 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjected Gradient Unlearning for Text-to-Image Diffusion Models: Defending Against Concept Revival Attacks
Apr 22, 2026Machine unlearning for text-to-image diffusion models aims to selectively remove undesirable concepts from pre-trained models without costly retraining. Current unlearning methods share a common weakness: erased concepts return when the model is fine-tuned on downstream data, even when that data is entirely unrelated. We adapt Projected Gradient Unlearning (PGU) from classification to the diffusion domain as a post-hoc hardening step. By constructing a Core Gradient Space (CGS) from the retain concept activations and projecting gradient updates into its orthogonal complement, PGU ensures that subsequent fine-tuning cannot undo the achieved erasure. Applied on top of existing methods (ESD, UCE, Receler), the approach eliminates revival for style concepts and substantially delays it for object concepts, running in roughly 6 minutes versus the ~2 hours required by Meta-Unlearning. PGU and Meta-Unlearning turn out to be complementary: which performs better depends on how the concept is encoded, and retain concept selection should follow visual feature similarity rather than semantic grouping.
KineVLA: Towards Kinematics-Aware Vision-Language-Action Models with Bi-Level Action Decomposition
Mar 18, 2026In this paper, we introduce a novel kinematics-rich vision-language-action (VLA) task, in which language commands densely encode diverse kinematic attributes (such as direction, trajectory, orientation, and relative displacement) from initiation through completion, at key moments, unlike existing action instructions that capture kinematics only coarsely or partially, thereby supporting fine-grained and personalized manipulation. In this setting, where task goals remain invariant while execution trajectories must adapt to instruction-level kinematic specifications. To address this challenge, we propose KineVLA, a vision-language-action framework that explicitly decouples goal-level invariance from kinematics-level variability through a bi-level action representation and bi-level reasoning tokens to serve as explicit, supervised intermediate variables that align language and action. To support this task, we construct the kinematics-aware VLA datasets spanning both simulation and real-world robotic platforms, featuring instruction-level kinematic variations and bi-level annotations. Extensive experiments on LIBERO and a Realman-75 robot demonstrate that KineVLA consistently outperforms strong VLA baselines on kinematics-sensitive benchmarks, achieving more precise, controllable, and generalizable manipulation behaviors.
Zero-Shot Off-Policy Learning
Feb 02, 2026Off-policy learning methods seek to derive an optimal policy directly from a fixed dataset of prior interactions. This objective presents significant challenges, primarily due to the inherent distributional shift and value function overestimation bias. These issues become even more noticeable in zero-shot reinforcement learning, where an agent trained on reward-free data must adapt to new tasks at test time without additional training. In this work, we address the off-policy problem in a zero-shot setting by discovering a theoretical connection of successor measures to stationary density ratios. Using this insight, our algorithm can infer optimal importance sampling ratios, effectively performing a stationary distribution correction with an optimal policy for any task on the fly. We benchmark our method in motion tracking tasks on SMPL Humanoid, continuous control on ExoRL, and for the long-horizon OGBench tasks. Our technique seamlessly integrates into forward-backward representation frameworks and enables fast-adaptation to new tasks in a training-free regime. More broadly, this work bridges off-policy learning and zero-shot adaptation, offering benefits to both research areas.
AdaptPrompt: Parameter-Efficient Adaptation of VLMs for Generalizable Deepfake Detection
Dec 19, 2025
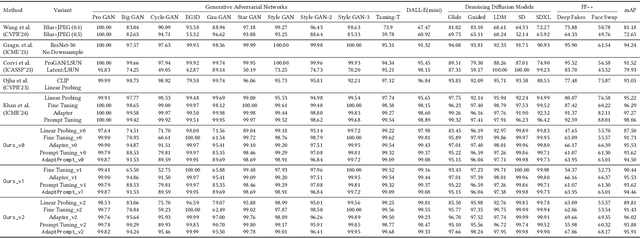
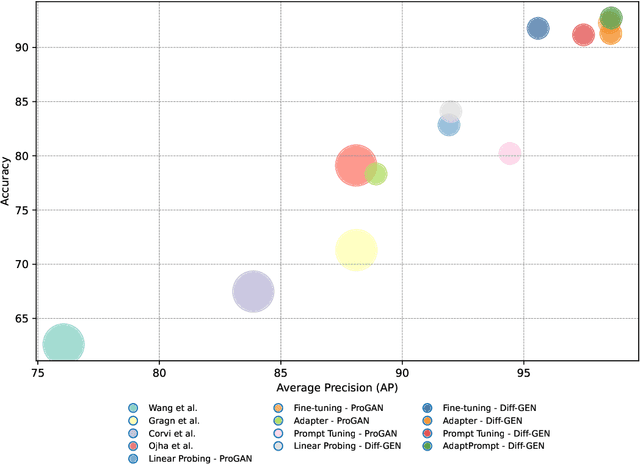
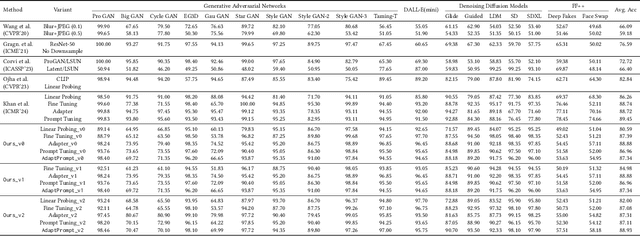
