 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenGuanDan: A Large-Scale Imperfect Information Game Benchmark
Jan 31, 2026The advancement of data-driven artificial intelligence (AI), particularly machine learning, heavily depends on large-scale benchmarks. Despite remarkable progress across domains ranging from pattern recognition to intelligent decision-making in recent decades, exemplified by breakthroughs in board games, card games, and electronic sports games, there remains a pressing need for more challenging benchmarks to drive further research. To this end, this paper proposes OpenGuanDan, a novel benchmark that enables both efficient simulation of GuanDan (a popular four-player, multi-round Chinese card game) and comprehensive evaluation of both learning-based and rule-based GuanDan AI agents. OpenGuanDan poses a suite of nontrivial challenges, including imperfect information, large-scale information set and action spaces, a mixed learning objective involving cooperation and competition, long-horizon decision-making, variable action spaces, and dynamic team composition. These characteristics make it a demanding testbed for existing intelligent decision-making methods. Moreover, the independent API for each player allows human-AI interactions and supports integration with large language models. Empirically, we conduct two types of evaluations: (1) pairwise competitions among all GuanDan AI agents, and (2) human-AI matchups. Experimental results demonstrate that while current learning-based agents substantially outperform rule-based counterparts, they still fall short of achieving superhuman performance, underscoring the need for continued research in multi-agent intelligent decision-making domain. The project is publicly available at https://github.com/GameAI-NJUPT/OpenGuanDan.
Norface: Improving Facial Expression Analysis by Identity Normalization
Jul 22, 2024



Facial Expression Analysis remains a challenging task due to unexpected task-irrelevant noise, such as identity, head pose, and background. To address this issue, this paper proposes a novel framework, called Norface, that is unified for both Action Unit (AU) analysis and Facial Emotion Recognition (FER) tasks. Norface consists of a normalization network and a classification network. First, the carefully designed normalization network struggles to directly remove the above task-irrelevant noise, by maintaining facial expression consistency but normalizing all original images to a common identity with consistent pose, and background. Then, these additional normalized images are fed into the classification network. Due to consistent identity and other factors (e.g. head pose, background, etc.), the normalized images enable the classification network to extract useful expression information more effectively. Additionally, the classification network incorporates a Mixture of Experts to refine the latent representation, including handling the input of facial representations and the output of multiple (AU or emotion) labels. Extensive experiments validate the carefully designed framework with the insight of identity normalization. The proposed method outperforms existing SOTA methods in multiple facial expression analysis tasks, including AU detection, AU intensity estimation, and FER tasks, as well as their cross-dataset tasks. For the normalized datasets and code please visit {https://norface-fea.github.io/}.
Bayesian Design Principles for Offline-to-Online Reinforcement Learning
May 31, 2024Offline reinforcement learning (RL) is crucial for real-world applications where exploration can be costly or unsafe. However, offline learned policies are often suboptimal, and further online fine-tuning is required. In this paper, we tackle the fundamental dilemma of offline-to-online fine-tuning: if the agent remains pessimistic, it may fail to learn a better policy, while if it becomes optimistic directly, performance may suffer from a sudden drop. We show that Bayesian design principles are crucial in solving such a dilemma. Instead of adopting optimistic or pessimistic policies, the agent should act in a way that matches its belief in optimal policies. Such a probability-matching agent can avoid a sudden performance drop while still being guaranteed to find the optimal policy. Based on our theoretical findings, we introduce a novel algorithm that outperforms existing methods on various benchmarks, demonstrating the efficacy of our approach. Overall, the proposed approach provides a new perspective on offline-to-online RL that has the potential to enable more effective learning from offline data.
vMFER: Von Mises-Fisher Experience Resampling Based on Uncertainty of Gradient Directions for Policy Improvement
May 14, 2024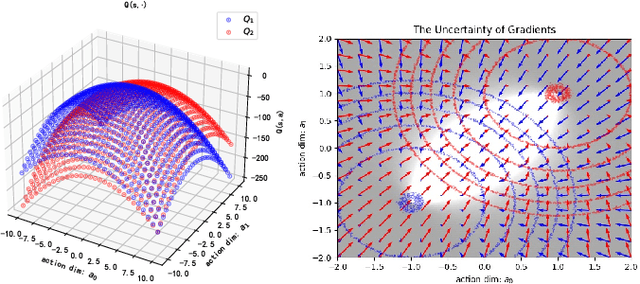

