 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
FlashEvaluator: Expanding Search Space with Parallel Evaluation
Mar 03, 2026The Generator-Evaluator (G-E) framework, i.e., evaluating K sequences from a generator and selecting the top-ranked one according to evaluator scores, is a foundational paradigm in tasks such as Recommender Systems (RecSys) and Natural Language Processing (NLP). Traditional evaluators process sequences independently, suffering from two major limitations: (1) lack of explicit cross-sequence comparison, leading to suboptimal accuracy; (2) poor parallelization with linear complexity of O(K), resulting in inefficient resource utilization and negative impact on both throughput and latency. To address these challenges, we propose FlashEvaluator, which enables cross-sequence token information sharing and processes all sequences in a single forward pass. This yields sublinear computational complexity that improves the system's efficiency and supports direct inter-sequence comparisons that improve selection accuracy. The paper also provides theoretical proofs and extensive experiments on recommendation and NLP tasks, demonstrating clear advantages over conventional methods. Notably, FlashEvaluator has been deployed in online recommender system of Kuaishou, delivering substantial and sustained revenue gains in practice.
Safe and Efficient Online Convex Optimization with Linear Budget Constraints and Partial Feedback
Dec 05, 2024
This paper studies online convex optimization with unknown linear budget constraints, where only the gradient information of the objective and the bandit feedback of constraint functions are observed. We propose a safe and efficient Lyapunov-optimization algorithm (SELO) that can achieve an $O(\sqrt{T})$ regret and zero cumulative constraint violation. The result also implies SELO achieves $O(\sqrt{T})$ regret when the budget is hard and not allowed to be violated. The proposed algorithm is computationally efficient as it resembles a primal-dual algorithm where the primal problem is an unconstrained, strongly convex and smooth problem, and the dual problem has a simple gradient-type update. The algorithm and theory are further justified in a simulated application of energy-efficient task processing in distributed data centers.
True Knowledge Comes from Practice: Aligning LLMs with Embodied Environments via Reinforcement Learning
Jan 25, 2024

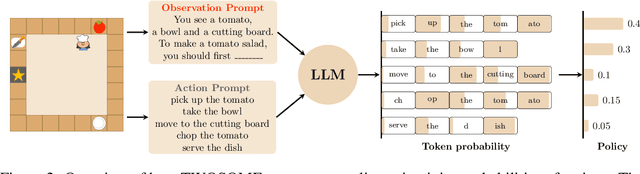

Despite the impressive performance across numerous tasks, large language models (LLMs) often fail in solving simple decision-making tasks due to the misalignment of the knowledge in LLMs with environments. On the contrary, reinforcement learning (RL) agents learn policies from scratch, which makes them always align with environments but difficult to incorporate prior knowledge for efficient explorations. To narrow the gap, we propose TWOSOME, a novel general online framework that deploys LLMs as decision-making agents to efficiently interact and align with embodied environments via RL without requiring any prepared datasets or prior knowledge of the environments. Firstly, we query the joint probabilities of each valid action with LLMs to form behavior policies. Then, to enhance the stability and robustness of the policies, we propose two normalization methods and summarize four prompt design principles. Finally, we design a novel parameter-efficient training architecture where the actor and critic share one frozen LLM equipped with low-rank adapters (LoRA) updated by PPO. We conduct extensive experiments to evaluate TWOSOME. i) TWOSOME exhibits significantly better sample efficiency and performance compared to the conventional RL method, PPO, and prompt tuning method, SayCan, in both classical decision-making environment, Overcooked, and simulated household environment, VirtualHome. ii) Benefiting from LLMs' open-vocabulary feature, TWOSOME shows superior generalization ability to unseen tasks. iii) Under our framework, there is no significant loss of the LLMs' original ability during online PPO finetuning.
Adaptive Value Decomposition with Greedy Marginal Contribution Computation for Cooperative Multi-Agent Reinforcement Learning
Feb 14, 2023



Real-world cooperation often requires intensive coordination among agents simultaneously. This task has been extensively studied within the framework of cooperative multi-agent reinforcement learning (MARL), and value decomposition methods are among those cutting-edge solutions. However, traditional methods that learn the value function as a monotonic mixing of per-agent utilities cannot solve the tasks with non-monotonic returns. This hinders their application in generic scenarios. Recent methods tackle this problem from the perspective of implicit credit assignment by learning value functions with complete expressiveness or using additional structures to improve cooperation. However, they are either difficult to learn due to large joint action spaces or insufficient to capture the complicated interactions among agents which are essential to solving tasks with non-monotonic returns. To address these problems, we propose a novel explicit credit assignment method to address the non-monotonic problem. Our method, Adaptive Value decomposition with Greedy Marginal contribution (AVGM), is based on an adaptive value decomposition that learns the cooperative value of a group of dynamically changing agents. We first illustrate that the proposed value decomposition can consider the complicated interactions among agents and is feasible to learn in large-scale scenarios. Then, our method uses a greedy marginal contribution computed from the value decomposition as an individual credit to incentivize agents to learn the optimal cooperative policy. We further extend the module with an action encoder to guarantee the linear time complexity for computing the greedy marginal contribution. Experimental results demonstrate that our method achieves significant performance improvements in several non-monotonic domains.