Recent advances in image generation have led to the widespread availability of highly realistic synthetic media, increasing the difficulty of reliable deepfake detection. A key challenge is generalization, as detectors trained on a narrow class of generators often fail when confronted with unseen models. In this work, we address the pressing need for generalizable detection by leveraging large vision-language models, specifically CLIP, to identify synthetic content across diverse generative techniques. First, we introduce Diff-Gen, a large-scale benchmark dataset comprising 100k diffusion-generated fakes that capture broad spectral artifacts unlike traditional GAN datasets. Models trained on Diff-Gen demonstrate stronger cross-domain generalization, particularly on previously unseen image generators. Second, we propose AdaptPrompt, a parameter-efficient transfer learning framework that jointly learns task-specific textual prompts and visual adapters while keeping the CLIP backbone frozen. We further show via layer ablation that pruning the final transformer block of the vision encoder enhances the retention of high-frequency generative artifacts, significantly boosting detection accuracy. Our evaluation spans 25 challenging test sets, covering synthetic content generated by GANs, diffusion models, and commercial tools, establishing a new state-of-the-art in both standard and cross-domain scenarios. We further demonstrate the framework's versatility through few-shot generalization (using as few as 320 images) and source attribution, enabling the precise identification of generator architectures in closed-set settings.
REMONI: An Autonomous System Integrating Wearables and Multimodal Large Language Models for Enhanced Remote Health Monitoring
Oct 24, 2025With the widespread adoption of wearable devices in our daily lives, the demand and appeal for remote patient monitoring have significantly increased. Most research in this field has concentrated on collecting sensor data, visualizing it, and analyzing it to detect anomalies in specific diseases such as diabetes, heart disease and depression. However, this domain has a notable gap in the aspect of human-machine interaction. This paper proposes REMONI, an autonomous REmote health MONItoring system that integrates multimodal large language models (MLLMs), the Internet of Things (IoT), and wearable devices. The system automatically and continuously collects vital signs, accelerometer data from a special wearable (such as a smartwatch), and visual data in patient video clips collected from cameras. This data is processed by an anomaly detection module, which includes a fall detection model and algorithms to identify and alert caregivers of the patient's emergency conditions. A distinctive feature of our proposed system is the natural language processing component, developed with MLLMs capable of detecting and recognizing a patient's activity and emotion while responding to healthcare worker's inquiries. Additionally, prompt engineering is employed to integrate all patient information seamlessly. As a result, doctors and nurses can access real-time vital signs and the patient's current state and mood by interacting with an intelligent agent through a user-friendly web application. Our experiments demonstrate that our system is implementable and scalable for real-life scenarios, potentially reducing the workload of medical professionals and healthcare costs. A full-fledged prototype illustrating the functionalities of the system has been developed and being tested to demonstrate the robustness of its various capabilities.
Expert or not? assessing data quality in offline reinforcement learning
Oct 14, 2025Offline reinforcement learning (RL) learns exclusively from static datasets, without further interaction with the environment. In practice, such datasets vary widely in quality, often mixing expert, suboptimal, and even random trajectories. The choice of algorithm therefore depends on dataset fidelity. Behavior cloning can suffice on high-quality data, whereas mixed- or low-quality data typically benefits from offline RL methods that stitch useful behavior across trajectories. Yet in the wild it is difficult to assess dataset quality a priori because the data's provenance and skill composition are unknown. We address the problem of estimating offline dataset quality without training an agent. We study a spectrum of proxies from simple cumulative rewards to learned value based estimators, and introduce the Bellman Wasserstein distance (BWD), a value aware optimal transport score that measures how dissimilar a dataset's behavioral policy is from a random reference policy. BWD is computed from a behavioral critic and a state conditional OT formulation, requiring no environment interaction or full policy optimization. Across D4RL MuJoCo tasks, BWD strongly correlates with an oracle performance score that aggregates multiple offline RL algorithms, enabling efficient prediction of how well standard agents will perform on a given dataset. Beyond prediction, integrating BWD as a regularizer during policy optimization explicitly pushes the learned policy away from random behavior and improves returns. These results indicate that value aware, distributional signals such as BWD are practical tools for triaging offline RL datasets and policy optimization.
