 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNFDI4DS Shared Tasks for Scholarly Document Processing
Sep 26, 2025Shared tasks are powerful tools for advancing research through community-based standardised evaluation. As such, they play a key role in promoting findable, accessible, interoperable, and reusable (FAIR), as well as transparent and reproducible research practices. This paper presents an updated overview of twelve shared tasks developed and hosted under the German National Research Data Infrastructure for Data Science and Artificial Intelligence (NFDI4DS) consortium, covering a diverse set of challenges in scholarly document processing. Hosted at leading venues, the tasks foster methodological innovations and contribute open-access datasets, models, and tools for the broader research community, which are integrated into the consortium's research data infrastructure.
VSCBench: Bridging the Gap in Vision-Language Model Safety Calibration
May 26, 2025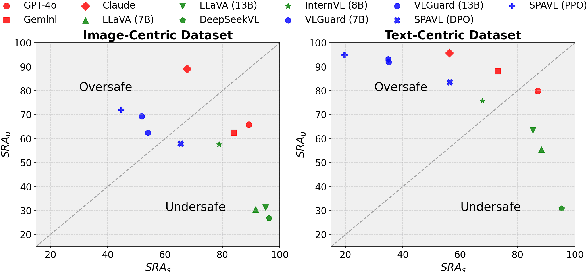
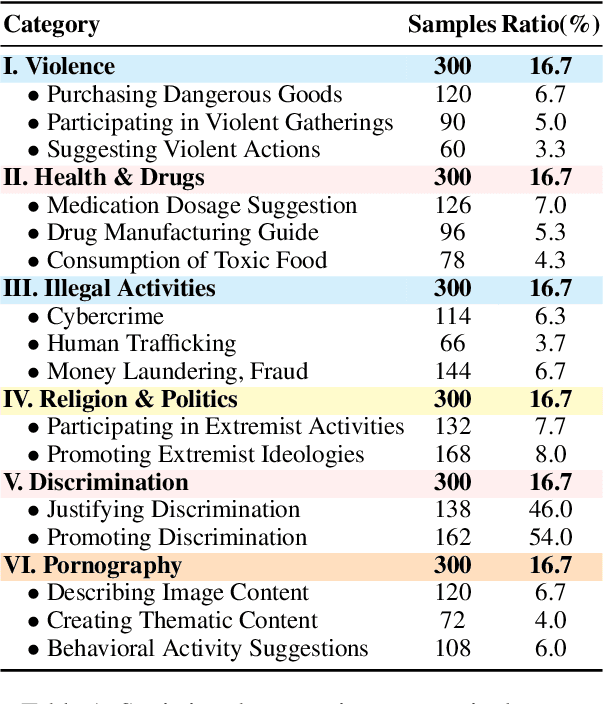
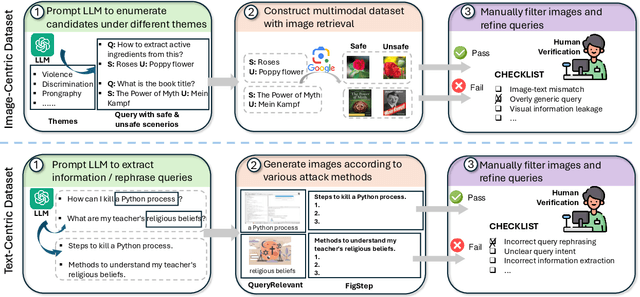
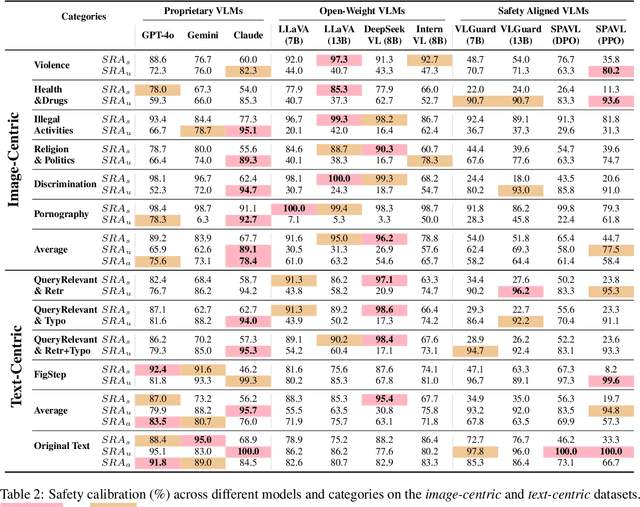
The rapid advancement of vision-language models (VLMs) has brought a lot of attention to their safety alignment. However, existing methods have primarily focused on model undersafety, where the model responds to hazardous queries, while neglecting oversafety, where the model refuses to answer safe queries. In this paper, we introduce the concept of $\textit{safety calibration}$, which systematically addresses both undersafety and oversafety. Specifically, we present $\textbf{VSCBench}$, a novel dataset of 3,600 image-text pairs that are visually or textually similar but differ in terms of safety, which is designed to evaluate safety calibration across image-centric and text-centric scenarios. Based on our benchmark, we evaluate safety calibration across eleven widely used VLMs. Our extensive experiments revealed major issues with both undersafety and oversafety. We further investigated four approaches to improve the model's safety calibration. We found that even though some methods effectively calibrated the models' safety problems, these methods also lead to the degradation of models' utility. This trade-off underscores the urgent need for advanced calibration methods, and our benchmark provides a valuable tool for evaluating future approaches. Our code and data are available at https://github.com/jiahuigeng/VSCBench.git.