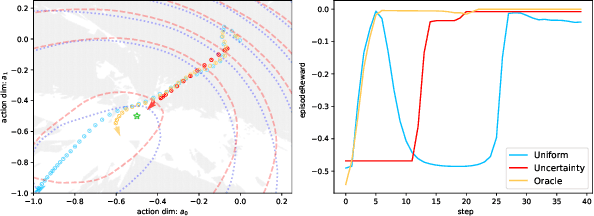
Reinforcement Learning (RL) is a widely employed technique in decision-making problems, encompassing two fundamental operations -- policy evaluation and policy improvement. Enhancing learning efficiency remains a key challenge in RL, with many efforts focused on using ensemble critics to boost policy evaluation efficiency. However, when using multiple critics, the actor in the policy improvement process can obtain different gradients. Previous studies have combined these gradients without considering their disagreements. Therefore, optimizing the policy improvement process is crucial to enhance learning efficiency. This study focuses on investigating the impact of gradient disagreements caused by ensemble critics on policy improvement. We introduce the concept of uncertainty of gradient directions as a means to measure the disagreement among gradients utilized in the policy improvement process. Through measuring the disagreement among gradients, we find that transitions with lower uncertainty of gradient directions are more reliable in the policy improvement process. Building on this analysis, we propose a method called von Mises-Fisher Experience Resampling (vMFER), which optimizes the policy improvement process by resampling transitions and assigning higher confidence to transitions with lower uncertainty of gradient directions. Our experiments demonstrate that vMFER significantly outperforms the benchmark and is particularly well-suited for ensemble structures in RL.
XRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques
Feb 20, 2024



Reinforcement Learning (RL) has demonstrated substantial potential across diverse fields, yet understanding its decision-making process, especially in real-world scenarios where rationality and safety are paramount, is an ongoing challenge. This paper delves in to Explainable RL (XRL), a subfield of Explainable AI (XAI) aimed at unravelling the complexities of RL models. Our focus rests on state-explaining techniques, a crucial subset within XRL methods, as they reveal the underlying factors influencing an agent's actions at any given time. Despite their significant role, the lack of a unified evaluation framework hinders assessment of their accuracy and effectiveness. To address this, we introduce XRL-Bench, a unified standardized benchmark tailored for the evaluation and comparison of XRL methods, encompassing three main modules: standard RL environments, explainers based on state importance, and standard evaluators. XRL-Bench supports both tabular and image data for state explanation. We also propose TabularSHAP, an innovative and competitive XRL method. We demonstrate the practical utility of TabularSHAP in real-world online gaming services and offer an open-source benchmark platform for the straightforward implementation and evaluation of XRL methods. Our contributions facilitate the continued progression of XRL technology.
AlignDiff: Aligning Diverse Human Preferences via Behavior-Customisable Diffusion Model
Oct 03, 2023Aligning agent behaviors with diverse human preferences remains a challenging problem in reinforcement learning (RL), owing to the inherent abstractness and mutability of human preferences. To address these issues, we propose AlignDiff, a novel framework that leverages RL from Human Feedback (RLHF) to quantify human preferences, covering abstractness, and utilizes them to guide diffusion planning for zero-shot behavior customizing, covering mutability. AlignDiff can accurately match user-customized behaviors and efficiently switch from one to another. To build the framework, we first establish the multi-perspective human feedback datasets, which contain comparisons for the attributes of diverse behaviors, and then train an attribute strength model to predict quantified relative strengths. After relabeling behavioral datasets with relative strengths, we proceed to train an attribute-conditioned diffusion model, which serves as a planner with the attribute strength model as a director for preference aligning at the inference phase. We evaluate AlignDiff on various locomotion tasks and demonstrate its superior performance on preference matching, switching, and covering compared to other baselines. Its capability of completing unseen downstream tasks under human instructions also showcases the promising potential for human-AI collaboration. More visualization videos are released on https://aligndiff.github.io/.
Prioritized Trajectory Replay: A Replay Memory for Data-driven Reinforcement Learning
Jun 27, 2023In recent years, data-driven reinforcement learning (RL), also known as offline RL, have gained significant attention. However, the role of data sampling techniques in offline RL has been overlooked despite its potential to enhance online RL performance. Recent research suggests applying sampling techniques directly to state-transitions does not consistently improve performance in offline RL. Therefore, in this study, we propose a memory technique, (Prioritized) Trajectory Replay (TR/PTR), which extends the sampling perspective to trajectories for more comprehensive information extraction from limited data. TR enhances learning efficiency by backward sampling of trajectories that optimizes the use of subsequent state information. Building on TR, we build the weighted critic target to avoid sampling unseen actions in offline training, and Prioritized Trajectory Replay (PTR) that enables more efficient trajectory sampling, prioritized by various trajectory priority metrics. We demonstrate the benefits of integrating TR and PTR with existing offline RL algorithms on D4RL. In summary, our research emphasizes the significance of trajectory-based data sampling techniques in enhancing the efficiency and performance of offline RL algorithms.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023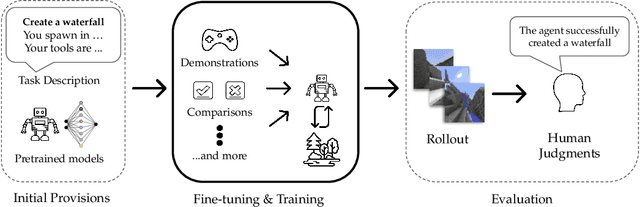