MDD-Net: Multimodal Depression Detection through Mutual Transformer
Aug 11, 2025Depression is a major mental health condition that severely impacts the emotional and physical well-being of individuals. The simple nature of data collection from social media platforms has attracted significant interest in properly utilizing this information for mental health research. A Multimodal Depression Detection Network (MDD-Net), utilizing acoustic and visual data obtained from social media networks, is proposed in this work where mutual transformers are exploited to efficiently extract and fuse multimodal features for efficient depression detection. The MDD-Net consists of four core modules: an acoustic feature extraction module for retrieving relevant acoustic attributes, a visual feature extraction module for extracting significant high-level patterns, a mutual transformer for computing the correlations among the generated features and fusing these features from multiple modalities, and a detection layer for detecting depression using the fused feature representations. The extensive experiments are performed using the multimodal D-Vlog dataset, and the findings reveal that the developed multimodal depression detection network surpasses the state-of-the-art by up to 17.37% for F1-Score, demonstrating the greater performance of the proposed system. The source code is accessible at https://github.com/rezwanh001/Multimodal-Depression-Detection.
FaceAnonyMixer: Cancelable Faces via Identity Consistent Latent Space Mixing
Aug 07, 2025Advancements in face recognition (FR) technologies have amplified privacy concerns, necessitating methods that protect identity while maintaining recognition utility. Existing face anonymization methods typically focus on obscuring identity but fail to meet the requirements of biometric template protection, including revocability, unlinkability, and irreversibility. We propose FaceAnonyMixer, a cancelable face generation framework that leverages the latent space of a pre-trained generative model to synthesize privacy-preserving face images. The core idea of FaceAnonyMixer is to irreversibly mix the latent code of a real face image with a synthetic code derived from a revocable key. The mixed latent code is further refined through a carefully designed multi-objective loss to satisfy all cancelable biometric requirements. FaceAnonyMixer is capable of generating high-quality cancelable faces that can be directly matched using existing FR systems without requiring any modifications. Extensive experiments on benchmark datasets demonstrate that FaceAnonyMixer delivers superior recognition accuracy while providing significantly stronger privacy protection, achieving over an 11% gain on commercial API compared to recent cancelable biometric methods. Code is available at: https://github.com/talha-alam/faceanonymixer.
GNN-ViTCap: GNN-Enhanced Multiple Instance Learning with Vision Transformers for Whole Slide Image Classification and Captioning
Jul 09, 2025Microscopic assessment of histopathology images is vital for accurate cancer diagnosis and treatment. Whole Slide Image (WSI) classification and captioning have become crucial tasks in computer-aided pathology. However, microscopic WSI face challenges such as redundant patches and unknown patch positions due to subjective pathologist captures. Moreover, generating automatic pathology captions remains a significant challenge. To address these issues, we introduce a novel GNN-ViTCap framework for classification and caption generation from histopathological microscopic images. First, a visual feature extractor generates patch embeddings. Redundant patches are then removed by dynamically clustering these embeddings using deep embedded clustering and selecting representative patches via a scalar dot attention mechanism. We build a graph by connecting each node to its nearest neighbors in the similarity matrix and apply a graph neural network to capture both local and global context. The aggregated image embeddings are projected into the language model's input space through a linear layer and combined with caption tokens to fine-tune a large language model. We validate our method on the BreakHis and PatchGastric datasets. GNN-ViTCap achieves an F1 score of 0.934 and an AUC of 0.963 for classification, along with a BLEU-4 score of 0.811 and a METEOR score of 0.569 for captioning. Experimental results demonstrate that GNN-ViTCap outperforms state of the art approaches, offering a reliable and efficient solution for microscopy based patient diagnosis.
Hierarchical Instruction-aware Embodied Visual Tracking
May 27, 2025User-Centric Embodied Visual Tracking (UC-EVT) presents a novel challenge for reinforcement learning-based models due to the substantial gap between high-level user instructions and low-level agent actions. While recent advancements in language models (e.g., LLMs, VLMs, VLAs) have improved instruction comprehension, these models face critical limitations in either inference speed (LLMs, VLMs) or generalizability (VLAs) for UC-EVT tasks. To address these challenges, we propose \textbf{Hierarchical Instruction-aware Embodied Visual Tracking (HIEVT)} agent, which bridges instruction comprehension and action generation using \textit{spatial goals} as intermediaries. HIEVT first introduces \textit{LLM-based Semantic-Spatial Goal Aligner} to translate diverse human instructions into spatial goals that directly annotate the desired spatial position. Then the \textit{RL-based Adaptive Goal-Aligned Policy}, a general offline policy, enables the tracker to position the target as specified by the spatial goal. To benchmark UC-EVT tasks, we collect over ten million trajectories for training and evaluate across one seen environment and nine unseen challenging environments. Extensive experiments and real-world deployments demonstrate the robustness and generalizability of HIEVT across diverse environments, varying target dynamics, and complex instruction combinations. The complete project is available at https://sites.google.com/view/hievt.