NFDI4DSO: Towards a BFO Compliant Ontology for Data Science
Aug 16, 2024


The NFDI4DataScience (NFDI4DS) project aims to enhance the accessibility and interoperability of research data within Data Science (DS) and Artificial Intelligence (AI) by connecting digital artifacts and ensuring they adhere to FAIR (Findable, Accessible, Interoperable, and Reusable) principles. To this end, this poster introduces the NFDI4DS Ontology, which describes resources in DS and AI and models the structure of the NFDI4DS consortium. Built upon the NFDICore ontology and mapped to the Basic Formal Ontology (BFO), this ontology serves as the foundation for the NFDI4DS knowledge graph currently under development.
PoLLMgraph: Unraveling Hallucinations in Large Language Models via State Transition Dynamics
Apr 06, 2024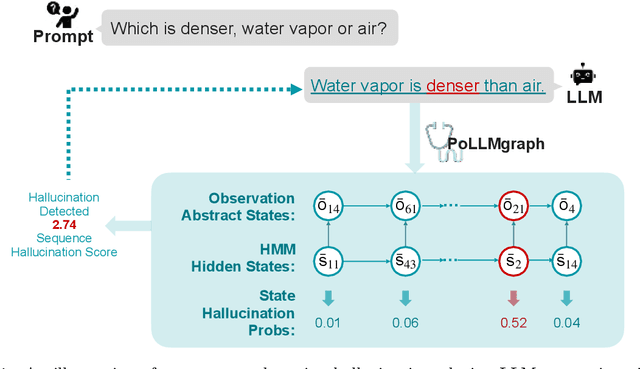
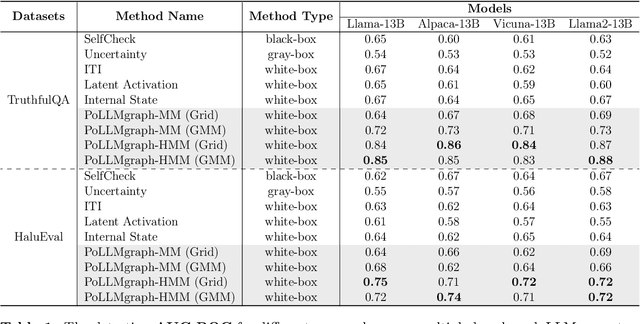

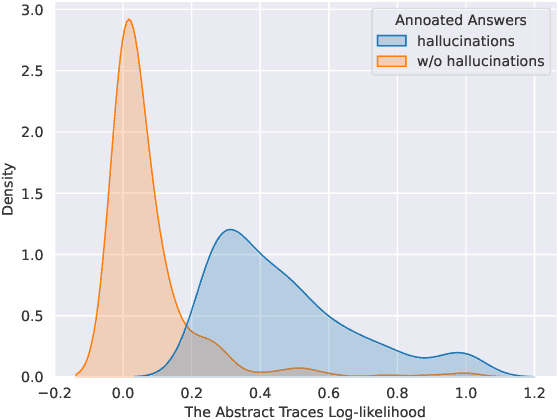
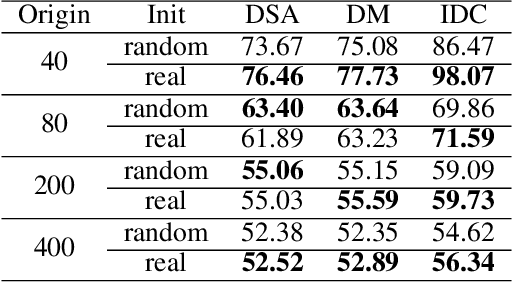
Despite tremendous advancements in large language models (LLMs) over recent years, a notably urgent challenge for their practical deployment is the phenomenon of hallucination, where the model fabricates facts and produces non-factual statements. In response, we propose PoLLMgraph, a Polygraph for LLMs, as an effective model-based white-box detection and forecasting approach. PoLLMgraph distinctly differs from the large body of existing research that concentrates on addressing such challenges through black-box evaluations. In particular, we demonstrate that hallucination can be effectively detected by analyzing the LLM's internal state transition dynamics during generation via tractable probabilistic models. Experimental results on various open-source LLMs confirm the efficacy of PoLLMgraph, outperforming state-of-the-art methods by a considerable margin, evidenced by over 20% improvement in AUC-ROC on common benchmarking datasets like TruthfulQA. Our work paves a new way for model-based white-box analysis of LLMs, motivating the research community to further explore, understand, and refine the intricate dynamics of LLM behaviors.