One-shot Face Reenactment Using Appearance Adaptive Normalization
Feb 20, 2021
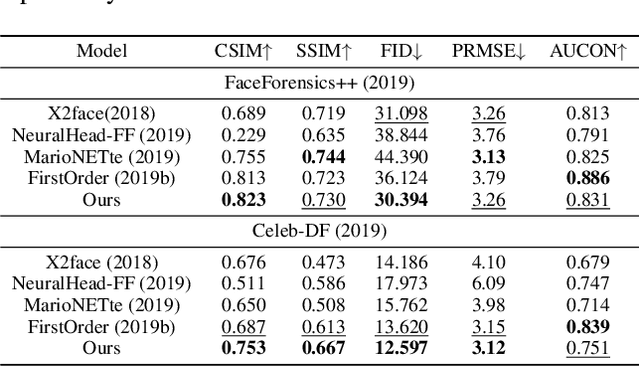
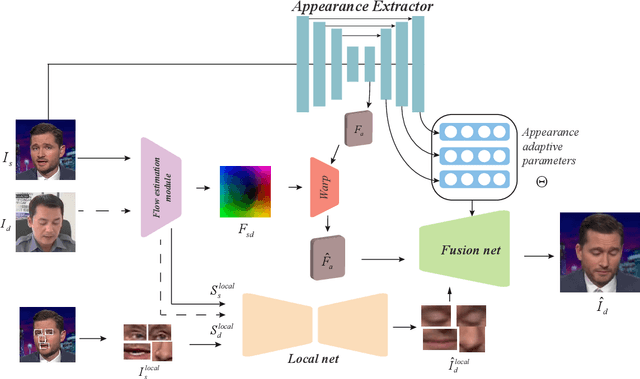
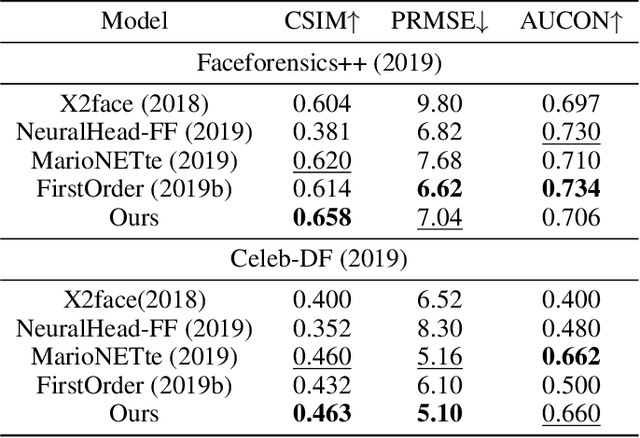
The paper proposes a novel generative adversarial network for one-shot face reenactment, which can animate a single face image to a different pose-and-expression (provided by a driving image) while keeping its original appearance. The core of our network is a novel mechanism called appearance adaptive normalization, which can effectively integrate the appearance information from the input image into our face generator by modulating the feature maps of the generator using the learned adaptive parameters. Furthermore, we specially design a local net to reenact the local facial components (i.e., eyes, nose and mouth) first, which is a much easier task for the network to learn and can in turn provide explicit anchors to guide our face generator to learn the global appearance and pose-and-expression. Extensive quantitative and qualitative experiments demonstrate the significant efficacy of our model compared with prior one-shot methods.
HILONet: Hierarchical Imitation Learning from Non-Aligned Observations
Nov 05, 2020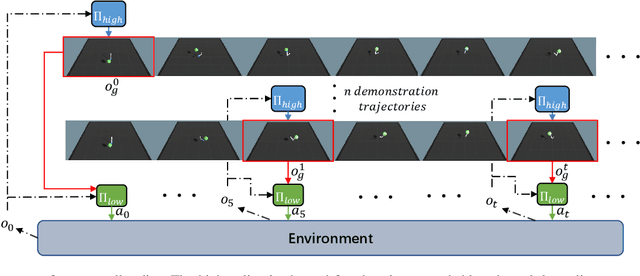

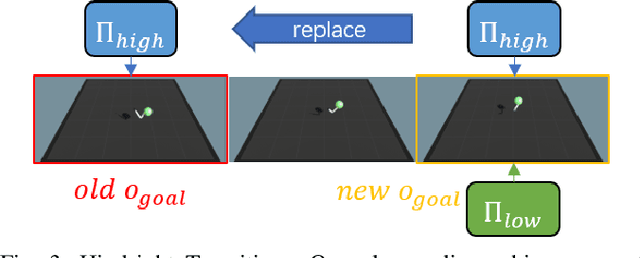
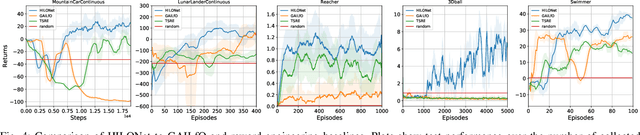
It is challenging learning from demonstrated observation-only trajectories in a non-time-aligned environment because most imitation learning methods aim to imitate experts by following the demonstration step-by-step. However, aligned demonstrations are seldom obtainable in real-world scenarios. In this work, we propose a new imitation learning approach called Hierarchical Imitation Learning from Observation(HILONet), which adopts a hierarchical structure to choose feasible sub-goals from demonstrated observations dynamically. Our method can solve all kinds of tasks by achieving these sub-goals, whether it has a single goal position or not. We also present three different ways to increase sample efficiency in the hierarchical structure. We conduct extensive experiments using several environments. The results show the improvement in both performance and learning efficiency.
