 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUNA: A Model-Based Universal Analysis Framework for Large Language Models
Paper and Code
Oct 22, 2023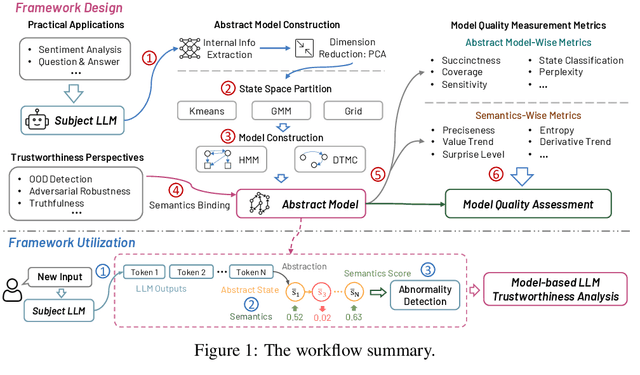

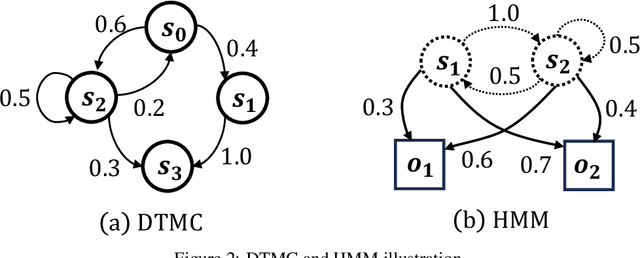

Over the past decade, Artificial Intelligence (AI) has had great success recently and is being used in a wide range of academic and industrial fields. More recently, LLMs have made rapid advancements that have propelled AI to a new level, enabling even more diverse applications and industrial domains with intelligence, particularly in areas like software engineering and natural language processing. Nevertheless, a number of emerging trustworthiness concerns and issues exhibited in LLMs have already recently received much attention, without properly solving which the widespread adoption of LLMs could be greatly hindered in practice. The distinctive characteristics of LLMs, such as the self-attention mechanism, extremely large model scale, and autoregressive generation schema, differ from classic AI software based on CNNs and RNNs and present new challenges for quality analysis. Up to the present, it still lacks universal and systematic analysis techniques for LLMs despite the urgent industrial demand. Towards bridging this gap, we initiate an early exploratory study and propose a universal analysis framework for LLMs, LUNA, designed to be general and extensible, to enable versatile analysis of LLMs from multiple quality perspectives in a human-interpretable manner. In particular, we first leverage the data from desired trustworthiness perspectives to construct an abstract model as an auxiliary analysis asset, which is empowered by various abstract model construction methods. To assess the quality of the abstract model, we collect and define a number of evaluation metrics, aiming at both abstract model level and the semantics level. Then, the semantics, which is the degree of satisfaction of the LLM w.r.t. the trustworthiness perspective, is bound to and enriches the abstract model with semantics, which enables more detailed analysis applications for diverse purposes.