open-vocabulary feature, TWOSOME shows superior generalization ability to unseen tasks. iii) Under our framework, there is no significant loss of the LLMs' original ability during online PPO finetuning.
Synapse: Leveraging Few-Shot Exemplars for Human-Level Computer Control
Jun 13, 2023



This paper investigates the design of few-shot exemplars for computer automation through prompting large language models (LLMs). While previous prompting approaches focus on self-correction, we find that well-structured exemplars alone are sufficient for human-level performance. We present Synapse, an in-context computer control agent demonstrating human-level performance on the MiniWob++ benchmark. Synapse consists of three main components: 1) state-conditional decomposition, which divides demonstrations into exemplar sets based on the agent's need for new environment states, enabling temporal abstraction; 2) structured prompting, which filters states and reformulates task descriptions for each set to improve planning correctness; and 3) exemplar retrieval, which associates incoming tasks with corresponding exemplars in an exemplar database for multi-task adaptation and generalization. Synapse overcomes context length limits, reduces errors in multi-step control, and allows for more exemplars within the context. Importantly, Synapse complements existing prompting approaches that enhance LLMs' reasoning and planning abilities. Synapse outperforms previous methods, including behavioral cloning, reinforcement learning, finetuning, and prompting, with an average success rate of $98.5\%$ across 63 tasks in MiniWob++. Notably, Synapse relies on exemplars from only 47 tasks, demonstrating effective generalization to novel tasks. Our results highlight the potential of in-context learning to advance the integration of LLMs into practical tool automation.
Towards Skilled Population Curriculum for Multi-Agent Reinforcement Learning
Feb 07, 2023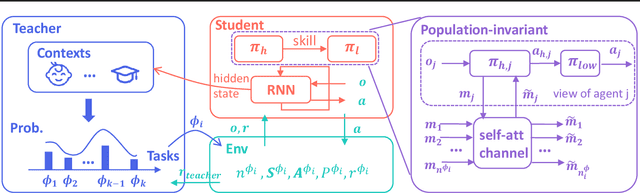


Recent advances in multi-agent reinforcement learning (MARL) allow agents to coordinate their behaviors in complex environments. However, common MARL algorithms still suffer from scalability and sparse reward issues. One promising approach to resolving them is automatic curriculum learning (ACL). ACL involves a student (curriculum learner) training on tasks of increasing difficulty controlled by a teacher (curriculum generator). Despite its success, ACL's applicability is limited by (1) the lack of a general student framework for dealing with the varying number of agents across tasks and the sparse reward problem, and (2) the non-stationarity of the teacher's task due to ever-changing student strategies. As a remedy for ACL, we introduce a novel automatic curriculum learning framework, Skilled Population Curriculum (SPC), which adapts curriculum learning to multi-agent coordination. Specifically, we endow the student with population-invariant communication and a hierarchical skill set, allowing it to learn cooperation and behavior skills from distinct tasks with varying numbers of agents. In addition, we model the teacher as a contextual bandit conditioned by student policies, enabling a team of agents to change its size while still retaining previously acquired skills. We also analyze the inherent non-stationarity of this multi-agent automatic curriculum teaching problem and provide a corresponding regret bound. Empirical results show that our method improves the performance, scalability and sample efficiency in several MARL environments.