Moving Forward in Formation: A Decentralized Hierarchical Learning Approach to Multi-Agent Moving Together
Nov 04, 2020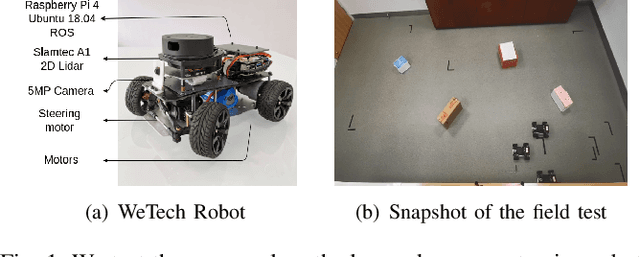
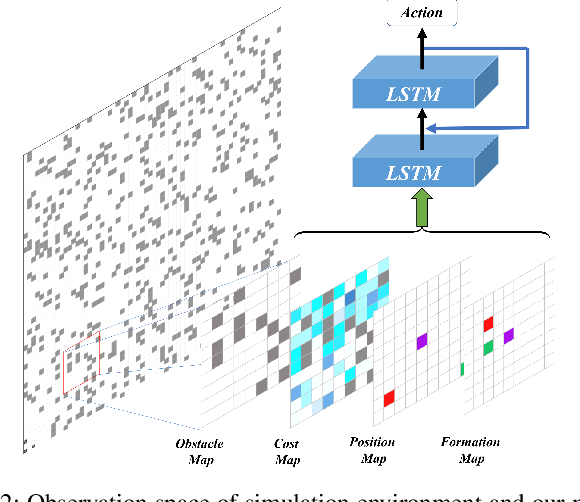
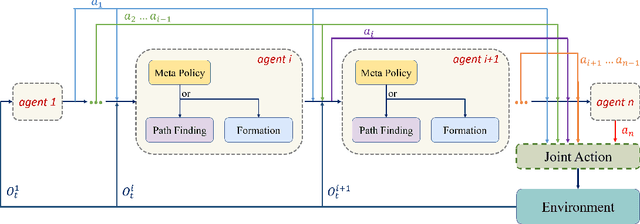
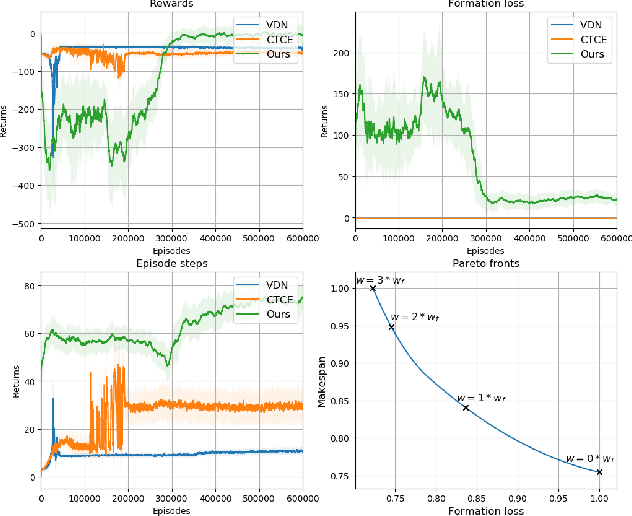
Multi-agent path finding in formation has many potential real-world applications like mobile warehouse robots. However, previous multi-agent path finding (MAPF) methods hardly take formation into consideration. Furthermore, they are usually centralized planners and require the whole state of the environment. Other decentralized partially observable approaches to MAPF are reinforcement learning (RL) methods. However, these RL methods encounter difficulties when learning path finding and formation problem at the same time. In this paper, we propose a novel decentralized partially observable RL algorithm that uses a hierarchical structure to decompose the multi objective task into unrelated ones. It also calculates a theoretical weight that makes every task reward has equal influence on the final RL value function. Additionally, we introduce a communication method that helps agents cooperate with each other. Experiments in simulation show that our method outperforms other end-to-end RL methods and our method can naturally scale to large world sizes where centralized planner struggles. We also deploy and validate our method in a real world scenario.