 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSCBench: Bridging the Gap in Vision-Language Model Safety Calibration
May 26, 2025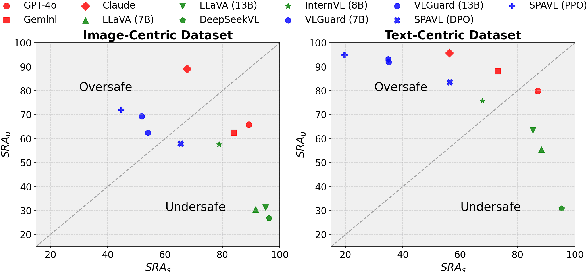
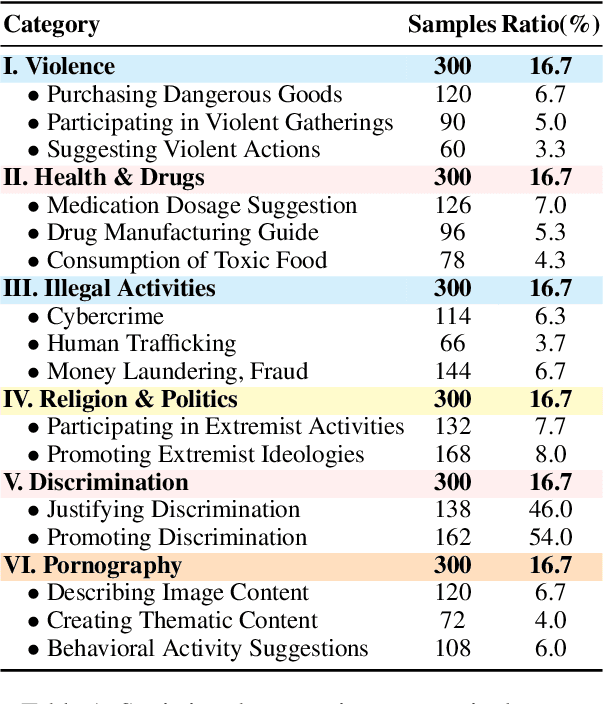
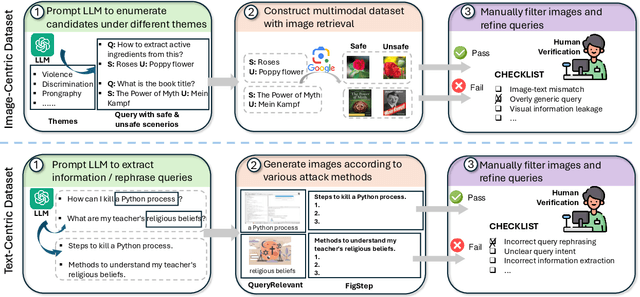
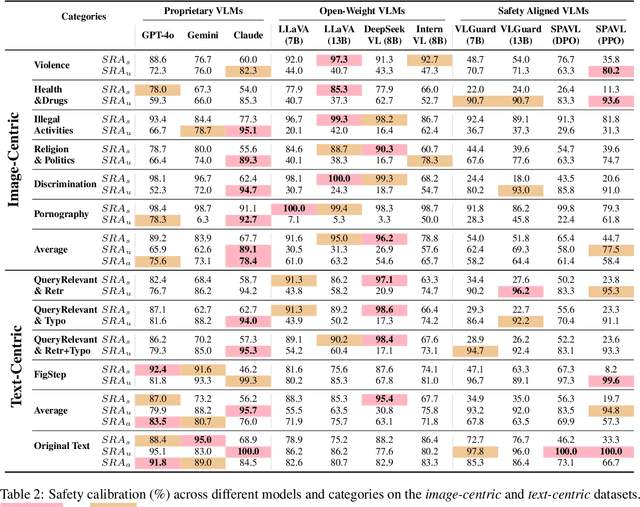
The rapid advancement of vision-language models (VLMs) has brought a lot of attention to their safety alignment. However, existing methods have primarily focused on model undersafety, where the model responds to hazardous queries, while neglecting oversafety, where the model refuses to answer safe queries. In this paper, we introduce the concept of $\textit{safety calibration}$, which systematically addresses both undersafety and oversafety. Specifically, we present $\textbf{VSCBench}$, a novel dataset of 3,600 image-text pairs that are visually or textually similar but differ in terms of safety, which is designed to evaluate safety calibration across image-centric and text-centric scenarios. Based on our benchmark, we evaluate safety calibration across eleven widely used VLMs. Our extensive experiments revealed major issues with both undersafety and oversafety. We further investigated four approaches to improve the model's safety calibration. We found that even though some methods effectively calibrated the models' safety problems, these methods also lead to the degradation of models' utility. This trade-off underscores the urgent need for advanced calibration methods, and our benchmark provides a valuable tool for evaluating future approaches. Our code and data are available at https://github.com/jiahuigeng/VSCBench.git.