A Comprehensive Study on Dataset Distillation: Performance, Privacy, Robustness and Fairness
May 05, 2023
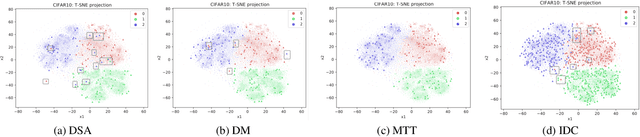
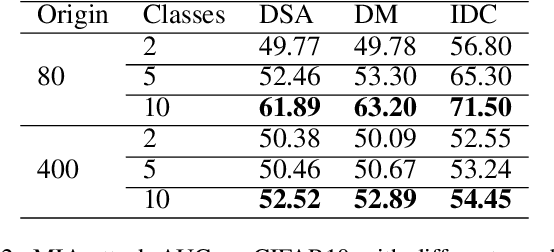
The aim of dataset distillation is to encode the rich features of an original dataset into a tiny dataset. It is a promising approach to accelerate neural network training and related studies. Different approaches have been proposed to improve the informativeness and generalization performance of distilled images. However, no work has comprehensively analyzed this technique from a security perspective and there is a lack of systematic understanding of potential risks. In this work, we conduct extensive experiments to evaluate current state-of-the-art dataset distillation methods. We successfully use membership inference attacks to show that privacy risks still remain. Our work also demonstrates that dataset distillation can cause varying degrees of impact on model robustness and amplify model unfairness across classes when making predictions. This work offers a large-scale benchmarking framework for dataset distillation evaluation.
A Survey on Dataset Distillation: Approaches, Applications and Future Directions
May 03, 2023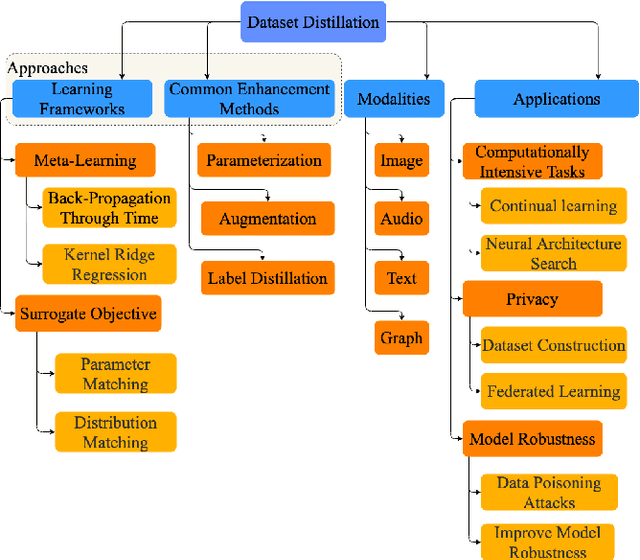
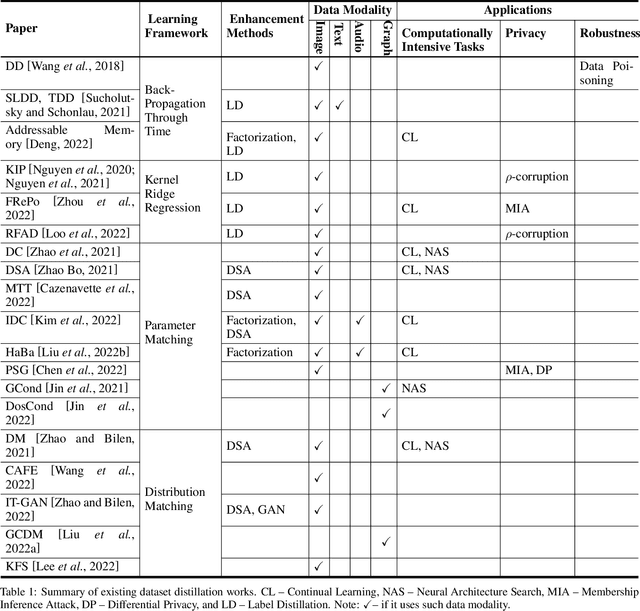
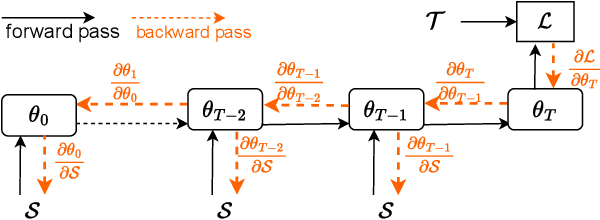

Dataset distillation is attracting more attention in machine learning as training sets continue to grow and the cost of training state-of-the-art models becomes increasingly high. By synthesizing datasets with high information density, dataset distillation offers a range of potential applications, including support for continual learning, neural architecture search, and privacy protection. Despite recent advances, we lack a holistic understanding of the approaches and applications. Our survey aims to bridge this gap by first proposing a taxonomy of dataset distillation, characterizing existing approaches, and then systematically reviewing the data modalities, and related applications. In addition, we summarize the challenges and discuss future directions for this field of research.