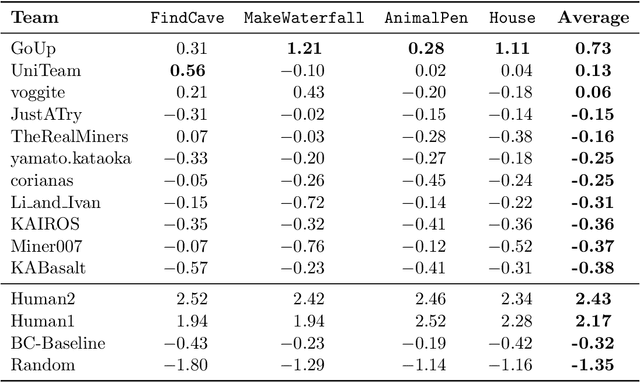
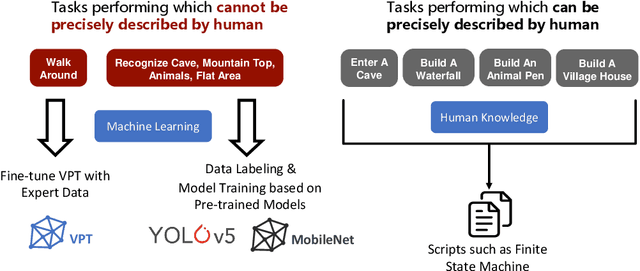
To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Adaptive Value Decomposition with Greedy Marginal Contribution Computation for Cooperative Multi-Agent Reinforcement Learning
Feb 14, 2023Real-world cooperation often requires intensive coordination among agents simultaneously. This task has been extensively studied within the framework of cooperative multi-agent reinforcement learning (MARL), and value decomposition methods are among those cutting-edge solutions. However, traditional methods that learn the value function as a monotonic mixing of per-agent utilities cannot solve the tasks with non-monotonic returns. This hinders their application in generic scenarios. Recent methods tackle this problem from the perspective of implicit credit assignment by learning value functions with complete expressiveness or using additional structures to improve cooperation. However, they are either difficult to learn due to large joint action spaces or insufficient to capture the complicated interactions among agents which are essential to solving tasks with non-monotonic returns. To address these problems, we propose a novel explicit credit assignment method to address the non-monotonic problem. Our method, Adaptive Value decomposition with Greedy Marginal contribution (AVGM), is based on an adaptive value decomposition that learns the cooperative value of a group of dynamically changing agents. We first illustrate that the proposed value decomposition can consider the complicated interactions among agents and is feasible to learn in large-scale scenarios. Then, our method uses a greedy marginal contribution computed from the value decomposition as an individual credit to incentivize agents to learn the optimal cooperative policy. We further extend the module with an action encoder to guarantee the linear time complexity for computing the greedy marginal contribution. Experimental results demonstrate that our method achieves significant performance improvements in several non-monotonic domains.
Towards Skilled Population Curriculum for Multi-Agent Reinforcement Learning
Feb 07, 2023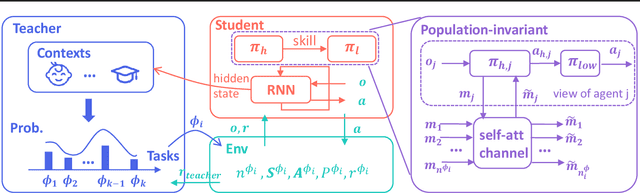

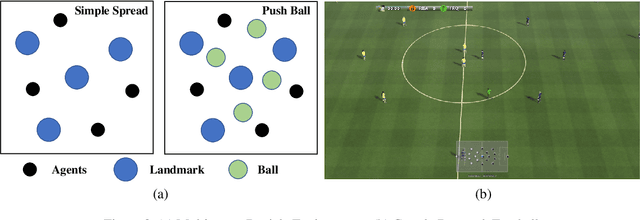

Recent advances in multi-agent reinforcement learning (MARL) allow agents to coordinate their behaviors in complex environments. However, common MARL algorithms still suffer from scalability and sparse reward issues. One promising approach to resolving them is automatic curriculum learning (ACL). ACL involves a student (curriculum learner) training on tasks of increasing difficulty controlled by a teacher (curriculum generator). Despite its success, ACL's applicability is limited by (1) the lack of a general student framework for dealing with the varying number of agents across tasks and the sparse reward problem, and (2) the non-stationarity of the teacher's task due to ever-changing student strategies. As a remedy for ACL, we introduce a novel automatic curriculum learning framework, Skilled Population Curriculum (SPC), which adapts curriculum learning to multi-agent coordination. Specifically, we endow the student with population-invariant communication and a hierarchical skill set, allowing it to learn cooperation and behavior skills from distinct tasks with varying numbers of agents. In addition, we model the teacher as a contextual bandit conditioned by student policies, enabling a team of agents to change its size while still retaining previously acquired skills. We also analyze the inherent non-stationarity of this multi-agent automatic curriculum teaching problem and provide a corresponding regret bound. Empirical results show that our method improves the performance, scalability and sample efficiency in several MARL environments.