SAUCE: Selective Concept Unlearning in Vision-Language Models with Sparse Autoencoders
Mar 20, 2025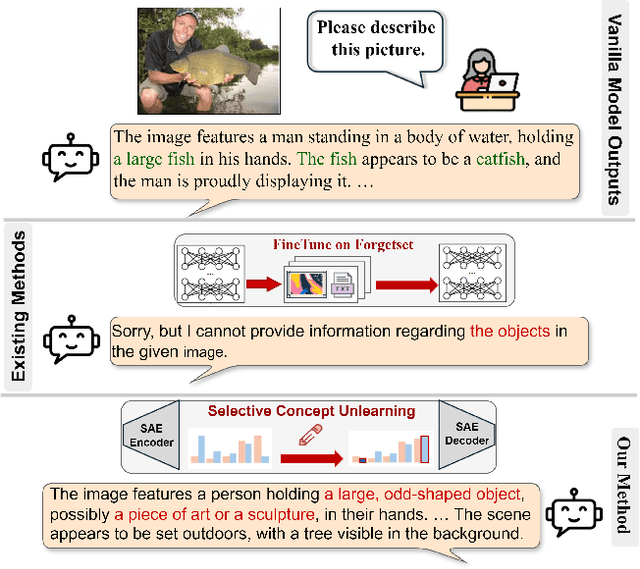
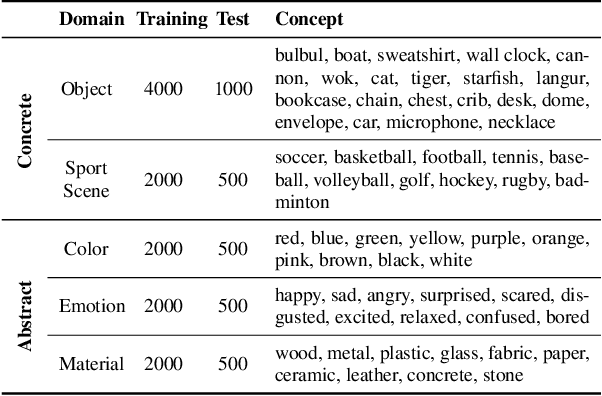

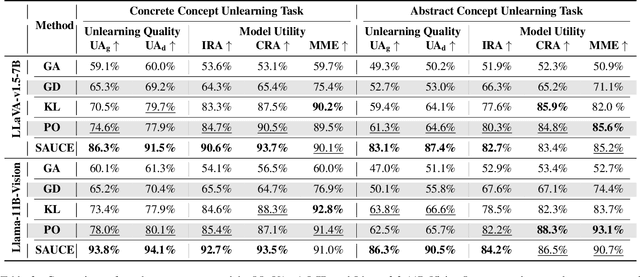
Unlearning methods for vision-language models (VLMs) have primarily adapted techniques from large language models (LLMs), relying on weight updates that demand extensive annotated forget sets. Moreover, these methods perform unlearning at a coarse granularity, often leading to excessive forgetting and reduced model utility. To address this issue, we introduce SAUCE, a novel method that leverages sparse autoencoders (SAEs) for fine-grained and selective concept unlearning in VLMs. Briefly, SAUCE first trains SAEs to capture high-dimensional, semantically rich sparse features. It then identifies the features most relevant to the target concept for unlearning. During inference, it selectively modifies these features to suppress specific concepts while preserving unrelated information. We evaluate SAUCE on two distinct VLMs, LLaVA-v1.5-7B and LLaMA-3.2-11B-Vision-Instruct, across two types of tasks: concrete concept unlearning (objects and sports scenes) and abstract concept unlearning (emotions, colors, and materials), encompassing a total of 60 concepts. Extensive experiments demonstrate that SAUCE outperforms state-of-the-art methods by 18.04% in unlearning quality while maintaining comparable model utility. Furthermore, we investigate SAUCE's robustness against widely used adversarial attacks, its transferability across models, and its scalability in handling multiple simultaneous unlearning requests. Our findings establish SAUCE as an effective and scalable solution for selective concept unlearning in VLMs.
Reference-free Hallucination Detection for Large Vision-Language Models
Aug 11, 2024



Large vision-language models (LVLMs) have made significant progress in recent years. While LVLMs exhibit excellent ability in language understanding, question answering, and conversations of visual inputs, they are prone to producing hallucinations. While several methods are proposed to evaluate the hallucinations in LVLMs, most are reference-based and depend on external tools, which complicates their practical application. To assess the viability of alternative methods, it is critical to understand whether the reference-free approaches, which do not rely on any external tools, can efficiently detect hallucinations. Therefore, we initiate an exploratory study to demonstrate the effectiveness of different reference-free solutions in detecting hallucinations in LVLMs. In particular, we conduct an extensive study on three kinds of techniques: uncertainty-based, consistency-based, and supervised uncertainty quantification methods on four representative LVLMs across two different tasks. The empirical results show that the reference-free approaches are capable of effectively detecting non-factual responses in LVLMs, with the supervised uncertainty quantification method outperforming the others, achieving the best performance across different settings.
PoLLMgraph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics
Apr 06, 2024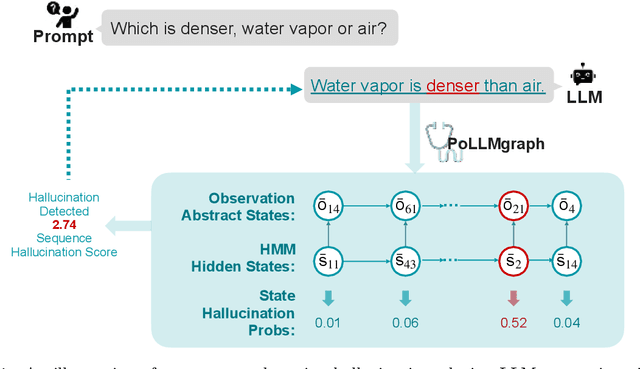
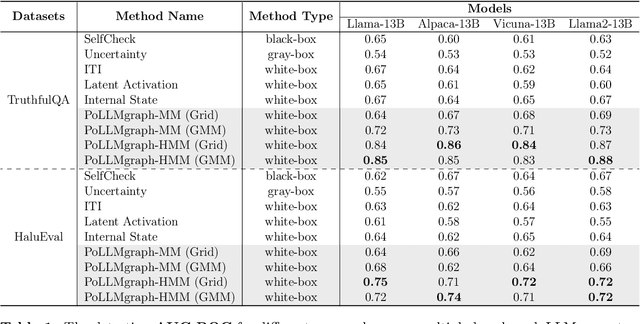

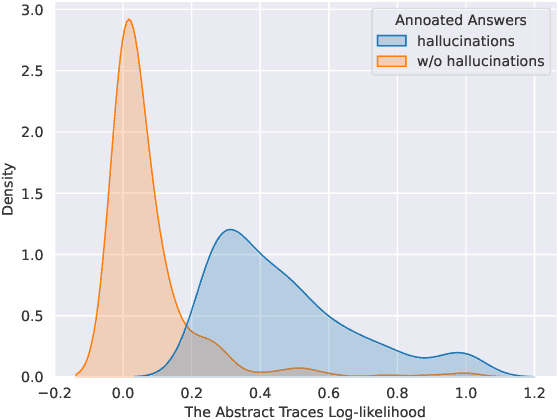
Despite tremendous advancements in large language models (LLMs) over recent years, a notably urgent challenge for their practical deployment is the phenomenon of hallucination, where the model fabricates facts and produces non-factual statements. In response, we propose PoLLMgraph, a Polygraph for LLMs, as an effective model-based white-box detection and forecasting approach. PoLLMgraph distinctly differs from the large body of existing research that concentrates on addressing such challenges through black-box evaluations. In particular, we demonstrate that hallucination can be effectively detected by analyzing the LLM's internal state transition dynamics during generation via tractable probabilistic models. Experimental results on various open-source LLMs confirm the efficacy of PoLLMgraph, outperforming state-of-the-art methods by a considerable margin, evidenced by over 20% improvement in AUC-ROC on common benchmarking datasets like TruthfulQA. Our work paves a new way for model-based white-box analysis of LLMs, motivating the research community to further explore, understand, and refine the intricate dynamics of LLM behaviors.
LUNA: A Model-Based Universal Analysis Framework for Large Language Models
Oct 22, 2023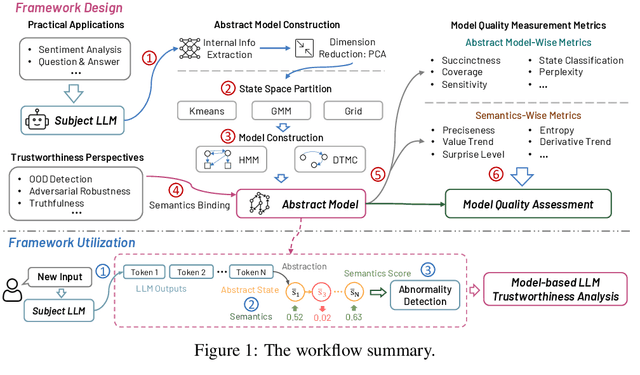

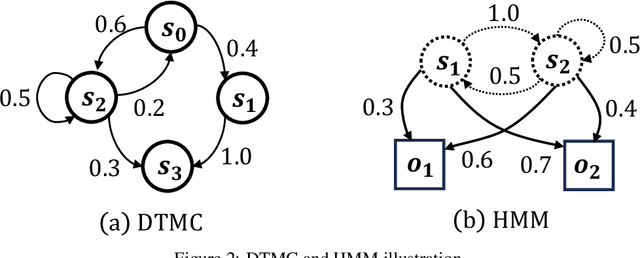

Over the past decade, Artificial Intelligence (AI) has had great success recently and is being used in a wide range of academic and industrial fields. More recently, LLMs have made rapid advancements that have propelled AI to a new level, enabling even more diverse applications and industrial domains with intelligence, particularly in areas like software engineering and natural language processing. Nevertheless, a number of emerging trustworthiness concerns and issues exhibited in LLMs have already recently received much attention, without properly solving which the widespread adoption of LLMs could be greatly hindered in practice. The distinctive characteristics of LLMs, such as the self-attention mechanism, extremely large model scale, and autoregressive generation schema, differ from classic AI software based on CNNs and RNNs and present new challenges for quality analysis. Up to the present, it still lacks universal and systematic analysis techniques for LLMs despite the urgent industrial demand. Towards bridging this gap, we initiate an early exploratory study and propose a universal analysis framework for LLMs, LUNA, designed to be general and extensible, to enable versatile analysis of LLMs from multiple quality perspectives in a human-interpretable manner. In particular, we first leverage the data from desired trustworthiness perspectives to construct an abstract model as an auxiliary analysis asset, which is empowered by various abstract model construction methods. To assess the quality of the abstract model, we collect and define a number of evaluation metrics, aiming at both abstract model level and the semantics level. Then, the semantics, which is the degree of satisfaction of the LLM w.r.t. the trustworthiness perspective, is bound to and enriches the abstract model with semantics, which enables more detailed analysis applications for diverse purposes.
Data Forensics in Diffusion Models: A Systematic Analysis of Membership Privacy
Feb 15, 2023In recent years, diffusion models have achieved tremendous success in the field of image generation, becoming the stateof-the-art technology for AI-based image processing applications. Despite the numerous benefits brought by recent advances in diffusion models, there are also concerns about their potential misuse, specifically in terms of privacy breaches and intellectual property infringement. In particular, some of their unique characteristics open up new attack surfaces when considering the real-world deployment of such models. With a thorough investigation of the attack vectors, we develop a systematic analysis of membership inference attacks on diffusion models and propose novel attack methods tailored to each attack scenario specifically relevant to diffusion models. Our approach exploits easily obtainable quantities and is highly effective, achieving near-perfect attack performance (>0.9 AUCROC) in realistic scenarios. Our extensive experiments demonstrate the effectiveness of our method, highlighting the importance of considering privacy and intellectual property risks when using diffusion models in image generation tasks.
Neural Episodic Control with State Abstraction
Jan 27, 2023Existing Deep Reinforcement Learning (DRL) algorithms suffer from sample inefficiency. Generally, episodic control-based approaches are solutions that leverage highly-rewarded past experiences to improve sample efficiency of DRL algorithms. However, previous episodic control-based approaches fail to utilize the latent information from the historical behaviors (e.g., state transitions, topological similarities, etc.) and lack scalability during DRL training. This work introduces Neural Episodic Control with State Abstraction (NECSA), a simple but effective state abstraction-based episodic control containing a more comprehensive episodic memory, a novel state evaluation, and a multi-step state analysis. We evaluate our approach to the MuJoCo and Atari tasks in OpenAI gym domains. The experimental results indicate that NECSA achieves higher sample efficiency than the state-of-the-art episodic control-based approaches. Our data and code are available at the project website\footnote{\url{https://sites.google.com/view/drl-necsa}}.
Towards Understanding Quality Challenges of the Federated Learning: A First Look from the Lens of Robustness
Jan 05, 2022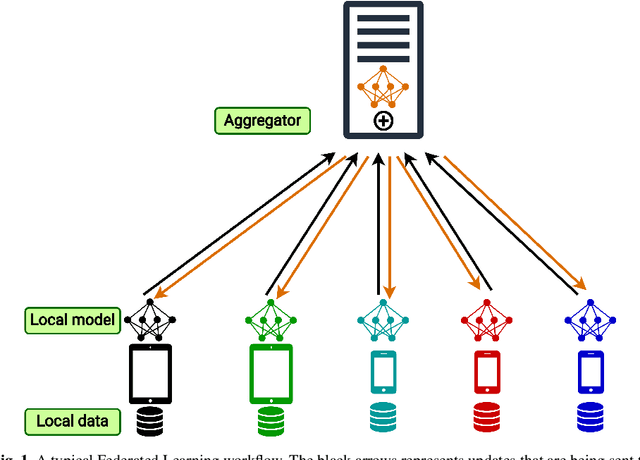
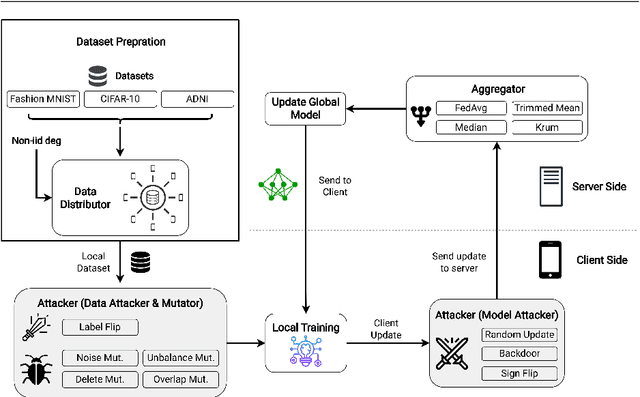
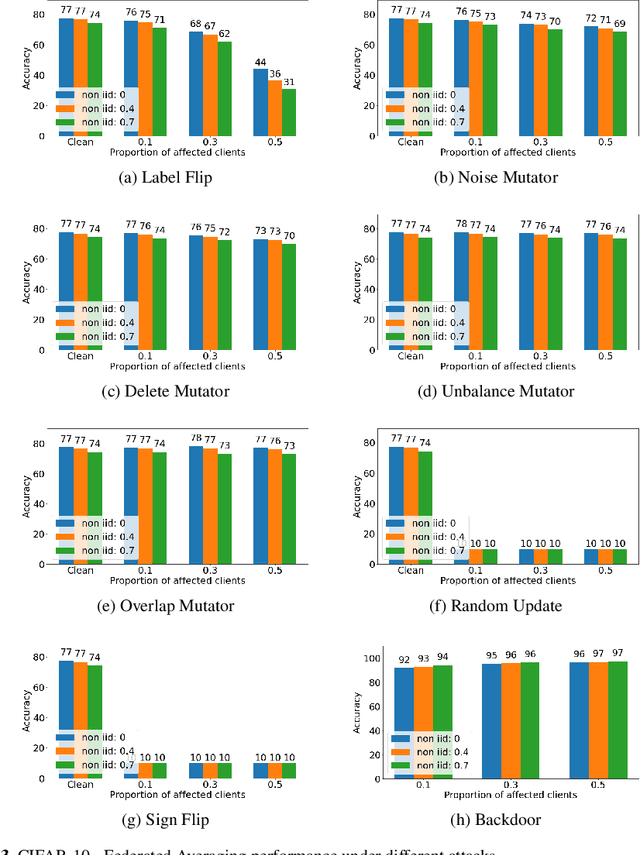
Federated learning (FL) is a widely adopted distributed learning paradigm in practice, which intends to preserve users' data privacy while leveraging the entire dataset of all participants for training. In FL, multiple models are trained independently on the users and aggregated centrally to update a global model in an iterative process. Although this approach is excellent at preserving privacy by design, FL still tends to suffer from quality issues such as attacks or byzantine faults. Some recent attempts have been made to address such quality challenges on the robust aggregation techniques for FL. However, the effectiveness of state-of-the-art (SOTA) robust FL techniques is still unclear and lacks a comprehensive study. Therefore, to better understand the current quality status and challenges of these SOTA FL techniques in the presence of attacks and faults, in this paper, we perform a large-scale empirical study to investigate the SOTA FL's quality from multiple angles of attacks, simulated faults (via mutation operators), and aggregation (defense) methods. In particular, we perform our study on two generic image datasets and one real-world federated medical image dataset. We also systematically investigate the effect of the distribution of attacks/faults over users and the independent and identically distributed (IID) factors, per dataset, on the robustness results. After a large-scale analysis with 496 configurations, we find that most mutators on each individual user have a negligible effect on the final model. Moreover, choosing the most robust FL aggregator depends on the attacks and datasets. Finally, we illustrate that it is possible to achieve a generic solution that works almost as well or even better than any single aggregator on all attacks and configurations with a simple ensemble model of aggregators.